基于Schema的LLM结构化输出

记者们通过文档转储和白皮书获得 PDF 作为对 FOIA 请求的回应。要使用 PDF,这些记者需要从文档中获取数据并将其转换为易于分析的格式,例如电子表格。该过程可能涉及费力的手动转录或将数据从一种格式复制并粘贴到另一种格式。
从理论上讲,大型语言模型可以协助文档处理,但幻觉等风险和 LLM 输出固有的不确定性使这种方法变得棘手。记者需要确保输出确实包含所需的数据、遵循所需的数据类型并采用可用的格式。
结构化输出为这些挑战提供了解决方案。像 Anthropic 和 OpenAI 这样的提供商以及像 Outlines 这样的开源库允许开发人员定义严格的模式,将 LLM 响应限制在特定字段、数据类型和格式。
结构化输出将原始的 LLM 功能转换为可靠的数据处理管道。例如,从多页 PDF 中提取表格时,模式可确保跨页面的列名和数据类型一致。虽然这种方法不能保证完全准确,但它降低了解析和验证 LLM 响应的工程复杂性,使文档处理工作流更加可靠和易于维护。
模式本质上是一个蓝图,它告诉模型要查找哪些信息以及如何组织这些信息。可以将其想象成一个标准化表格:记者不是让模型以任何格式返回数据,而是提供特定的字段来填写——这是一个日期,这是一个美元金额,另一个应该是是/否值。就像税表确保每个人都以相同的方式报告他们的收入一样,模式确保模型以一致、可预测的格式提取数据。
使用基于模式的结构化输出与 LLM 需要熟悉 Python 编程的三个方面:数据类型、类结构以及如何与 OpenAI(或其他提供商)API 交互。为了展示这种方法的潜力,下面是使用 OpenAI 的 GPT-4o 模型构建的一些示例处理管道——首先是设置关键概念的演练,然后是几个真实世界的文档。你也可以使用我构建的原型亲自尝试这种方法:上传文档,系统将建议适当的模式并自动提取数据。
1、系统设置
处理结构化输出的每种情况都涉及以下工作流程:1) 从输入文档中识别所需数据,2) 定义描述该数据的模式,3) 使用此模式和提示向 OpenAI 发送请求。为了完成这个过程,假设我们有一堆来自最近一次会议的名片,我们想把它们放入电子表格中。
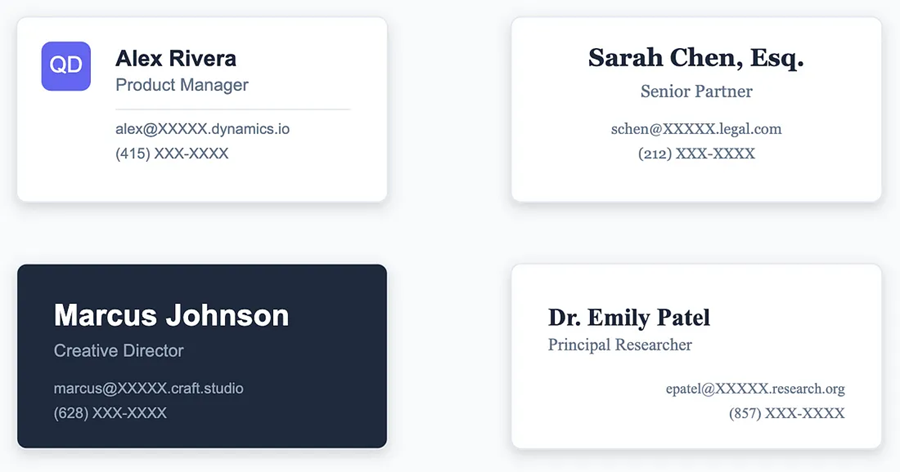
- 数据
每张卡片的格式都不同,它们都包含略有不同的信息。对于我们的电子表格,假设我们需要每张名片的姓名、职位、公司和电子邮件地址。这定义了我们将包含在模式中的数据——其他一切都会被忽略。
- 模式
对于结构化输出,模式是使用 Pydantic 定义的,这是一个 Python 库,它允许我们精确指定我们想要的数据以及应该如何格式化。Pydantic 模式采用类的形式,其中每个数据字段都是具有相关数据类型的类属性。由于这些名片中的所有字段都是文本(而不是日期或数字等),因此它们都是字符串类型:
from pydantic import BaseModel
class BusinessCard(BaseModel):
name: str
job_title: str
company: str
email_address: str这以结构化的、机器可读的格式表达了每张名片所需的数据。
2、 OpenAI 获取数据
最后,通过 OpenAI 的 Python 库发送的请求允许 LLM 提取每张名片,识别所需字段,并将请求的信息作为结构化的 JSON 对象返回(请参阅 OpenAI 关于处理图像数据的指南)。
代码:
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI() # include your API key here, or as an environment variable
# Getting the business card we want to process - see this link for more info:
# https://platform.openai.com/docs/guides/vision
business_card = open_and_format_file("business_card.jpg")
# our Pydantic schema
class BusinessCard(BaseModel):
name: str
job_title: str
company: str
email_address: str
# Querying OpenAI's API
response = client.beta.chat.completions.parse(
model="gpt-4o-mini", # the LLM to query
messages=[ # the messages to send to the model
{"role": "system", "content": "Parse the following business card:"},
{"role": "user", "content": business_card}
],
response_format=BusinessCard # using our Pydantic schema
)输出:
{
"name": "Alex Rivera",
"job_title": "Product Manager",
