RAG重排序器与两阶段检索
在本文中,我们将学习一种通常最容易和最快实现的方法来解决性能不佳的RAG管道问题——重排序器(Reranker)。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
检索增强生成(RAG) 是一个包罗万象的术语。它承诺了世界,但在开发了一个RAG管道后,我们中的许多人可能会疑惑为什么它没有达到我们的预期效果。
就像大多数工具一样,RAG易于使用但难以精通。事实是,RAG不仅仅是将文档放入向量数据库并在其顶部添加一个LLM。虽然这可以工作,但并不总是如此。
在本文中,我们将学习一种通常最容易和最快实现的方法来解决性能不佳的RAG管道问题——我们将学习关于重排序器(Reranker)的知识。
1、召回率 vs. 上下文窗口
在深入解决方案之前,让我们先谈谈问题。在RAG中,我们需要对许多文本文档进行语义搜索——这些文档可能从数万到数十亿不等。
为了确保大规模下的快速搜索时间,我们通常使用向量搜索——也就是说,我们将文本转换为向量,将它们全部放入向量空间,并使用余弦相似度之类的相似性度量来比较查询向量与其接近程度。
为了使向量搜索起作用,我们需要向量。这些向量本质上是将某些文本背后的“意义”压缩成(通常是)768或1536维的向量。由于我们将这些信息压缩成单一向量,因此会有一些信息丢失。
正因为这种信息丢失,我们经常发现前三个(例如)向量搜索文档会遗漏相关信息。不幸的是,检索可能会返回低于我们的top_k截止点的相关信息。
如果我们认为较低位置的相关信息会帮助我们的LLM形成更好的响应,该怎么办?最简单的办法是增加我们返回的文档数量(增加top_k),并将所有文档传递给LLM。
这里衡量的指标是召回率——意思是“我们检索到的相关文档有多少”。召回率不考虑检索到的总文档数量——所以我们可以通过返回一切来完美地提高召回率。

不幸的是,我们不能返回一切。LLMs对我们可以传递给它们的文本量有限制——我们称之为上下文窗口。一些LLMs有巨大的上下文窗口,比如Anthropic的Claude,其上下文窗口为100K令牌[1]。有了这个,我们可以容纳许多页的文本——所以我们能否返回许多文档(不是全部)并“填充”上下文窗口以提高召回率?
再次,不行。我们不能使用上下文填充,因为这会降低LLM的召回率表现——请注意,这是LLM召回率,与我们迄今为止讨论的检索召回率不同。

LLM召回率是指LLM从其上下文窗口内的文本中找到信息的能力。研究表明,随着我们在上下文窗口中放置更多标记,LLM召回率会下降[2]。当我们填充上下文窗口时,LLM也更不可能遵循指令——因此上下文填充是一个糟糕的想法。
我们可以增加向量DB返回的文档数量来提高检索召回率,但我们不能将这些文档传递给我们的LLM而不损害LLM召回率。
解决这个问题的办法是通过检索大量文档来最大化检索召回率,然后通过最小化传递给LLM的文档数量来最大化LLM召回率。要做到这一点,我们需要重新排列检索到的文档,并保留最相关的文档给我们的LLM——为此,我们使用重排序器。
2、重排序器的力量
重排序模型——也称为交叉编码器——是一种模型,它在给定查询和文档对的情况下,会输出一个相似度分数。我们使用这个分数按相关性重新排列文档。

搜索工程师长期以来一直在两阶段检索系统中使用重排序器。在这些两阶段系统中,第一阶段模型(嵌入模型/检索器)从更大的数据集中检索一组相关文档。然后,第二阶段模型(重排序器)用于重新排序第一阶段模型检索到的文档。
我们使用两个阶段是因为从大型数据集中检索少量文档比重新排序大量文档要快得多——我们会很快讨论为什么这样——但简而言之,重排序器很慢,而检索器快。
3、为什么使用重排序器?
