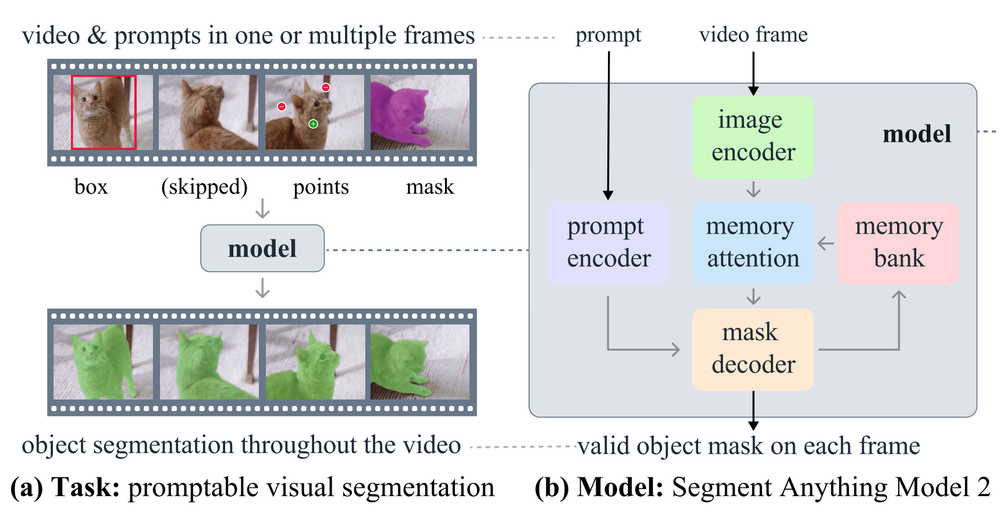
SAM 2 视频分割

Segment Anything Model 2 (SAM 2) 是一个统一的视频和图像分割模型。
与图像分割相比,视频分割面临着独特的挑战。物体运动、变形、遮挡、光照变化和其他因素可能会在帧与帧之间发生巨大变化。由于相机运动、模糊和分辨率较低,视频质量通常低于图像,这进一步增加了难度。

SAM 2 在视频分割方面表现出更高的准确性,交互次数比以前的方法少 3 倍。SAM 2 在图像分割方面更准确,速度比原始 Segment Anything Model (SAM) 快 6 倍。
1、加载 SAM 2 模型进行视频处理
💡点击这里打开本指南附带的笔记本。
首先,使用以下命令克隆存储库并安装所需的依赖项:
git clone https://github.com/facebookresearch/segment-anything-2.git
cd segment-anything-2
pip install -e .
python setup.py build_ext --inplace由于segment-anything-2代码库中存在一个bug,安装后,你需要运行如下命令:
python setup.py build_ext --inplace💡在本地安装SAM 2可能需要几分钟。请耐心等待!
在这个项目中,我们还将使用Supervision包,它将帮助我们可视化SAM 2结果,以及执行其他任务。
pip install supervisionSAM 2有4种不同的模型大小,从轻量级的“sam2_hiera_tiny”(38.9M个参数)到更强大的“sam2_hiera_large”(224.4M个参数)。这些模型的推理速度也不同。
最小的模型每秒处理大约 47 帧,而最大的模型每秒处理大约 30 帧。这些值是在 NVIDIA A100 上使用 PyTorch 2.3.1 和 CUDA 12.1 在自动混合精度和 bfloat16 下获得的。图像编码器是使用 torch.compile 编译的。
对于此演示,我们将使用最大的模型。其他模型大小的权重链接可以在存储库的 README.md 文件中找到。我们可以按如下方式下载模型权重:
wget -q https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt对于图像用例,我们使用 build_sam2 加载 SAM 2,而对于视频,我们使用 build_sam2_video_predictor。这是因为视频处理利用模型内存,在处理单个图像时不会初始化该内存。本文后面将详细介绍模型内存。
要加载模型,我们需要先前下载的权重文件的路径和 YAML 配置文件的名称。每个模型大小的配置文件也可以在存储库中找到。
import torch
from sam2.build_sam import build_sam2_video_predictor
CHECKPOINT = "checkpoints/sam2_hiera_large.pt"
CONFIG = "sam2_hiera_l.yaml"
sam2_model = build_sam2_video_predictor(CONFIG, CHECKPOINT)2、SAM 2 数据预处理
SAM 2 配备了内存,用于存储有关对象和先前交互的信息,使其能够在整个视频中生成掩码预测,并根据先前观察到的帧中存储的对象上下文有效地对其进行校正。
在开始分割之前,SAM 2 需要知道所有帧的内容。为此,必须将帧保存到磁盘。以 JPEG 格式保存帧至关重要,因为这是目前唯一支持的格式。由于所有这些帧将在下一步中加载到 VRAM 中,因此根据视频的分辨率,可能需要在将帧保存到磁盘之前缩小帧的尺寸。我们可以使用supervision包完成所有这些操作。
import supervision as sv
frames_generator = sv.get_video_frames_generator(<SOURCE_VIDEO_PATH>)
sink = sv.ImageSink(
target_dir_path=<VIDEO_FRAMES_DIRECTORY_PATH>,
image_name_pattern="{:05d}.jpeg")
with sink:
for frame in frames_generator:
sink.save_image(frame)3、初始化 SAM 2 的推理状态
SAM 2 需要有状态推理来进行交互式视频分割,因此我们需要在此视频上初始化推理状态。在初始化期间,它会加载 video_path 中的所有 JPEG 帧并将其像素存储在 inference_state 中。
inference_state = sam2_model.init_state(<VIDEO_FRAMES_DIRECTORY_PATH>)如果你之前使用此 inference_state 运行过任何跟踪,请先通过 reset_state 重置它。
sam2_model.reset_state(inference_state)4、使用 SAM 2 分割和跟踪一个对象
首先,让我们尝试在视频的第一帧中分割球。标签 1 表示正点击(添加区域),而标签 0 表示负点击(删除区域)。在定义点和标签之外的提示时,我们还需要传递我们与之交互的帧索引,并为我们与之交互的每个对象提供唯一的 ID(可以是任何整数)。
import numpy as np
points = np.array([[703, 303]], dtype=np.float32)
labels = np.array([1])
frame_idx = 0
tracker_id = 1
_, object_ids, mask_logits = sam2_model.add_new_points(
inference_state=inference_state,
frame_idx=frame_idx,
obj_id=tracker_id,
points=points,
labels=labels,
)

