在CPU上运行DeepSeek-R1
在 CPU 上运行 LLM 提供了一种扩大可访问性的替代方案,允许更多用户在现有硬件上利用 AI。本指南探讨了在 CPU 上有效使用 DeepSeek R1 的方法。

随着对 AI 驱动应用程序的需求不断增长,大型语言模型 (LLM) 已成为各个领域的重要工具。然而,大多数这些模型都需要强大的 GPU 才能有效运行,这使得许多用户无法使用它们。
并不是每个人都能买得起高端 GPU,而且从长远来看,云服务的成本可能很高。在 CPU 上运行 LLM 提供了一种扩大可访问性的替代方案,允许更多用户在现有硬件上利用 AI。本指南探讨了在 CPU 上有效使用 DeepSeek R1 的方法。
1、使用 Ollama
Ollama 是一个平台,允许在本地设备(包括基于 CPU 的系统)上推断大型语言模型。要使用 Ollama 运行 DeepSeek R1,请按照以下步骤操作:
1.1 安装和设置
从其官方来源下载 Ollama:
根据你的操作系统选择适当的安装方法:
- Linux:使用命令行说明进行安装。
- Windows/Mac:按照设置说明下载并安装。
1.2 使用 Ollama 运行 DeepSeek R1
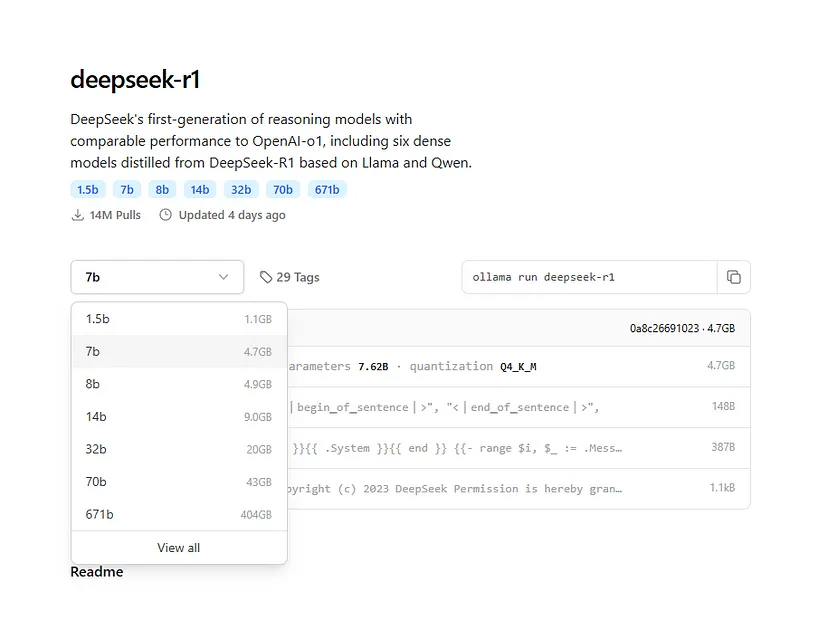
通过运行以下命令拉取 DeepSeek R1 模型:
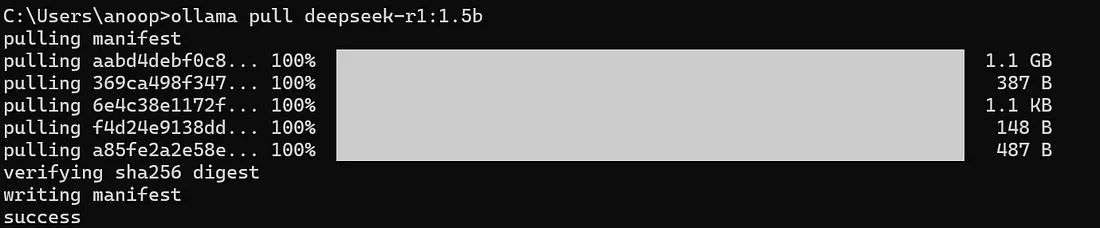
olama pull deepseek-r1:1.5b # user having very basic system
运行过程如下图所示:
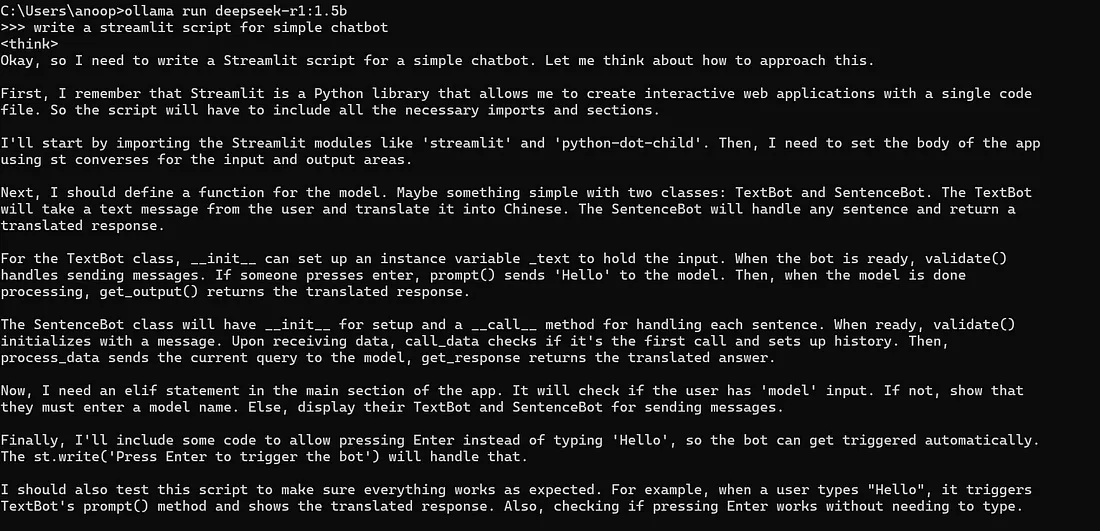
使用以下命令运行模型:
olama run deepseek-r1:1.5b模型运行后,你可以通过键入查询直接从终端开始与其交互。
2、使用 Open WebUI
对于喜欢图形界面而不是命令行交互的用户,Open WebUI 提供了一种与 LLM 交互的直观方式。