如果重排序器慢这么多,为什么要使用它们呢?答案是重排序器比嵌入模型准确得多。
双编码器准确性较差的直觉是,双编码器必须将文档的所有可能含义压缩成一个向量——这意味着我们失去了信息。此外,双编码器在查询时没有上下文,因为我们直到收到查询之前都不知道查询(我们创建嵌入是在用户查询之前的时间)。
另一方面,重排序器可以直接将原始信息输入到大型transformer计算中,意味着信息损失较少。由于我们在用户查询时运行重排序器,我们还可以根据特定的用户查询分析文档的意义——而不是试图产生通用的、平均的意义。
重排序器避免了双编码器的信息损失——但它们带来了不同的代价——时间。

在使用向量搜索时结合双编码器模型,我们将所有的重型transformer计算提前到初始向量创建时——这意味着当用户查询我们的系统时,我们已经创建了向量,所以我们只需要:
- 运行一次transformer计算以创建查询向量。
- 使用余弦相似度(或其他轻量级度量)比较查询向量和文档向量。
对于重排序器,我们不会预先计算任何内容。相反,我们将查询和单个其他文档输入到transformer中,运行整个推理步骤,并输出一个单一的相似度分数。
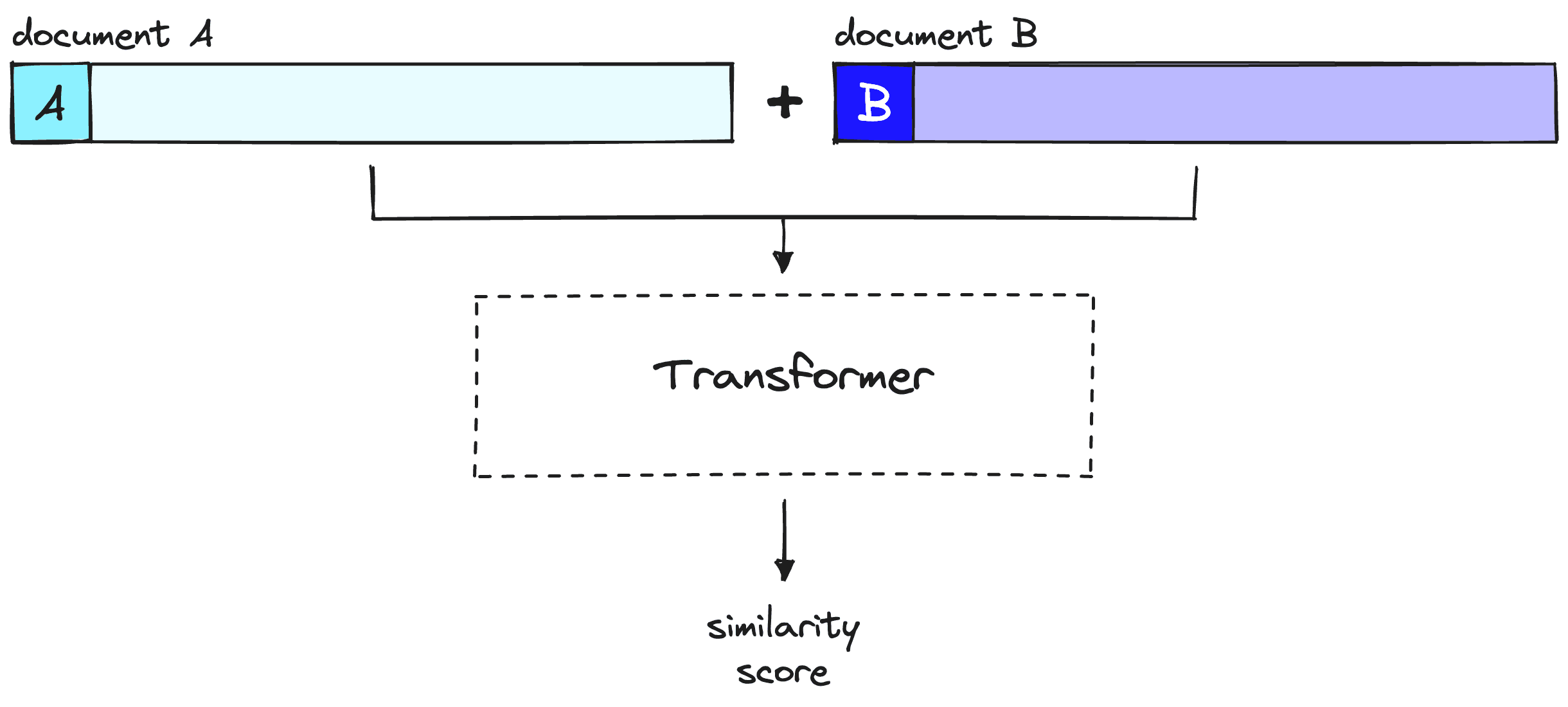
重排序器考虑查询和文档,在整个推理步骤中生成一个单一的相似度分数。注意,这里的文档A相当于我们的查询。
对于包含40M记录的情况,如果我们在V100 GPU上使用像BERT这样的小重排序模型——我们需要等待超过50小时才能返回一个查询结果[3]。我们可以用编码器模型和向量搜索在<100毫秒内完成相同的任务。
4、使用重排序器实现两阶段检索
现在我们理解了两阶段检索背后的想法和原因,让我们看看如何实现它(你可以跟着这个笔记本一起操作)。首先,我们将设置必要的库:
!pip install -qU \
datasets==2.14.5 \
"pinecone[grpc]"==5.1.0
4.1 数据准备
在设置检索管道之前,我们需要数据来检索!我们将使用Hugging Face Datasets中的jamescalam/ai-arxiv-chunked数据集。这个数据集包含了超过400篇关于ML、NLP和LLMs的ArXiv论文——包括Llama 2、GPTQ和GPT-4论文。
from datasets import load_dataset
data = load_dataset("jamescalam/ai-arxiv-chunked", split="train")
data
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/153M [00:00<?, ?B/s]
Extracting data files: 0%| | 0/1 [00:00<?, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset({
features: ['doi', 'chunk-id', 'chunk', 'id', 'title', 'summary', 'source', 'authors', 'categories', 'comment', 'journal_ref', 'primary_category', 'published', 'updated', 'references'],
num_rows: 41584
})数据集中包含 41.5K 条预分块记录。每条记录大约为 1-2 段文本,并且包括来自原始论文的其他元数据。以下是一个示例:
data[0]
{'doi': '1910.01108',
'chunk-id': '0',
'chunk': 'DistilBERT, a distilled version of BERT: smaller,\nfaster, cheaper and lighter\nVictor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF\nHugging Face\n{victor,lysandre,julien,thomas}@huggingface.co\nAbstract\nAs Transfer Learning from large-scale pre-trained models becomes more prevalent\nin Natural Language Processing (NLP), operating these large models in on-theedge and/or under constrained computational training or inference budgets remains\nchallenging. In this work, we propose a method to pre-train a smaller generalpurpose language representation model, called DistilBERT, which can then be finetuned with good performances on a wide range of tasks like its larger counterparts.