强化学习新手指南
如果你曾经对机器如何学习玩视频游戏、驾驶自动驾驶汽车或优化商业策略感到着迷,那强化学习就是解锁这些可能性的关键。

强化学习 (RL) 已成为人工智能中最令人兴奋和最强大的分支之一。从让 AlphaGo 击败围棋世界冠军到训练机器人行走和操纵物体,RL 正在彻底改变机器学习决策的方式。与传统的监督学习(模型从标记数据中学习)不同,RL 代理通过反复试验进行学习,就像人类从经验中学习一样。
本博客将带你深入了解 RL 的基础知识。我们将探索:
- 什么是强化学习,以及它与其他 AI 技术有何不同
- RL 系统的核心组件,包括代理、环境和奖励
- RL 算法的工作原理,从策略学习到价值估计
- RL 在游戏、机器人、医疗保健和金融领域的实际应用
- RL 研究的挑战和未来方向
如果你曾经对机器如何学习玩视频游戏、驾驶自动驾驶汽车或优化商业策略感到着迷,那么 RL 就是解锁这些可能性的关键。无论你是初学者还是 AI 爱好者,本指南都将为你提供 RL 的坚实基础及其对 AI 未来的潜在影响。让我们开始吧!
1、什么是强化学习?
强化学习 (RL) 是机器学习的一个分支,其中代理通过与环境交互来学习做出决策。与监督学习(模型从标记数据中学习)不同,RL 代理通过经验学习,根据其行为获得奖励或惩罚。
RL 的核心是反复试验的方法——代理探索不同的动作,观察其结果,并逐渐完善其策略,以随着时间的推移最大化累积奖励。这个过程模仿了人类和动物通过强化学习的方式。
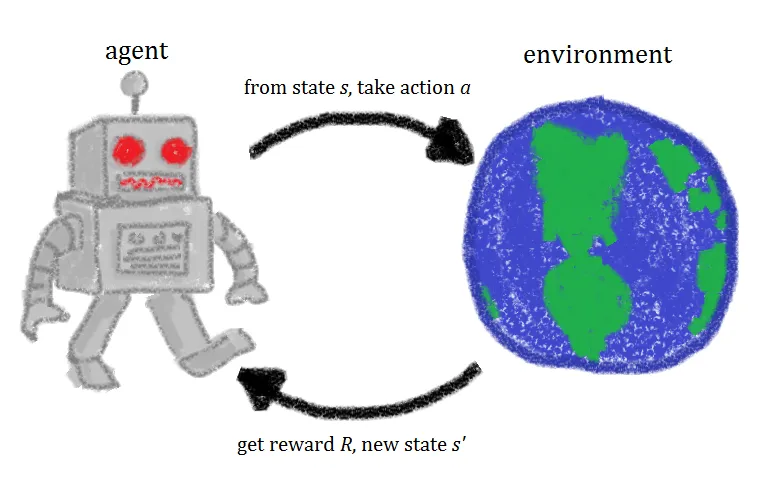
RL 的主要特征:
- 通过交互学习——代理不断与环境交互,采取行动并接收反馈。
- 顺序决策——每个动作都会影响未来的决策,这使得 RL 不同于传统的机器学习方法。
- 以目标为导向的行为——代理的驱动力是最大化长期奖励,而不是优化个人行为。
- 没有明确的监督——与监督学习不同,RL 不需要标记数据;相反,代理从奖励和惩罚中学习。
示例:强化学习在现实生活中的工作原理。想象一下教机器人走路:
- 起初,机器人随机移动并经常摔倒。
- 每次它保持直立时,都会获得正奖励;每次摔倒时,都会获得负奖励。
- 随着时间的推移,机器人会了解哪些动作可以保持平衡并提高其行走能力。
这正是强化学习驱动的代理学习玩视频游戏、控制自动驾驶汽车甚至优化金融投资组合的方式。
2、强化学习简史
强化学习 (RL) 根植于行为心理学、人工智能和控制理论。从奖励和惩罚中学习的想法可以追溯到心理学的早期实验,研究人员研究了动物如何通过强化来学习行为。
强化学习发展的关键里程碑
20 世纪 50 年代 — 阿兰·图灵和学习机器的理念
- 在 1950 年发表的著名论文《计算机与智能》中,阿兰·图灵提出,机器不应直接编程智能行为,而应设计为从经验中学习,就像孩子一样。
- 这一理念为自学人工智能系统奠定了基础。
20 世纪 50 年代至 60 年代 — 心理学和人工智能的早期学习模型
- B.F. Skinner 等行为心理学家研究了动物的强化,展示了奖励如何塑造行为。
- Richard Bellman 提出了贝尔曼方程,该方程成为动态规划和强化学习的数学支柱。
20 世纪 80 年代 — 现代强化学习的诞生
- Richard Sutton 和 Andrew Barto 提出了时间差分 (TD) 学习,这是强化学习的一个核心概念。
