RF-DETR模型微调指南

RF-DETR于2025年3月19日发布,是由Roboflow开发的一种基于Transformer的物体检测模型架构。
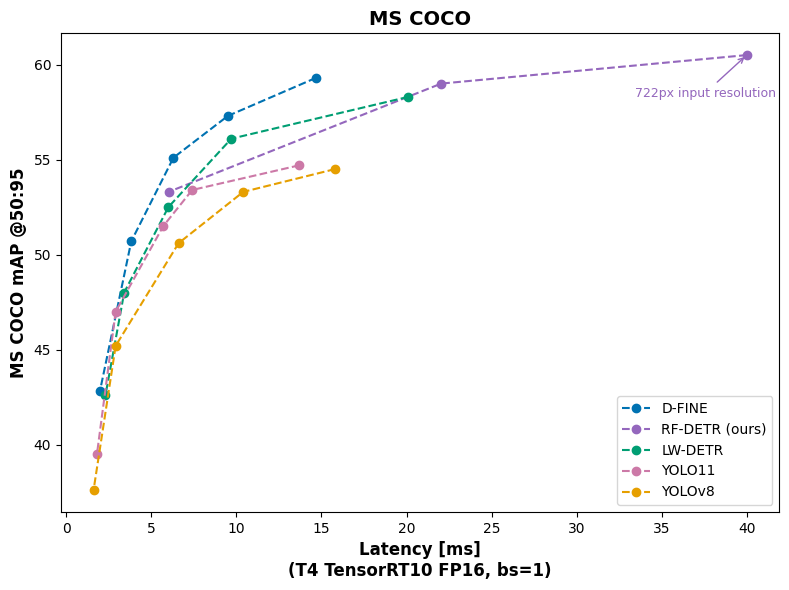
RF-DETR在COCO和新推出的RF100-VL数据集上实现了最先进的性能,超越了LW-DETR和YOLOv11等模型。RF100-VL是一个基准测试,旨在验证检测能力模型在各种领域的泛化能力。
通过将分辨率扩展到728,RF-DETR在NVIDIA T4 GPU上达到了60.5 mAP,速度为25 FPS,成为第一个在Microsoft COCO基准测试中突破60mAP障碍的实时模型。该模型在NVIDIA T4上也达到了25 FPS。
RF-DETR按照Apache 2.0许可证授权,允许免费商业使用。

在这篇指南中,我们将介绍如何在自定义数据集上训练一个RF-DETR模型。我们将以识别麻将牌为例进行训练,这是一个涉及多个不同类别的任务。
以下是我们将要训练的模型的结果示例(右侧),以及真实标签(左侧):

我们的模型结果几乎与真实标签一致,这是对RF-DETR预测质量的一个证明。
不多说了,让我们开始吧!