\nWhile most prior work investigated the use of distillation for building task-specific\nmodels, we leverage knowledge distillation during the pre-training phase and show\nthat it is possible to reduce the size of a BERT model by 40%, while retaining 97%\nof its language understanding capabilities and being 60% faster. To leverage the\ninductive biases learned by larger models during pre-training, we introduce a triple\nloss combining language modeling, distillation and cosine-distance losses. Our\nsmaller, faster and lighter model is cheaper to pre-train and we demonstrate its',
'id': '1910.01108',
'title': 'DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter',
'summary': 'As Transfer Learning from large-scale pre-trained models becomes more\nprevalent in Natural Language Processing (NLP), operating these large models in\non-the-edge and/or under constrained computational training or inference\nbudgets remains challenging. In this work, we propose a method to pre-train a\nsmaller general-purpose language representation model, called DistilBERT, which\ncan then be fine-tuned with good performances on a wide range of tasks like its\nlarger counterparts. While most prior work investigated the use of distillation\nfor building task-specific models, we leverage knowledge distillation during\nthe pre-training phase and show that it is possible to reduce the size of a\nBERT model by 40%, while retaining 97% of its language understanding\ncapabilities and being 60% faster. To leverage the inductive biases learned by\nlarger models during pre-training, we introduce a triple loss combining\nlanguage modeling, distillation and cosine-distance losses. Our smaller, faster\nand lighter model is cheaper to pre-train and we demonstrate its capabilities\nfor on-device computations in a proof-of-concept experiment and a comparative\non-device study.',
'source': 'http://arxiv.org/pdf/1910.01108',
'authors': ['Victor Sanh',
'Lysandre Debut',
'Julien Chaumond',
'Thomas Wolf'],
'categories': ['cs.CL'],
'comment': 'February 2020 - Revision: fix bug in evaluation metrics, updated\n metrics, argumentation unchanged. 5 pages, 1 figure, 4 tables. Accepted at\n the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing\n - NeurIPS 2019',
'journal_ref': None,
'primary_category': 'cs.CL',
'published': '20191002',
'updated': '20200301',
'references': [{'id': '1910.01108'}]}我们将把这些数据输入到 Pinecone 中,因此让我们重新格式化数据集,使其在以后嵌入和索引过程中更适合 Pinecone。该格式将包含 id、text(我们将对其进行嵌入)以及 metadata。在这个例子中,我们不会使用元数据,但如果将来想要进行元数据过滤,它可能会很有帮助。