- Q 学习是一种广泛使用的强化学习算法,由 Chris Watkins 开发。
- 第一个基于 RL 的 AI 系统开始出现在机器人和游戏中。
1990 年代 - 2000 年代 - 实际应用扩展
- RL 应用于工业控制系统、机器人和金融。
- IBM 的 TD-Gammon 使用 RL 以超人的水平玩西洋双陆棋,展示了 RL 的潜力。
2010 年代 - 深度学习革命和 RL 突破
- DeepMind(2013 年)的深度 Q 网络 (DQN) 使 AI 能够从 Atari 游戏中的原始像素中学习超人的游戏策略。
- AlphaGo(2016 年)使用 RL 在围棋中击败了人类世界冠军,而围棋此前被认为对 AI 来说过于复杂。
- RL 驱动的自主机器人、自动驾驶汽车和金融模型成为现实世界的应用。
2020 年代——AI和机器人时代的强化学习
- 强化学习现在与大规模深度学习相结合,为机器人、医疗保健和决策领域的现实世界人工智能系统提供动力。
- 像 AlphaZero(国际象棋、围棋和将棋)和 MuZero(无需了解规则即可学习)这样的自学人工智能模型展示了强化学习的泛化能力。
如今,强化学习不断发展,研究重点是更好的探索技术、样本效率和现实世界的应用。
3、强化学习的核心概念
强化学习 (RL) 建立在一组基本概念之上,这些概念定义了代理如何与其环境交互以学习最佳决策策略。 理解这些核心元素对于掌握强化学习系统的工作原理至关重要。
3.1 代理-环境交互循环
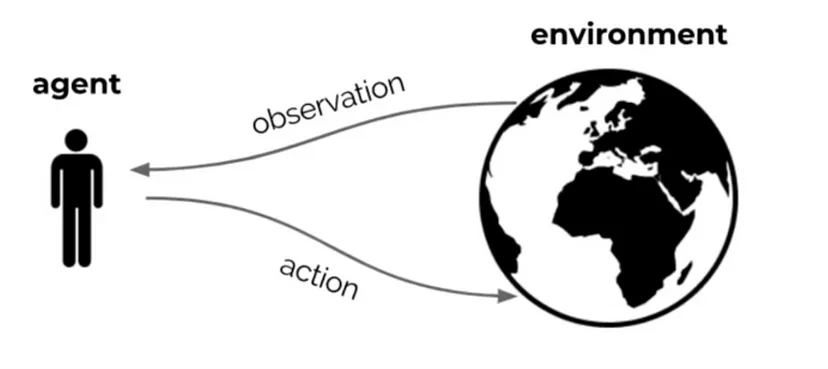
RL 的核心是代理(决策者)与环境(与其交互的世界)之间的持续反馈循环。这种互动遵循顺序决策过程:
- 代理观察环境并接收状态 St。
- 它根据其当前策略采取行动 At。
- 环境以新状态 St+1 和奖励 Rt 做出响应。
- 代理更新其知识以改进未来的行动。
随着代理改进其行为以最大化长期奖励,此过程不断重复。
3.2 奖励假设
RL 中的基本假设是,任何目标都可以表述为最大化随时间累积的奖励。奖励函数充当指导信号,帮助代理区分好行为和坏行为。
例如:
- 在玩游戏的 RL 代理中,奖励可能是每次移动后获得的分数。
- 在机器人系统中,奖励可能是其行走时的移动稳定性。
代理必须学会优化其动作以最大化其累积奖励,也称为回报 Gt
3.3 探索与利用的权衡
RL 中最大的挑战之一是在以下两者之间做出决定:
- 利用 — 选择最知名的动作以最大化即时奖励。
- 探索 — 尝试新动作以发现可能更好的策略。
例如:
- 下棋的 AI 可能会利用已知的获胜动作,但可能需要探索其他动作以找到更好的策略。
- 学习走路的机器人可能会尝试不同的步态,然后再确定最有效的步态。
平衡探索和利用对于高效学习至关重要。流行的策略包括 ε-贪婪策略、softmax 探索和上置信区间 (UCB) 方法。
4、理解强化学习中的状态、动作和策略(附示例)
强化学习 (RL) 围绕不确定环境中的决策展开。要了解 RL 代理如何学习,我们需要探索三个基本概念:
- 状态 (S):代理在任何给定时间感知的内容。
- 动作 (A):代理做出的决定。
- 策略 (π):代理决定其行动时遵循的策略。
4.1 状态 (S) — 代理看到的内容
状态表示代理在给定时刻对环境的感知。它捕获做出明智决策所需的所有相关信息。
