Ray:现代AI应用的分布式框架
Ray 是一个起源于伯克利大学的开源分布式计算框架,用于简单地生产和扩展 Python 机器学习工作负载。
2016 年,学生和研究人员在伯克利崛起实验室开展了一个课堂项目,以扩展分布式神经网络训练和强化学习。
这催生了论文《Ray:新兴人工智能应用的分布式框架》。
如今,Ray 是一个开源分布式计算框架,用于简单地生产和扩展 Python ML 工作负载。
它解决了分布式 ML 中的三个关键挑战。
- 消除计算约束:远程访问几乎无限的计算
- 容错:自动将失败的任务重新路由到集群中的其他机器
- 状态管理:在任务之间共享数据并跨数据进行协调
但在深入探讨之前,让我们先了解一下为什么我们需要 Ray。
1、硬件危机
随着 LLM 和 GenAI 的繁荣,计算的需求和供应之间的差距越来越大。
让我们看看下面的图表。
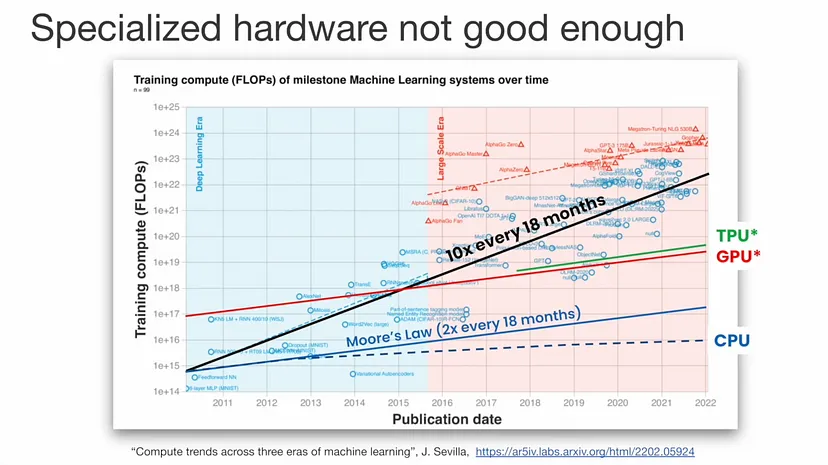
我们发现,训练 ML 系统的计算需求每 18 个月增长 10 倍。
训练 SOTA 模型与单核性能之间存在巨大差距。尽管专用硬件提供了令人印象深刻的性能提升,但仍无法满足计算需求,而且这种差距只会呈指数级增长。
即使模型大小停止增长,专用硬件也需要几十年才能赶上。
现在最好的解决方案是分配 AI 工作负载。
但这也带来了挑战。
2、AI 应用程序的挑战
构建 AI 应用程序需要开发人员将数据提取、预处理、训练、微调、预测和服务等工作负载拼接在一起。