data = data.map(lambda x: {
"id": f'{x["id"]}-{x["chunk-id"]}',
"text": x["chunk"],
"metadata": {
"title": x["title"],
"url": x["source"],
"primary_category": x["primary_category"],
"published": x["published"],
"updated": x["updated"],
"text": x["chunk"],
}
})
# 删除不需要的列
data = data.remove_columns([
"title", "summary", "source",
"authors", "categories", "comment",
"journal_ref", "primary_category",
"published", "updated", "references",
"doi", "chunk-id",
"chunk"
])
data
Map: 0%| | 0/41584 [00:00<?, ? examples/s]
Dataset({
features: ['id', 'text', 'metadata'],
num_rows: 41584
})4.2 嵌入和索引
为了将所有内容存储到向量数据库中,我们需要用嵌入/双编码器模型对所有内容进行编码。我们将使用通过 Pinecone Inference 提供的开源 multilingual-e5-large 模型。我们需要一个Pinecone API 密钥来通过客户端进行身份验证:
from pinecone.grpc import PineconeGRPC
# 从 app.pinecone.io 获取 API 密钥
api_key = "PINECONE_API_KEY"
embed_model = "multilingual-e5-large"
# 配置客户端
pc = PineconeGRPC(api_key=api_key)
现在,我们创建我们的向量数据库来存储我们的向量。我们将 dimension 设置为 E5 大型模型的维度(1024),并使用与 E5 兼容的 metric——即 cosine。
import time
index_name = "rerankers"
existing_indexes = [
index_info["name"] for index_info in pc.list_indexes()
]
# 检查索引是否已经存在(如果是第一次运行,则不应存在)
if index_name not in existing_indexes:
# 如果不存在,创建索引
pc.create_index(
index_name,
dimension=1024, # e5-large 的维度
metric='cosine',
spec=spec
)
# 等待索引初始化完成
while not pc.describe_index(index_name).status['ready']:
time.sleep(1)
# 连接到索引
index = pc.Index(index_name)
time.sleep(1)
# 查看索引统计信息
index.describe_index_stats()
我们创建了一个新函数 embed,用于处理使用模型的嵌入。在函数内部,我们还包含了对速率限制错误的处理。
from pinecone_plugins.inference.core.client.exceptions import PineconeApiException
def embed(batch: list[str]) -> list[float]:
# 创建嵌入(指数回退以避免 RateLimitError)
for j in range(5): # 最大 5 次重试
try:
res = pc.inference.embed(
model=embed_model,
inputs=batch,
parameters={
"input_type": "passage", # 对于文档/上下文/块
"truncate": "END", # 截断到最大长度
}
)
passed = True
except PineconeApiException:
time.sleep(2**j) # 在重试前等待 2^j 秒
print("重试中...")
if not passed:
raise RuntimeError("创建嵌入失败。")
# 获取嵌入
embeds = [x["values"] for x in res.data]
return embeds
我们现在准备好开始使用 E5 嵌入模型填充索引了,如下所示:
from tqdm.auto import tqdm
batch_size = 96 # 每次创建和插入的嵌入数量
for i in tqdm(range(0, len(data), batch_size)):
passed = False
# 找到批次结束
i_end = min(len(data), i+batch_size)
# 创建批次
batch = data[i:i_end]
embeds = embed(batch["text"])
to_upsert = list(zip(batch["id"], embeds, batch["metadata"]))
# 插入到 Pinecone
index.upsert(vectors=to_upsert)
我们的索引现在已填充完毕,准备查询!