示例 1:自动驾驶汽车
自动驾驶汽车需要根据周围环境做出驾驶决策。汽车的状态可能包括:
- 当前速度
- 与其他汽车的距离
- 交通信号灯状态(红色、黄色或绿色)
- 车道位置
在每个时间步长,汽车都会在决定行动之前观察状态。
示例 2:国际象棋游戏
国际象棋中的状态是棋盘上所有棋子的当前位置。
- 如果轮到白棋并且皇后受到威胁,状态将包含该信息。
- 代理(国际象棋玩家)必须评估状态以决定最佳动作。
示例 3:视频游戏 - 吃豆人
吃豆人的状态可能包括:
- 吃豆人的当前位置
- 幽灵的位置
- 剩余的弹丸
- 能量提升可用性
关键见解:
- 状态可以是完全可观察的(国际象棋,整个棋盘可见)或部分可观察的(扑克,只有一些牌可见)。
- 状态表示越好,代理就越能做出明智的决定。
4.2 动作(A) - 代理做什么
动作是代理在给定状态下做出的决定。不同的状态允许不同的可能动作。
示例 1:自动驾驶汽车
如果当前状态是红灯,可能的操作包括:
- 刹车(停车)
- 继续行驶(不是理想但仍然是一个选择)
如果状态是绿灯,可能的操作包括:
- 加速
- 以相同速度继续行驶
示例 2:国际象棋游戏
如果状态是棋盘上骑士处于危险之中,可能的操作包括:
- 将骑士移到安全的地方
- 忽略威胁并做出不同的动作
示例 3:吃豆人
吃豆人可以采取以下四种操作之一:
- 向左移动
- 向右移动
- 向上移动
- 向下移动
关键见解:
- 可能的操作集取决于状态。
- 代理选择一个操作来最大化长期回报。
4.3 策略 (π) — 代理如何选择操作
策略 (π) 是代理根据当前状态选择操作的策略。它定义了从状态到操作的映射。
示例 1:自动驾驶汽车(基于策略的决策)
一个简单的策略可能是:
- 如果交通信号灯是红色 → 停车
- 如果交通信号灯是绿色 → 向前行驶
该策略告诉汽车如何在不同状态下表现。
示例 2:国际象棋策略
下棋 AI 遵循的策略可能如下所示:
- 如果对手威胁到皇后 → 移至安全位置
- 如果出现攻击机会 → 捕获对手的棋子
示例 3:吃豆人策略
经过 RL 训练的吃豆人可以学习以下策略:
- 如果鬼魂在附近 → 朝相反方向移动
- 如果有能量球 → 朝它移动
- 如果屏幕上有水果 → 优先吃掉它
关键见解:
- 策略可以是确定性的 π(s)=a(始终为状态选择相同的动作)或随机性的 π(a∣s)(为动作分配概率)。
- RL 的目标是学习最大化长期回报的最佳策略。
4.4 这些概念如何协同工作
示例:吃豆人玩强化学习。
假设吃豆人正在通过强化学习进行学习。
状态:吃豆人靠近幽灵。
可用操作:向左、向右、向上或向下移动。
策略:
- 如果幽灵离你只有一步之遥,则朝相反方向移动。
- 如果附近有能量球,则朝它移动以获得免疫力。
- 如果没有直接威胁,则专注于收集能量球。
每次吃豆人存活更长时间并收集更多积分时,它都会强化良好的策略并改善决策。
最终总结
- 状态 = 代理感知到的内容。
- 操作 = 代理执行的操作。
- 策略 = 代理选择操作的策略。
强化学习的目标是学习一种策略,该策略在不同状态下选择最佳操作以最大化随着时间的推移的奖励。
5、强化学习中的奖励、价值函数和贝尔曼方程
现在我们了解了状态、动作和策略,让我们来探索代理如何评估决策是好是坏。这是通过奖励和价值函数来完成的。
5.1 什么是奖励?