💡你可以使用我们的Colab训练笔记本跟随本指南。我们建议使用A100进行训练。
1、准备数据集
首先,我们需要准备一个数据集。在这个指南中,我们将使用一个麻将牌识别数据集,这是RF100-VL基准测试中的一个数据集之一。该数据集包含超过2000张麻将牌图像,并且是根据Apache 2.0许可证授权的。
你可以在Roboflow Universe上的麻将牌页面下载数据集。在下面的训练部分中,我们将展示如何直接将数据集下载到Colab笔记本中。
你可以使用任何数据集跟随本指南,但为了使用RF-DETR模型进行训练,你需要一个COCO JSON格式的数据集。
如果你需要标注数据集,可以使用Roboflow Annotate,这是我们功能齐全、基于Web的标注工具。Annotate配备了一系列工具来加速标注过程,包括一套AI辅助标注工具。
如果需要将数据集转换为COCO JSON格式,可以将其上传到Roboflow并导出为COCO JSON格式。
2、在设备上训练
我们准备了一个Colab笔记本,你可以用它跟随本指南。我们的Colab笔记本从尝试使用基础COCO权重的RF-DETR到训练和运行微调模型的推理,涵盖了所有内容。
我们建议使用NVIDIA A100 GPU来微调RF-DETR。
2.1 安装RF-DETR SDK
首先,我们需要安装RF-DETR SDK。你可以使用以下命令安装SDK:
!pip install -q rfdetr
此外,运行nvidia-smi以确保你有可用的GPU。输出应该显示你的GPU,如下所示:
2.2 下载数据集
接下来,我们需要将数据集下载到我们的训练环境中。我们可以直接从Roboflow下载麻将数据集。
首先,在环境变量ROBOFLOW_API_KEY中设置你的Roboflow API密钥。了解如何获取你的Roboflow API密钥。
然后,运行以下代码:
from roboflow import download_dataset
dataset = download_dataset("https://universe.roboflow.com/rf-100-vl/mahjong-vtacs-mexax-m4vyu-sjtd/dataset/2", "coco")
你可以把上面的数据集URL换成Roboflow Universe上的50万个数据集中的任意一个。
2.3 启动RF-DETR训练任务
在我们的训练环境中有了标注数据集后,我们现在可以开始微调模型了。
要微调模型,我们可以使用以下代码:
from rfdetr import RFDETRBase
model = RFDETRBase()
history = []
def callback2(data):
history.append(data)
model.callbacks["on_fit_epoch_end"].append(callback2)
model.train(dataset_dir=dataset.location, epochs=15, batch_size=16, lr=1e-4)在这里,我们加载了RF-DETR基础模型,然后传入我们下载的数据集的位置。在这个指南中,我们将训练15个epochs,并使用一个batch size为16。这个batch size是针对A100优化的。
当你运行代码时,你会看到显示进度的消息,如下所示:
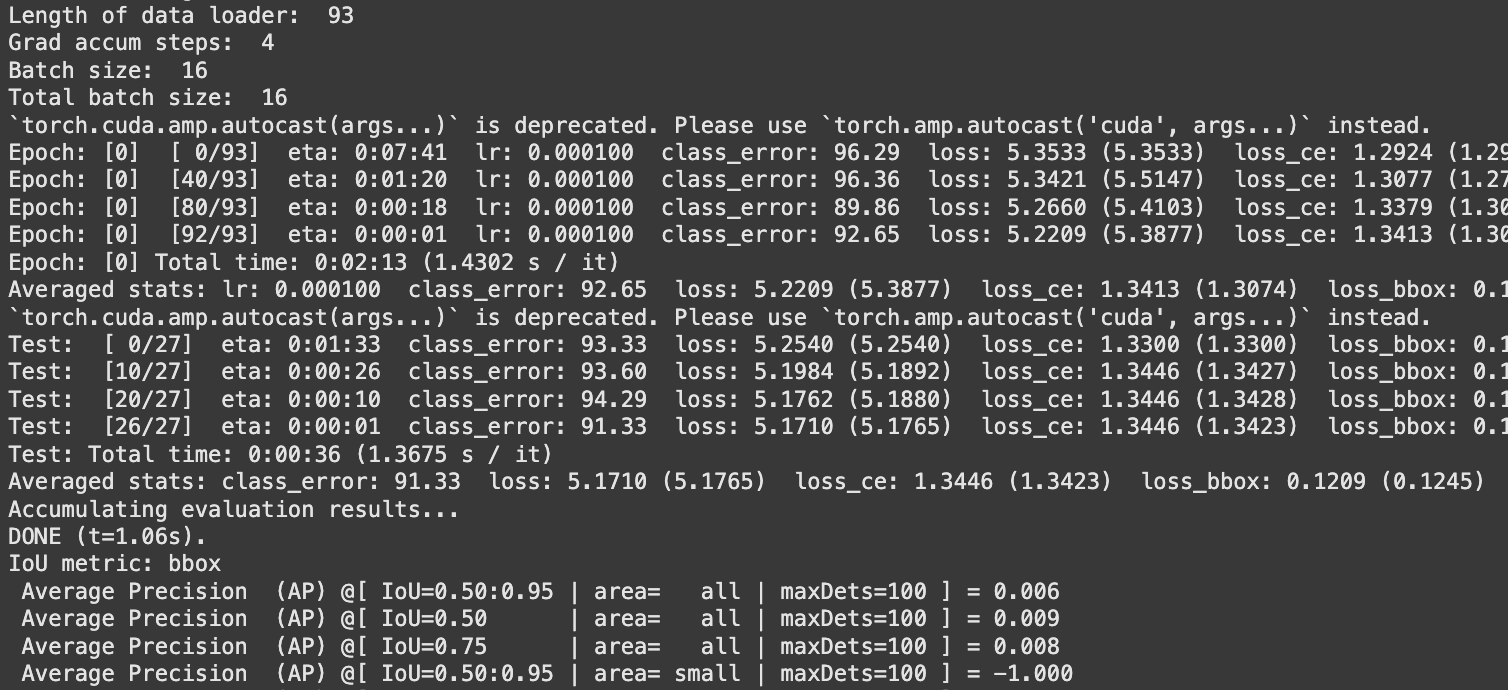
训练模型所需的时间取决于你的数据集大小和指定的epochs数量。在我们的测试中,在A100 GPU上使用15个epochs训练一个包含2000张图像的模型大约需要一个小时。
我们建议至少训练50个epochs以获得生产模型。
一旦模型训练完成,模型权重和相关元数据将保存在一个名为output的目录中。
2.4 查看模型评估指标
你可以通过绘制RF-DETR训练例程保存的数据来查看模型指标。
你可以使用以下代码绘制损失:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.DataFrame(history)
plt.figure(figsize=(12, 8))
plt.plot(
df['epoch'],
df['train_loss'],
label='Training Loss',
marker='o',
linestyle='-'
)
plt.plot(
df['epoch'],
df['test_loss'],
label='Validation Loss',
marker='o',
linestyle='--'
)
plt.title('Train/Validation Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.show()这将返回一个图表,显示每轮的损失。损失应该随着时间推移而减少。
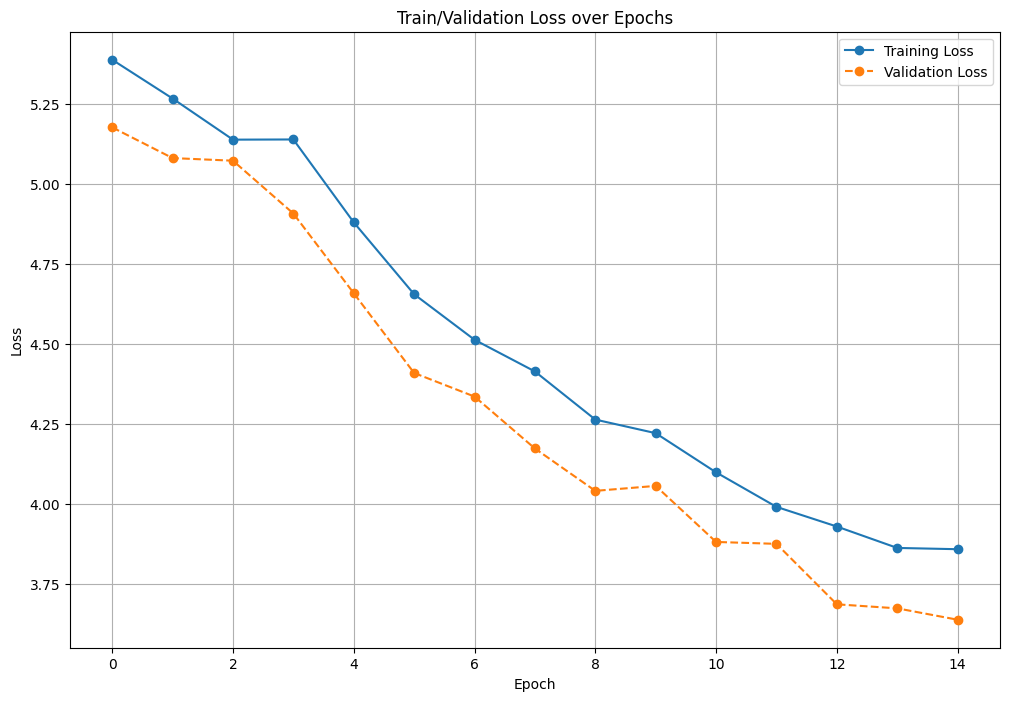
我们的训练笔记本还展示了如何计算每个epoch的AP。
3、测试你的RF-DETR模型
有了训练好的模型后,下一步是在示例图像上进行推理。
为了从我们的测试集中加载数据并可视化示例图像上的预测结果,我们将使用监督Python包。监督提供了构建计算机视觉应用程序的各种工具,包括数据加载器和注释器。
让我们加载我们的测试集:
import supervision as sv
ds = sv.DetectionDataset.from_coco(
images_directory_path=f"{dataset.location}/test",
annotations_path=f"{dataset.location}/test/_annotations.coco.json",
)接下来,让我们从我们的测试集中加载一张随机图像,并比较地面真实值与我们模型的结果:
path, image, annotations = ds[4]
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
import supervision as sv
import numpy as np
from PIL import Image
image = Image.open(path)
detections = model.predict(image, threshold=0.5)
text_scale = sv.calculate_optimal_text_scale(resolution_wh=image.size)
thickness = sv.calculate_optimal_line_thickness(resolution_wh=image.size)