4.3 不带重排序的检索
在重排序之前,让我们看看不带重排序的结果如何。我们将定义一个名为 get_docs 的函数,仅返回第一阶段检索的文档:
def get_docs(query: str, top_k: int) -> list[str]:
# 编码查询
res = pc.inference.embed(
model=embed_model,
inputs=[query],
parameters={
"input_type": "query", # 对于查询
"truncate": "END", # 截断到最大长度
}
)
xq = res.data[0]["values"]
# 查询 Pinecone 索引
res = index.query(vector=xq, top_k=top_k, include_metadata=True)
# 获取文档文本
docs = [{
"id": str(i),
"text": x["metadata"]['text']
} for i, x in enumerate(res["matches"])]
return docs
让我们询问关于强化学习与人类反馈(RLHF)——这是 ChatGPT 发布时突然性能提升背后的一种流行微调方法。
query = "can you explain why we would want to do rlhf?"
docs = get_docs(query, top_k=25)
print("\n---\n".join(docs.keys()[:3])) # print the first 3 docswhichmodels areprompted toexplain theirreasoningwhen givena complexproblem, inorder toincrease
the likelihood that their final answer is correct.
RLHF has emerged as a powerful strategy for fine-tuning Large Language Models, enabling significant
improvements in their performance (Christiano et al., 2017). The method, first showcased by Stiennon et al.
(2020) in the context of text-summarization tasks, has since been extended to a range of other applications.
In this paradigm, models are fine-tuned based on feedback from human users, thus iteratively aligning the
models’ responses more closely with human expectations and preferences.
Ouyang et al. (2022) demonstrates that a combination of instruction fine-tuning and RLHF can help fix
issues with factuality, toxicity, and helpfulness that cannot be remedied by simply scaling up LLMs. Bai
et al. (2022b) partially automates this fine-tuning-plus-RLHF approach by replacing the human-labeled
fine-tuningdatawiththemodel’sownself-critiquesandrevisions,andbyreplacinghumanraterswitha
---
We examine the influence of the amount of RLHF training for two reasons. First, RLHF [13, 57] is an
increasingly popular technique for reducing harmful behaviors in large language models [3, 21, 52]. Some of
these models are already deployed [52], so we believe the impact of RLHF deserves further scrutiny. Second,
previous work shows that the amount of RLHF training can significantly change metrics on a wide range of
personality, political preference, and harm evaluations for a given model size [41]. As a result, it is important
to control for the amount of RLHF training in the analysis of our experiments.
3.2 Experiments
3.2.1 Overview
We test the effect of natural language instructions on two related but distinct moral phenomena: stereotyping
and discrimination. Stereotyping involves the use of generalizations about groups in ways that are often
harmful or undesirable.4To measure stereotyping, we use two well-known stereotyping benchmarks, BBQ
[40] (§3.2.2) and Windogender [49] (§3.2.3). For discrimination, we focus on whether models make disparate
decisions about individuals based on protected characteristics that should have no relevance to the outcome.5
To measure discrimination, we construct a new benchmark to test for the impact of race in a law school course
---
model to estimate the eventual performance of a larger RL policy. The slopes of these lines also
explain how RLHF training can produce such large effective gains in model size, and for example it
explains why the RLHF and context-distilled lines in Figure 1 are roughly parallel.
• One can ask a subtle, perhaps ill-defined question about RLHF training – is it teaching the model
new skills or simply focusing the model on generating a sub-distribution of existing behaviors . We
might attempt to make this distinction sharp by associating the latter class of behaviors with the
region where RL reward remains linear inp
KL.
• To make some bolder guesses – perhaps the linear relation actually provides an upper bound on RL
reward, as a function of the KL. One might also attempt to extend the relation further by replacingp
KLwith a geodesic length in the Fisher geometry.
By making RL learning more predictable and by identifying new quantitative categories of behavior, we
might hope to detect unexpected behaviors emerging during RL training.