奖励 (RRR) 是一种反馈信号,它告诉代理在给定状态下某个动作是好是坏。
强化学习代理的目标是随着时间的推移最大化累积奖励。
示例 1:自动驾驶汽车
- 正奖励 (+10):保持在正确的车道上
- 负奖励 (-50):撞到另一辆车
- 中性奖励 (0):在红灯处保持静止
示例 2:国际象棋 AI
- 正奖励 (+1):赢得比赛
- 负奖励 (-1):输掉比赛
- 中性奖励 (0):移动棋子
关键见解:
- 奖励是对某个动作的即时反馈。
- 代理并不总是立即获得奖励(例如,在国际象棋中,你只会在最后赢或输)。
5.2 回报 (Gt) 是什么?
由于代理希望获得长期成功,因此它关注的是总累积奖励,而不仅仅是即时奖励。
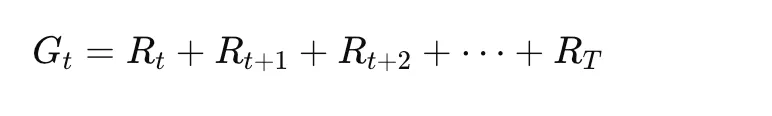
示例:吃豆人
- 吃豆人不只是想吃最近的球粒(短期奖励)。
- 它还必须避免鬼魂并为能量球(长期奖励)做好计划。
关键见解:
- RL 代理优化未来奖励的总和,而不仅仅是即时收益。
5.3 折扣因子 (γ) — 平衡即时奖励与未来奖励
由于奖励可以无限延伸到未来,我们引入了折扣因子 (γ) 来优先考虑近期奖励。

为什么要打折未来奖励?
- 未来的某些奖励不太确定。
- 代理应优先考虑早期奖励而不是远期奖励。
- 折扣因子 γ 接近 1 表示代理重视长期奖励。
- 折扣因子 γ 接近 0 表示代理只关心短期奖励。
示例:投资策略
一家公司投资于短期利润(低 γ)而不是长期增长(高 γ)。
关键见解:
- γ=0.9 表示未来奖励非常重要。
- γ= 0.1 表示代理最关心的是即时奖励。
5.4 什么是价值函数?