"company": "Quantum Dynamics",
"email_address": "alex@XXXXXdynamics.io"
}然后,我们可以将此模式应用于每张名片,将一堆杂乱无章的文档变成一个标准化的电子表格,其中包含我们所需的信息。而且由于 LLM 非常灵活,模式可以描述各种数据,因此这种方法适用于广泛的实际应用。
3、实际数据
为了演示此工作流程如何用于报告,下面是几个在实际文档中使用结构化输出的示例。
第一个示例是使用我家乡印第安纳州韦恩堡最近一次市长选举的竞选财务报告。联邦竞选财务数据受联邦选举委员会监管,可通过 OpenSecrets 等网站访问,但本地数据更难查询。报告存储在州或县级记录存储库中,可能不遵循标准格式。它们通常不是 OCR能处理的— 在某些地方,记录是手写的并扫描成 PDF 格式。LLM 可以使清理这些数据以供下游分析的过程更加顺畅。
像这样的竞选财务报告通常有几个部分——封面、个人和组织捐款表以及费用和债务表。结构化输出可以相当好地处理这些格式中的任何一种;首先,让我们将表格转换为电子表格格式。
查看个人捐款的样本,有一个简单的表格布局,我们可以将其转换为模式:

竞选财务报告中个人捐款的示例,我们将使用 GPT-4o 提取:
from typing import List
from pydantic import BaseModel
class ContributorTable(BaseModel):
# this nested class contains a field for each of the columns in the table
class ContributorRecord(BaseModel):
name_address_occupation: str
type_of_contribution: str
amount_this_period: float
amount_ytd: float
date_received_and_received_by: str
# we define the table data as a list, to tell the LLM that there are multiple rows
table_data: List["ContributorTable.ContributorRecord"]代码为我们的表格创建了一个蓝图:首先我们定义每一行应该是什么样子(一个 ContributorRecord,其中包含名称、金额、日期等字段),然后我们为整个表( ContributorTable)创建一个结构,其中包含这些记录的列表。每个字段都有特定的类型 - 文本字段标记为 str,美元金额标记为 float - 这有助于确保我们提取的数据干净且一致。
但与许多此类文档一样,也存在一些我们可能想要考虑的怪癖,这对于其他数据提取方法来说可能具有挑战性。报告将姓名、地址和职业集中到一列中;我们可能希望将它们分开。日期和接收者组合在一个不寻常的拆分列中,贡献类型记录为可选复选框和自由文本输入的混合。我们可以更新我们的模式以考虑所有这些功能,将非标准表格转换为我们可以使用的电子表格格式。
from typing import List
from pydantic import BaseModel
class ContributorTable(BaseModel):
class ContributorRecord(BaseModel):
name: str
address: str
occupation: str
contribution_is_direct: bool
other_contribution_type_description: str
amount_this_period: float
amount_ytd: float
date_received: str
received_by: str
table_data: List["ContributorTable.ContributorRecord"]并且,在将这些页面连同我们想要的模式一起发送到 OpenAI 的 API 后,LLM 会生成一个格式良好的信息电子表格,我们可以使用它进行进一步分析。更好的是,我们不必以任何方式对页面进行 OCR 或预处理 - 我们可以直接将图像发送到 OpenAI 并获取数据。
{
"table_data": [
{
"name": "###NAME###",
"address": "###ADDRESS###",
"occupation": "",
"contribution_is_direct": true,
"other_contribution_type_description": "",
"amount_this_period": 100,
"amount_ytd": 200,
"date_received": "4/9/2023",
"received_by": "Treasurer"
},
{
"name": "###NAME###",
"address": "###ADDRESS###",
"occupation": "",
"contribution_is_direct": true,
"other_contribution_type_description": "",