2.1 使用 Docker 设置 Open WebUI
确保你的系统上安装了 Docker Desktop。
创建一个包含必要配置的 docker-compose.yaml 文件:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
volumes:
- ollama:/root/.ollama
ports:
- "11434:11434"
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"
restart: always
volumes:
ollama:
name: ollama
open-webui:
name: open-webui- 使用 olama/olama 镜像的 Ollama 的一个服务。
- 另一项 Open WebUI 服务,从 GitHub 容器注册表中提取图像。
- 映射所需端口以启用 UI 访问。
运行以下命令启动服务:
docker-compose up(首次设置可能需要大约 15-20 分钟。)
容器运行后,打开浏览器并导航到 http://localhost:3000 。在出现提示后,请创建一个帐户:
从列表中选择 DeepSeek R1:
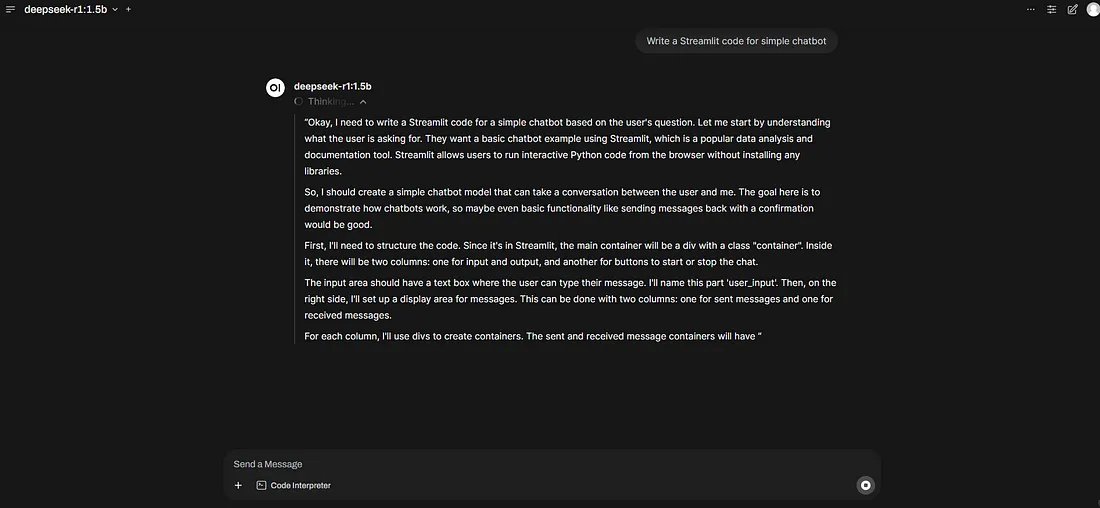
通过用户友好的 WebUI 开始与模型交互:
3、结束语
在 CPU 上运行 DeepSeek R1 而无需编写代码是一种无需昂贵的 GPU 即可利用 AI 功能的便捷方式。无论是通过 Ollama 的简单终端界面还是直观的 WebUI 设置,都有多种方法可以轻松部署和与这个强大的模型交互。通过遵循上述步骤,您可以将 DeepSeek R1 集成到您的工作流程中,并轻松探索 AI 驱动推理的巨大可能性
原文链接:Harnessing the Power of DeepSeek R1 on CPU (NO-CODE)
汇智网翻译整理,转载请标明出处