价值函数可帮助代理估计任何给定状态或动作的长期奖励。
状态价值函数 (V(s))
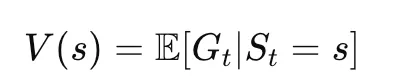
从状态 sss 开始并遵循策略 π\piπ 时的预期回报。
示例:国际象棋 AI
- 获胜位置的 V(s) 较高
- 失败位置的 V(s) 较低
动作价值函数 (Q(s,a))
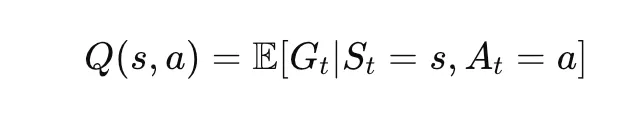
在状态 s 下采取行动 aaa 时的预期回报。
示例:吃豆人
- 如果向左移动导致幽灵,Q(s,left) 将很低。
- 如果向右移动导致能量球,Q(s,right) 将很高。
关键见解:
- V(s) 表示状态的值。
- Q(s,a) 表示状态中动作的值。
- RL 代理使用 Q 值来做出决策
5.5 贝尔曼方程 — 将问题分解为几个步骤
为了计算 V(s) 和 Q(s,a),我们使用贝尔曼方程,它将问题分解为几个较小的步骤。

这意味着:
- 状态 sss 的值是即时奖励加上下一个状态 s′的折扣值
示例:自动驾驶汽车
如果汽车处于红灯状态,则当前值 V(s) 基于:
- 即时奖励(不撞车 = +10)
- 未来奖励(更快到达目的地 = +100)
关键见解:
- 贝尔曼方程允许 RL 代理有效地估计长期奖励。
- 这是动态规划和 Q 学习的基础。
6、强化学习 (RL) 代理的类型
现在我们了解了状态、动作、奖励和价值函数,让我们探索不同类型的 RL 代理以及它们如何学习做出决策。
RL 代理可以根据其学习方式以及是否使用环境模型进行广泛分类。主要类别包括:
- 基于价值的代理——学习价值函数以确定最佳行动。
- 基于策略的代理——直接学习策略而不使用价值函数。
- 演员-评论家代理——结合基于价值和基于策略的学习。
- 无模型代理——通过反复试验进行学习,无需明确的环境模型。
- 基于模型的代理——使用环境的内部模型进行规划。
让我们详细分解它们!
6.1 基于价值的代理(学习价值函数)
基于价值的代理不直接学习策略。相反,他们估计一个价值函数,告诉他们状态或动作有多好。
工作原理:
- 代理学习 Q 值函数 Q(s,a)(动作值函数)。
- 代理在每个状态下选择具有最高 Q 值的动作。
示例算法:Q 学习
Q 学习是最著名的基于价值的 RL 算法之一。它使用贝尔曼方程更新 Q 值:
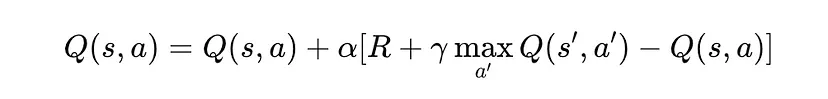
示例:吃豆人
- Q(s,left)=−10(向左移动会导致幽灵出现)。
- Q(s,right)=+50(向右移动会收集小球)。
- 代理始终选择 Q 值最高的动作。
优点:
- 在离散动作问题中很有效(例如棋盘游戏、Atari 游戏)。
- 在深度 Q 网络 (DQN) 中成功用于玩视频游戏。
限制:
- 不适用于连续动作空间(例如机器人技术)。
- 探索困难(陷入局部最优)。
6.2 基于策略的代理(直接学习策略)
基于策略的代理不使用价值函数。相反,它们直接学习将状态映射到动作的策略 π(a∣s)。
工作原理:
- 代理不是学习 Q(s,a),而是学习动作的概率分布。
- 使用基于梯度的优化来更新策略。
示例算法:强化(策略梯度)
- 代理根据其策略对动作进行采样。
- 如果该动作带来高回报,则会增加再次选择该动作的概率。
示例:机器人行走
- 机器人直接学习行走策略。
- 它根据收到的奖励调整其动作(例如,保持平衡 = 正奖励)。
优点:
- 在连续动作空间(例如自动驾驶汽车、机器人)中效果很好。
- 可以学习随机策略,在非确定性环境中很有用。
限制:
- 策略更新可能具有高方差,使学习不稳定。
- 与基于价值的方法相比,通常收敛速度较慢。
6.3 演员-评论家代理(结合价值 + 策略学习)
演员-评论家代理结合了基于价值和基于策略的学习的优点。
工作原理:
- 演员(策略网络)决定采取哪些行动。