4.4 Tension Between Helpfulness and Harmlessness in RLHF Training
Here we discuss a problem we encountered during RLHF training. At an earlier stage of this project, we
found that many RLHF policies were very frequently reproducing the same exaggerated responses to all
remotely sensitive questions (e.g. recommending users seek therapy and professional help whenever they
...我们在这里得到了合理的性能——特别是相关的文本片段:
| Document | Chunk |
|---|---|
| 0 | "enabling significant improvements in their performance" |
| 0 | "iteratively aligning the models' responses more closely with human expectations and preferences" |
| 0 | "instruction fine-tuning and RLHF can help fix issues with factuality, toxicity, and helpfulness" |
| 1 | "increasingly popular technique for reducing harmful behaviors in large language models" |
剩余的文档和文本涵盖了RLHF,但没有回答我们特定的问题:"为什么我们要做RLHF?"。
4.4 重新排名响应
我们将使用Pinecone的重新排名端点来进行此操作。我们使用相同的Pinecone客户端,但现在点击inference.rerank如下所示:
rerank_name = "bge-reranker-v2-m3"
rerank_docs = pc.inference.rerank(
model=rerank_name,
query=query,
documents=docs,
top_n=25,
return_documents=True
)
这返回一个RerankResult对象:
RerankResult(
model='bge-reranker-v2-m3',
data=[
{ index=1, score=0.9071478,
document={id="1", text="RLHF Response ! I..."} },
{ index=9, score=0.6954414,
document={id="9", text="team, instead of ..."} },
... (21 more documents) ...,
{ index=17, score=0.13420755,
document={id="17", text="helpfulness and h..."} },
{ index=23, score=0.11417085,
document={id="23", text="responses respons..."} }
],
usage={'rerank_units': 1}
)
我们通过rerank_docs.data[0]["document"]["text"]访问文档内容。
让我们创建一个函数,以便快速比较原始结果与重新排名的结果。
def compare(query: str, top_k: int, top_n: int):
# 首先获取向量搜索结果
top_k_docs = get_docs(query, top_k=top_k)
# 重新排名
top_n_docs = pc.inference.rerank(
model=rerank_name,
query=query,
documents=docs,
top_n=top_n,
return_documents=True
)
original_docs = []
reranked_docs = []
# 比较顺序变化
print("[ORIGINAL] -> [NEW]")
for i, doc in enumerate(top_n_docs.data):
print(str(doc.index)+"\t->\t"+str(i))
if i != doc.index:
reranked_docs.append(f"[{doc.index}]\n"+doc["document"]["text"])
original_docs.append(f"[{i}]\n"+top_k_docs[i]['text'])
else:
reranked_docs.append(doc["document"]["text"])
original_docs.append(None)
# 打印结果
for orig, rerank in zip(original_docs, reranked_docs):
if not orig:
print(f"SAME:\n{rerank}\n\n---\n")
else:
print(f"ORIGINAL:\n{orig}\n\nRERANKED:\n{rerank}\n\n---\n")
我们从我们的RLHF查询开始。这次,我们进行一个更标准的检索-重新排名过程,检索25个文档(top_k=25),并重新排名到前三个文档(top_n=3)。
compare(query, 25, 3)
0 -> 0
1 -> 23
2 -> 14
ORIGINAL:
[1]
We examine the influence of the amount of RLHF training for two reasons. First, RLHF [13, 57] is an
increasingly popular technique for reducing harmful behaviors in large language models [3, 21, 52]. Some of
these models are already deployed [52], so we believe the impact of RLHF deserves further scrutiny. Second,
previous work shows that the amount of RLHF training can significantly change metrics on a wide range of
personality, political preference, and harm evaluations for a given model size [41]. As a result, it is important
to control for the amount of RLHF training in the analysis of our experiments.
3.2 Experiments
3.2.1 Overview
We test the effect of natural language instructions on two related but distinct moral phenomena: stereotyping
and discrimination. Stereotyping involves the use of generalizations about groups in ways that are often
harmful or undesirable.4To measure stereotyping, we use two well-known stereotyping benchmarks, BBQ
[40] (§3.2.2) and Windogender [49] (§3.2.3). For discrimination, we focus on whether models make disparate
decisions about individuals based on protected characteristics that should have no relevance to the outcome.5
To measure discrimination, we construct a new benchmark to test for the impact of race in a law school course
RERANKED:
[23]
We have shown that it’s possible to use reinforcement learning from human feedback to train language models
that act as helpful and harmless assistants. Our RLHF training also improves honesty, though we expect
other techniques can do better still. As in other recent works associated with aligning large language models
[Stiennon et al., 2020, Thoppilan et al., 2022, Ouyang et al., 2022, Nakano et al., 2021, Menick et al., 2022],
RLHF improves helpfulness and harmlessness by a huge margin when compared to simply scaling models
up.