5、优化 SAM 2 的预测
与 SAM 类似,SAM 2 允许使用负点(不属于对象的点)提示模型。这样可以精确定义感兴趣对象的边界。
import numpy as np
points = np.array([
[703, 303],
[731, 256],
[713, 356],
[740, 297]
], dtype=np.float32)
labels = np.array([1, 0, 0, 0])
frame_idx = 0
tracker_id = 1
_, object_ids, mask_logits = sam2_model.add_new_points(
inference_state=inference_state,
frame_idx=frame_idx,
obj_id=tracker_id,
points=points,
labels=labels,
)
根据 Segment Anything 2 论文,该模型在视频任务上的准确率会随着标记视频帧的数量而增加。不要害怕在视频的不同部分标注多个帧。确保在各种 add_new_points 调用中使用适当的 frame_idx。
6、在视频中传播提示
为了将我们的点提示应用于所有视频帧,我们使用 propagate_in_video 生成器。每次调用都会返回 frame_idx(当前帧的索引)、 object_ids(在帧中检测到的对象的 ID)和 mask_logits(相应的 object_ids logit 值),我们可以使用阈值将其转换为掩码。然后,我们读取每个帧,使用 MaskAnnotator 将掩码应用于它,最后将带标注的帧写入输出视频。
import cv2
import supervision as sv
colors = ['#FF1493', '#00BFFF', '#FF6347', '#FFD700']
mask_annotator = sv.MaskAnnotator(
color=sv.ColorPalette.from_hex(colors),
color_lookup=sv.ColorLookup.TRACK)
video_info = sv.VideoInfo.from_video_path(<SOURCE_VIDEO_PATH>)
frames_paths = sorted(sv.list_files_with_extensions(
directory=<VIDEO_FRAMES_DIRECTORY_PATH>,
extensions=["jpeg"]))
with sv.VideoSink(<TARGET_VIDEO_PATH>, video_info=video_info) as sink:
for frame_idx, object_ids, mask_logits in sam2_model.propagate_in_video(inference_state):
frame = cv2.imread(frames_paths[frame_idx])
masks = (mask_logits > 0.0).cpu().numpy()
N, X, H, W = masks.shape
masks = masks.reshape(N * X, H, W)
detections = sv.Detections(
xyxy=sv.mask_to_xyxy(masks=masks),
mask=masks,
tracker_id=np.array(object_ids)
)
frame = mask_annotator.annotate(frame, detections)
sink.write_frame(frame)
7、使用 SAM 2 分割和跟踪多个对象
SAM 2 还可以同时分割和跟踪两个或多个对象。一种方法是单独执行它们。但是,将它们组合起来会更有效率,这样我们就可以在对象之间共享图像特征,从而降低计算成本。每个对象都应分配一个不同的对象 ID。


8、使用 SAM 2 跟踪多个视频中的对象
在我们的实验中,我们发现 SAM 2 可以检测到不同摄像机拍摄的镜头中可见的相同物体。在我们的实验中,我们使用了两个额外的剪辑来观察同一场篮球比赛。我们只对一个镜头的帧进行标记,并对来自所有三个剪辑的帧进行推理。
即使模型没有看到来自其他镜头的帧,SAM 2 也能够在所有三个剪辑中几乎完美地检测到它们。

9、SAM 2 视频限制
SAM 2 可能难以在镜头变化中分割物体,在拥挤的场景、长时间遮挡后或长视频中可能会丢失或混淆物体。它还面临着准确跟踪细节非常稀疏或精细的物体的挑战,尤其是当它们快速移动时。
另一种困难的情况是附近有外观相似的物体。虽然 SAM 2 可以同时跟踪视频中的多个物体,但它会分别处理每个物体,每帧仅使用共享嵌入,而无需物体间通信。
10、结束语
Segment Anything Model 2 (SAM 2) 是图像和视频分割的重大进步,它提供了一个统一的模型,具有更高的准确性、速度和上下文感知能力。
虽然在某些情况下面临限制,但 SAM 2 代表了图像和视频分割领域的强大工具,广泛应用于各个领域。
原始 SAM 模型的发布引发了 HQ Sam、FastSAM 和 MobileSA 等项目的浪潮,随着社区不断构建 SAM 2 的功能,我对未来几个月即将发表的研究论文和模型感到非常兴奋。
原文链接:How to Use SAM 2 for Video Segmentation
汇智网翻译整理,转载请标明出处