这很有挑战性,因为每个工作负载都需要不同的系统,每个系统都有自己的 API、语义和约束。
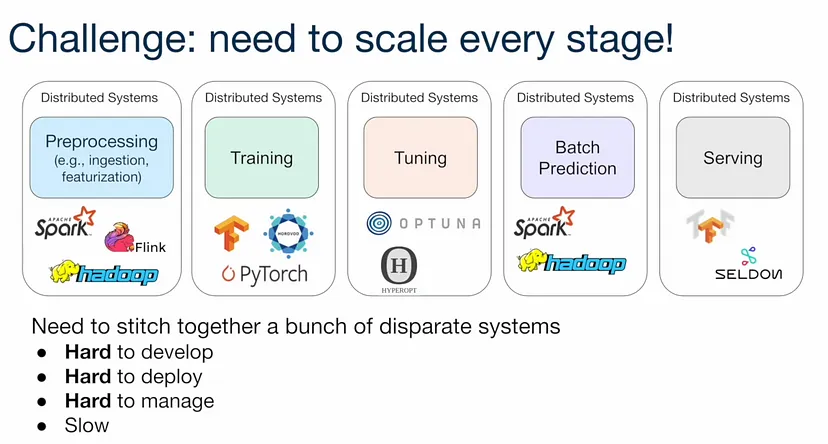
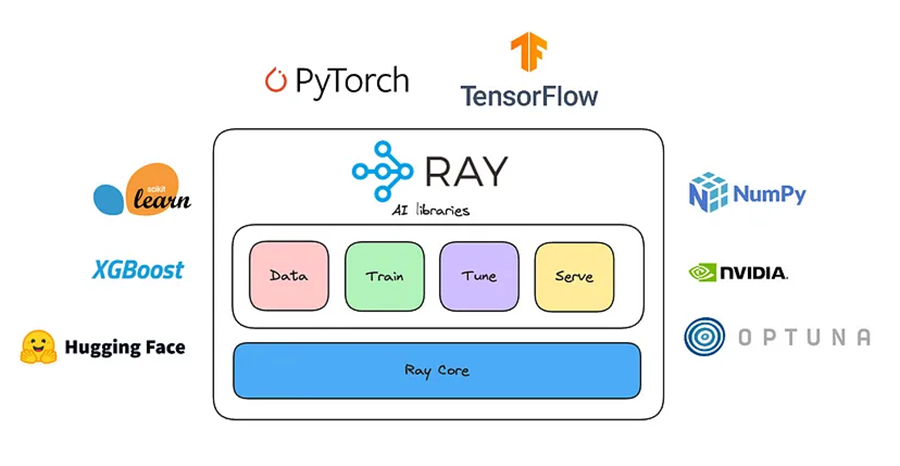
使用 Ray,你将拥有一个系统来支持所有这些工作负载:
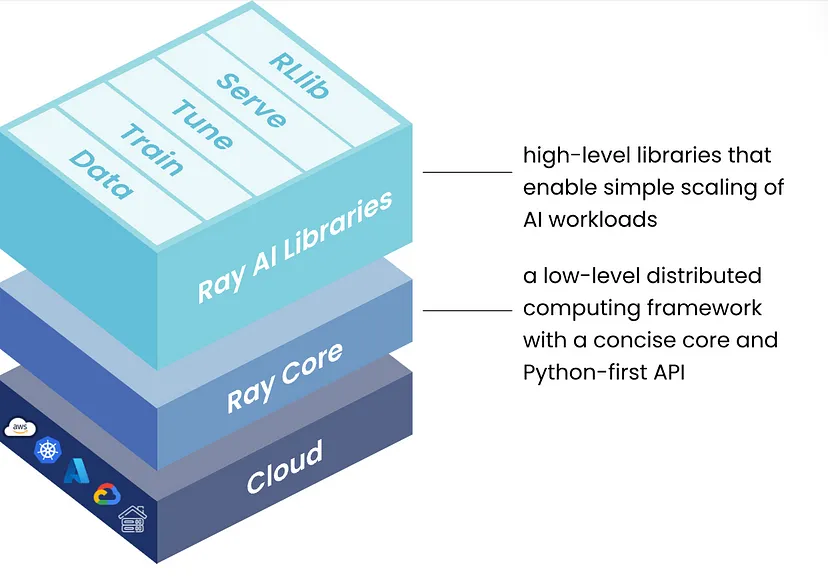
Ray 的五个原生库中的每一个都分发一个特定的 ML 任务:
- 数据:可扩展、与框架无关的数据加载和转换,涵盖训练、调整和预测。
- 训练:具有容错能力的分布式多节点和多核模型训练,可与流行的训练库集成。
- 调整:可扩展的超参数调整,以优化模型性能。
- 服务:可扩展且可编程的服务,用于部署模型进行在线推理,并具有可选的微批处理以提高性能。
- RLlib:可扩展的分布式强化学习工作负载。
3、公司如何使用 Ray
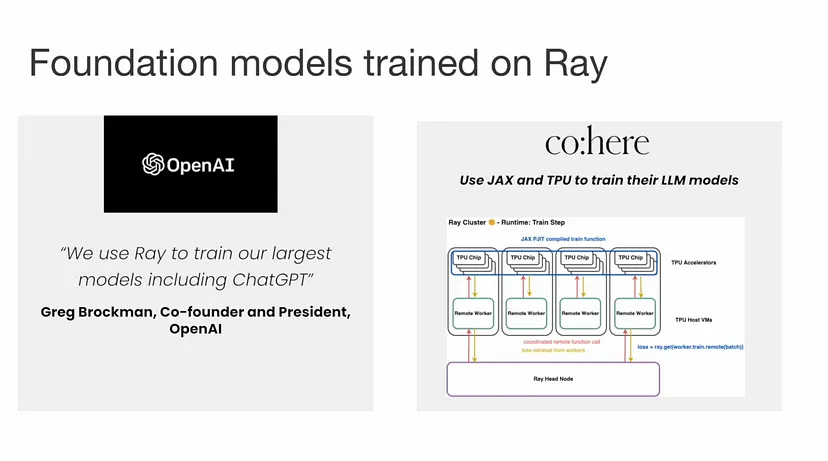
OpenAI 使用 Ray 来协调 ChatGPT 的训练。
Cohere 使用 Ray 以及 PyTorch、JAX 和 TPU 来大规模训练他们的 LLM。
下面是 Alpa 的图像,它使用 Ray 来安排 GPU 进行分布式训练。
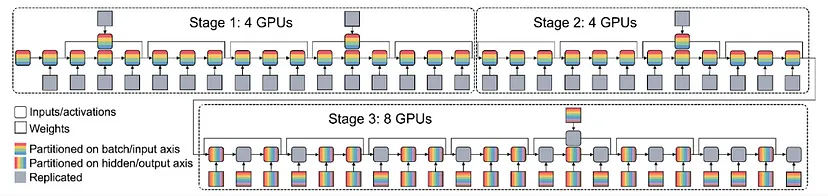
Ray 解决了生成模型分布式训练的两个最常见挑战:
- 如何有效地将模型划分到多个加速器?