Our alignment interventions actually enhance the capabilities of large models, and can easily be combined
with training for specialized skills (such as coding or summarization) without any degradation in alignment
or performance. Models with less than about 10B parameters behave differently, paying an ‘alignment tax’ on
their capabilities. This provides an example where models near the state-of-the-art may have been necessary
to derive the right lessons from alignment research.
The overall picture we seem to find – that large models can learn a wide variety of skills, including alignment, in a mutually compatible way – does not seem very surprising. Behaving in an aligned fashion is just
another capability, and many works have shown that larger models are more capable [Kaplan et al., 2020,
---
ORIGINAL:
[2]
model to estimate the eventual performance of a larger RL policy. The slopes of these lines also
explain how RLHF training can produce such large effective gains in model size, and for example it
explains why the RLHF and context-distilled lines in Figure 1 are roughly parallel.
• One can ask a subtle, perhaps ill-defined question about RLHF training – is it teaching the model
new skills or simply focusing the model on generating a sub-distribution of existing behaviors . We
might attempt to make this distinction sharp by associating the latter class of behaviors with the
region where RL reward remains linear inp
KL.
• To make some bolder guesses – perhaps the linear relation actually provides an upper bound on RL
reward, as a function of the KL. One might also attempt to extend the relation further by replacingp
KLwith a geodesic length in the Fisher geometry.
By making RL learning more predictable and by identifying new quantitative categories of behavior, we
might hope to detect unexpected behaviors emerging during RL training.
4.4 Tension Between Helpfulness and Harmlessness in RLHF Training
Here we discuss a problem we encountered during RLHF training. At an earlier stage of this project, we
found that many RLHF policies were very frequently reproducing the same exaggerated responses to all
remotely sensitive questions (e.g. recommending users seek therapy and professional help whenever they
RERANKED:
[14]
the model outputs safe responses, they are often more detailed than what the average annotator writes.
Therefore, after gathering only a few thousand supervised demonstrations, we switched entirely to RLHF to
teachthemodelhowtowritemorenuancedresponses. ComprehensivetuningwithRLHFhastheadded
benefit that it may make the model more robust to jailbreak attempts (Bai et al., 2022a).
WeconductRLHFbyfirstcollectinghumanpreferencedataforsafetysimilartoSection3.2.2: annotators
writeapromptthattheybelievecanelicitunsafebehavior,andthencomparemultiplemodelresponsesto
theprompts,selectingtheresponsethatissafestaccordingtoasetofguidelines. Wethenusethehuman
preference data to train a safety reward model (see Section 3.2.2), and also reuse the adversarial prompts to
sample from the model during the RLHF stage.
BetterLong-TailSafetyRobustnesswithoutHurtingHelpfulness Safetyisinherentlyalong-tailproblem,
wherethe challengecomesfrom asmallnumber ofveryspecific cases. Weinvestigatetheimpact ofSafety
---
查看这些内容时,我们已经从文档1中删除了一个相关的片段,并且从文档2中没有删除任何相关片段——以下是一些替换的有关片段:
| Original Position | Rerank Position | Chunk |
|---|---|---|
| 23 | 1 | "train language models that act as helpful and harmless assistants" |
| 23 | 1 | "RLHF training also improves honesty" |
| 23 | 1 | "RLHF improves helpfulness and harmlessness by a huge margin" |
| 23 | 1 | "enhance the capabilities of large models" |
| 14 | 2 | "the model outputs safe responses" |
| 14 | 2 | "often more detailed than what the average annotator writes" |
| 14 | 2 | "RLHF to reach the model how to write more nuanced responses" |
| 14 | 2 | "make the model more robust to jailbreak attempts" |
重新排名后,我们有了更多的相关信息。自然,这可以显著提高RAG的性能。这意味着我们在最大化相关信息的同时最小化噪声输入到我们的LLM中。
5、结束语
重新排序是大幅提高检索增强生成(RAG)或任何其他基于检索的管道中的召回性能的最简单方法之一。
我们探讨了为什么重新排序器可以提供如此好的性能比其嵌入模型的对应物——以及两阶段检索系统如何让我们取两者之长,从而在大规模搜索的同时保持高质量的性能。
原文链接:Rerankers and Two-Stage Retrieval
汇智网翻译整理,转载请标明出处