- 评论家(价值函数)估计行动有多好。
- 评论家提供反馈以改进策略。
示例算法:优势演员-评论家(A2C,A3C)
- 评论家估计 V(s)(状态值)。
- 演员根据策略 π(a∣s) 选择动作
- 优势函数 A(s, a)=Q(s,a)−V(s) 帮助代理决定某个动作是否比预期更好。
示例:AlphaGo(DeepMind 的围棋 AI)
- 演员选择动作(策略)。
- 评论家评估棋盘位置(价值函数)。
优点:
- 比纯基于策略的方法学习更稳定。
- 减少策略更新的差异。
限制:
- 实施起来更复杂。
- 需要调整参与者和评论家网络。
6.4 无模型代理
无模型代理不构建环境模型。他们纯粹从反复试验中学习。
示例算法:
- Q 学习(基于价值)
- 强化学习(基于策略)
- 深度 Q 网络 (DQN)
示例:玩 Atari 游戏(DeepMind 的 DQN)
- 代理只看到游戏屏幕。
- 它尝试不同的动作并学习哪些策略可以最大化得分。
优点:
- 对于未知环境简单有效。
- 无需模拟复杂的现实世界物理。
局限性:
- 效率低下(需要数百万次试验)。
- 长期规划困难。
6.5 基于模型的 RL 代理(使用内部模型进行规划)
基于模型的代理构建环境模型并将其用于决策。
示例算法:
- 蒙特卡洛树搜索 (MCTS)
- MuZero (DeepMind)
示例:AlphaZero(DeepMind 的国际象棋和围棋 AI)
- AI 学习游戏规则模型。
- 在做出决定之前,它模拟未来的移动。
优点:
- 比无模型强化学习更具样本效率。
- 可以进行规划以优化决策。
限制:
- 需要一个好的模型(对于复杂的环境来说很难)。
- 计算成本更高。
7、强化学习 (RL) 在现实世界中的应用
强化学习 (RL) 已经超越了理论研究,现在正在推动多个行业的创新。从游戏 AI 到自主机器人和金融市场策略,RL 正在以最少的人为干预解决复杂的决策问题。
在本节中,我们将探索 RL 的实际应用,按领域分类。
7.1 游戏:Atari、国际象棋、围棋、扑克
RL 彻底改变了游戏 AI,使代理能够从头开始学习策略并在超人的水平上竞争。
深度 Q 网络 (DQN) — 精通 Atari 游戏:
- DeepMind 的 DQN 代理使用原始像素输入和反复试验学习来学习玩经典的 Atari 游戏。
- 在 Breakout、Pong 和 Space Invaders 等游戏中取得了超人的表现。
AlphaGo 和 AlphaZero — 击败世界冠军:
- AlphaGo (2016) 使用蒙特卡洛树搜索 (MCTS) 和深度强化学习击败了围棋世界冠军李世石。
- AlphaZero (2017) 将其扩展到国际象棋和将棋,无需人类数据进行训练,完全通过自我对弈。
扑克 AI — 不完美信息游戏中的强化学习:
- Pluribus (Facebook AI) 和 Libratus (CMU) 使用强化学习来精通扑克,这是一种隐藏信息的游戏。
- 在与顶级人类玩家的比赛中取得了持续胜利。
影响:RL 重新定义了游戏中的 AI,实现了自主策略学习和决策。
7.2 机器人&自动化:自主机器人学习
RL 对于训练机器人适应现实世界环境至关重要。
自学机器人(波士顿动力公司、OpenAI):
- Spot(波士顿动力公司)和 ANYmal 等四足机器人使用 RL 学习行走和平衡。
- OpenAI 的机械手使用 RL 巧妙地解决了魔方问题。
工厂和工业自动化:
- RL 优化了装配线的机械臂(特斯拉、宝马)。
- 深度 RL 代理实现仓库自动化(亚马逊、联邦快递)。
影响:RL 驱动的机器人无需人工重新编程即可适应和改进,从而减少了人工劳动和运营成本。
7.3 无人驾驶:自动驾驶汽车中的决策
RL 用于自动驾驶汽车的路线优化、避障和自适应控制。
Tesla Autopilot、Waymo、NVIDIA DRIVE:
- RL 用于感知、路径规划和动态控制。
- 汽车从数百万英里的真实驾驶中学习。
模拟学习 - CARLA 模拟器:
- RL 代理在 CARLA 等模拟环境中进行训练,以学习安全驾驶行为。
- 代理必须处理交通信号、行人过路处和意外障碍物。
影响:RL 增强了自动驾驶汽车的安全性和决策能力,减少了人为错误和事故。
7.4 医疗健康:个性化治疗计划
RL 正在通过优化治疗策略彻底改变医疗保健。
基于 AI 的药物发现:
- RL 帮助制药公司更快地找到最佳药物化合物(DeepMind 的 AlphaFold)。
优化化疗和透析:
- RL 模型动态调整药物剂量和治疗计划。
- AI 优化化疗方案以减少副作用,同时最大限度地提高治疗效果。
个性化患者护理:
- 深度 RL 模型为糖尿病患者个性化胰岛素剂量。
- AI 使用患者数据和行为模式定制心理健康干预措施。
影响:RL 增强精准医疗,优化治疗决策以获得更好的患者结果。
7.5 金融:股票市场交易和投资组合管理
RL 正在通过预测市场趋势和执行最佳交易策略来改变算法交易。
基于 RL 的股票交易代理:
- 对冲基金(Renaissance Technologies、Two Sigma、Citadel)使用 RL 来自动化交易执行。
- RL 代理分析历史股票数据,以便在最佳时间买入/卖出。
投资组合优化:
- RL 根据风险和回报动态调整资产配置。
- 人工智能金融顾问(例如 Wealthfront、Betterment)使用 RL 进行自动化投资决策。
影响:RL 提高投资业绩并降低市场波动风险。
7.6 能源:电网优化
RL 有助于高效能源分配和电网稳定。
Google DeepMind 的节能 AI:
- RL 将 Google 数据中心的冷却成本降低了 40%,提高了能源效率。
智能电网控制:
- RL 优化电网中的能源分配(例如平衡供需)。
- 用于可再生能源整合(太阳能、风能)以预测波动并调整电力输出。
影响:RL 驱动的能源优化减少浪费并支持绿色能源计划。
7.7 电商:个性化推荐
RL 优化产品推荐:
- 电子商务中的广告定位和广告投放。
- 亚马逊、Netflix 和 Spotify
- RL 根据用户行为定制产品、电影和音乐推荐。
- 算法可最大限度地提高用户参与度,同时最大限度地减少不相关的建议。
动态定价策略:
- RL 根据需求、竞争对手定价和客户行为实时调整产品价格。
- 亚马逊、Uber(峰值定价)和机票定价模型均使用RL。
影响:RL 可提高客户参与度、销售额和留存率。
7.8 自然语言处理 (NLP) :聊天机器人和虚拟助手
RL 用于 AI 助手(Google Assistant、Alexa、ChatGPT)以实现自然对话流。
聊天机器人中的对话管理
- RL 训练 AI 以提供更好的客户支持响应。
- 用于客户服务聊天机器人(Zendesk、Intercom)。
基于 AI 的语言翻译
- RL 可微调机器翻译模型以提高准确性。
- 用于 Google 翻译和 DeepL。
影响:RL 增强了人机交互,使 AI 更具情境感知能力和响应能力。
8、结束语
强化学习正在通过在多个领域启用自学系统来重塑 AI。
- 游戏:国际象棋、扑克和视频游戏中的超人 AI。
- 机器人技术:用于自动化和工业任务的自学机器人。
- 自动驾驶汽车:更安全、更智能的自动驾驶汽车。
- 医疗保健:优化治疗和药物发现。
- 金融:AI 驱动的股票交易和投资组合管理。
- 能源管理:更智能、更环保的电网。
- 电子商务:个性化推荐和动态定价。
- 对话式 AI:更智能的聊天机器人和虚拟助手。
随着强化学习研究的进步,我们将看到更多现实世界的应用,使人工智能系统更具适应性、智能和自主性。
原文链接:A Beginner’s Guide to Reinforcement Learning
汇智网翻译整理,转载请标明出处