OpenVINO本地运行Llama 3.2
本文介绍如何使用OpenVINO在本地的Intel GPU上运行Lllama 3.2大模型。

随着 Llama 3.2 的发布,访问 AI 模型的最新进展变得比以往任何时候都更加容易。得益于 OpenVINO™ 和 Optimum Intel 的无缝集成,你可以在 Intel 硬件上本地压缩、优化和运行这个强大的模型。
在本指南中,我们将引导你完成整个过程,从设置环境到执行模型,帮助你仅用 3 个步骤即可释放 Llama 3.2 的全部潜力。
1、为开发准备你的机器!
对于首次使用的用户,我们建议你按照 wiki 中的基本设置(1、2 和 3)步骤进行操作。
2、下载 OpenVINO GenAI 示例代码
运行 Llama 3.2 的最简单方法是使用 Windows 上的 OpenVINO GenAI API。我们将引导您使用提供的示例代码进行设置。
首先克隆存储库:
git clone https://github.com/openvinotoolkit/openvino.genai.git在存储库中,你将找到一个名为 chat_sample 的 Python 示例。这个简洁的示例使你能够在不到 40 行代码中使用用户提示执行 Llama 3.1。这是开始探索模型功能的直接方法。
以下是示例代码的预览:
#!/usr/bin/env python3
# Copyright (C) 2024 Intel Corporation
# SPDX-License-Identifier: Apache-2.0
import argparse
import openvino_genai
def streamer(subword):
print(subword, end='', flush=True)
# Return flag corresponds whether generation should be stopped.
# False means continue generation.
return False
def main():
parser = argparse.ArgumentParser()
parser.add_argument('model_dir')
args = parser.parse_args()
device = 'CPU' # GPU can be used as well
pipe = openvino_genai.LLMPipeline(args.model_dir, device)
config = openvino_genai.GenerationConfig()
config.max_new_tokens = 100
pipe.start_chat()
while True:
try:
prompt = input('question:\n')
except EOFError:
break
pipe.generate(prompt, config, streamer)
print('\n----------')
pipe.finish_chat()
if '__main__' == __name__:
main()接下来,让我们设置环境来处理模型下载、转换和执行。
3、安装最新版本和依赖项
为避免依赖项冲突,建议创建一个单独的虚拟环境:
python -m venv openvino_venv激活环境:
openvino_venv\Scripts\activate现在,安装必要的依赖项:
python -m pip install --upgrade pip
pip install -U --pre openvino-genai openvino openvino-tokenizers[transformers] --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
pip install --extra-index-url https://download.pytorch.org/whl/cpu "git+https://github.com/huggingface/optimum-intel.git" "git+https://github.com/openvinotoolkit/nncf.git" "onnx<=1.16.1"4、使用 NNCF 下载并导出 Llama 3.2。
在从 Hugging Face 导出模型之前,请确保你已接受此处的使用协议。
然后,使用以下命令下载并导出模型:
optimum-cli export openvino --model meta-llama/Llama-3.2-3B-Instruct --task text-generation-with-past --weight-format int4 --group-size 64 --ratio 1.0 --sym --awq --scale-estimation --dataset "wikitext2" --all-layers llama-3.2-3b-instruct-INT45、运行模型
使用以下命令运行使用 OpenVINO 的模型推理:
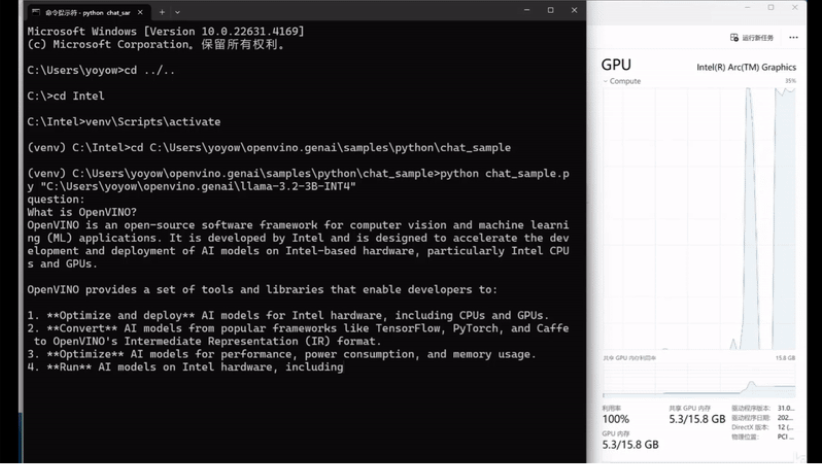
python chat_sample.py llama-3.2-3b-instruct-INT4提供的代码在 CPU 上运行,但通过在 chat_sample.py 文件中将设备名称替换为“GPU”,可以轻松使其在 GPU 上运行:
pipe = ov_genai.LLMPipeline(model_path, "GPU")这是我在 AI 的集成 GPU 上运行推理的结果PC!它在我的 ARC A770 dGPU 上运行得非常好!
6、结束语
使用 OpenVINO™ 在本地运行 Llama 3.2 为希望在英特尔硬件上最大化 AI 性能的开发人员提供了强大而高效的解决方案。
通过此设置,你可以享受更快的推理时间、更低的延迟和更少的资源消耗——所有这些都只需最少的设置和编码工作。
原文链接:How to run Llama 3.2 locally with OpenVINO™
汇智网翻译整理,转载请标明出处