bbox_annotator = sv.BoxAnnotator(thickness=thickness)
label_annotator = sv.LabelAnnotator(
text_color=sv.Color.BLACK,
text_scale=text_scale,
text_thickness=thickness,
smart_position=True)
annotations_labels = [
f"{ds.classes[class_id]}"
for class_id
in annotations.class_id
]
detections_labels = [
f"{ds.classes[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
annotation_image = image.copy()
annotation_image = bbox_annotator.annotate(annotation_image, annotations)
annotation_image = label_annotator.annotate(annotation_image, annotations, annotations_labels)
detections_image = image.copy()
detections_image = bbox_annotator.annotate(detections_image, detections)
detections_image = label_annotator.annotate(detections_image, detections, detections_labels)
sv.plot_images_grid(images=[annotation_image, detections_image], grid_size=(1, 2), titles=["Annotation", "Detection"])上述代码加载了一张随机图像,用我们微调的模型进行推理,然后在同一张图像上并排绘制地面真实值注释和模型结果。
以下是结果:

RF-DETR成功识别了各种麻将牌。虽然有些牌被遗漏了,但可以通过增加模型训练的epochs数量来解决这个问题。
现在你已经可视化了模型的结果,下一步是考虑模型部署。除了提供强大的准确性外,RF-DETR模型在NVIDIA T4上还可以达到25 FPS。这使得它们非常适合用于边缘部署环境。
我们还将推出在Roboflow Inference中部署RF-DETR的支持,这是我们开源的计算机视觉推理服务器。这将伴随着Roboflow Workflows中的支持,这是我们的视觉AI应用程序构建器。这将在未来几天内宣布。
4、结束语
RF-DETR是由Roboflow开发的一种新的实时计算机视觉模型架构。该模型是第一个在Microsoft COCO基准测试中超过60 mAP的对象检测模型。此外,该模型在NVIDIA T4上运行速度约为25 FPS。
在这篇指南中,我们介绍了如何在自定义数据集上训练RF-DETR模型。我们从Roboflow Universe下载了一个开源对象检测数据集,训练了模型15个epochs,绘制了训练图,并可视化了模型的结果。
原文链接:How to Train RF-DETR on a Custom Dataset
汇智网翻译整理,转载请标明出处