- 如何设置训练以容忍可抢占实例上的故障?
Shopify、Spotify、Pinterest 和 Roblox 等公司都利用 Ray 来扩展其 ML 基础设施。
Shopify 在其 Merlin 平台中使用 Ray 来简化从原型设计到生产的 ML 工作流程,利用 Ray Train 和 Tune 进行分布式训练和超参数调整。
Spotify 使用 Ray 进行并行模型训练和调整以优化其推荐系统,而 Pinterest 使用 Ray 进行高效的数据处理和可扩展的基础设施管理。
在 Roblox,Ray 促进了跨混合云环境的大规模 AI 推理,从而实现了强大、可扩展的 ML 解决方案
4、Ray 的核心
Ray遵循极简原则,Ray 的核心 API 仅有 6 个调用:
ray.init()
@ray.remote
def big_function():
...
futures = slow_function.remote() # invoke
ray.get(futures) # return an object
ray.put() # store object in object store
ray.wait() # get objects that are ready
ray.shutdown()以下是 Python Counter 类成为异步函数的示例:

5、尝试使用 Ray
在了解了 Ray 的功能后,我决定尝试一下。
假设我们有这个函数 is_prime,它可以计算所有素数(最多 n 个)的总和。
def is_prime(n):
if n < 2:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
def sum_primes(limit):
return sum(num for num in range(2, limit) if is_prime(num))让我们测试普通 Python 的 1000 万以内的和,并执行 8 次此计算:
%%time
# Sequential execution
n_calculations = 8
limit = 10_000_000
sequential_results = [sum_primes(limit) for _ in range(n_calculations)]
# CPU times: user 12min 31s, sys: 7.56 s, total: 12min 39s
# Wall time: 12min 58s这总共花了 13 分钟!
让我们看看 Ray可以多大程度地加快速度。
%%time
# Parallel execution
futures = [sum_primes.remote(limit) for _ in range(n_calculations)]
parallel_results = ray.get(futures)
# CPU times: user 477 ms, sys: 366 ms, total: 843 ms
# Wall time: 4min 2s这是 3 倍的改进!
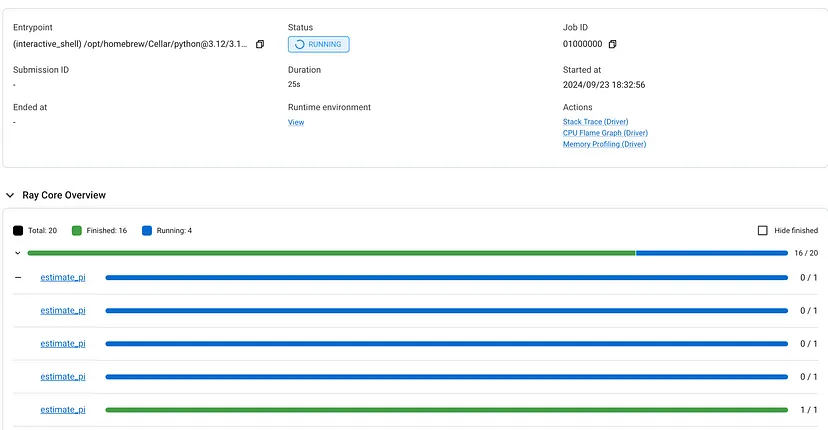
如果单击仪表板,你可以看到作业的进度。
我刚刚开始使用 Ray。请继续关注我下一篇关于使用 Ray Data 计算嵌入的文章!
汇智网翻译整理,转载请标明出处