"amount_this_period": 100,
"amount_ytd": 200,
"date_received": "4/12/2023",
"received_by": "Treasurer"
},
{
"name": "###NAME###",
"address": "###ADDRESS###",
"occupation": "",
"contribution_is_direct": true,
"other_contribution_type_description": "",
"amount_this_period": 500,
"amount_ytd": 500,
"date_received": "4/12/2023",
"received_by": "Treasurer"
},
{
"name": "###NAME###",
"address": "###ADDRESS###",
"occupation": "Restaurant owner",
"contribution_is_direct": true,
"other_contribution_type_description": "",
"amount_this_period": 1000,
"amount_ytd": 1000,
"date_received": "4/12/2023",
"received_by": "Treasurer"
},
{
"name": "###NAME###",
"address": "###ADDRESS###",
"occupation": "",
"contribution_is_direct": true,
"other_contribution_type_description": "",
"amount_this_period": 200,
"amount_ytd": 200,
"date_received": "4/13/2023",
"received_by": "Treasurer"
}
]
}那不太标准的数据格式呢?让我们看一下这份报告的封面,其中包含键/值对、自由文本字段和财务数据表的混合。

同样,我们可以定义一个模式来捕获我们感兴趣的字段。这可以是有选择性的——假设我们关心委员会信息和财务状况,但不关心有关候选人或报告类型的任何信息:
from pydantic import BaseModel
class CoverSheet(BaseModel):
committee_name: str
committee_phone_number: str
committee_address: str
committee_party_affiliation: str
candidate_name: str
cash_on_hand_period_beginning: float
cash_on_hand_jan_1: float
itemized_contributions_this_period: float
itemized_contributions_ytd: float
unitemized_contributions_this_period: float
unitemized_contributions_ytd: float
subtotal_contributions_this_period: float
subtotal_contributions_ytd: float
total_contributions_this_period: float
total_contributions_ytd: float
itemized_expenditures_this_period: float
itemized_expenditures_ytd: float
unitemized_expenditures_this_period: float
unitemized_expenditures_ytd: float
subtotal_expenditures_this_period: float
subtotal_expenditures_ytd: float
cash_on_hand_this_period: float
cash_on_hand_ytd: float
debts_owed_by_committee: float
debts_owed_to_committee: float这不仅让我们可以从杂乱的文档中构造数据,还可以预先过滤掉与下游分析无关的任何内容:
{
"committee_name": "CITIZENS TO ELECT TOM DIDIER",
"committee_phone_number": "###PHONE NUMBER###",
"committee_address": "###ADDRESS###",
"committee_party_affiliation": "REPUBLICAN",
"cash_on_hand_period_beginning": 129106,
"cash_on_hand_jan_1": 177356.24,
"itemized_contributions_this_period": 9486.39,
"itemized_contributions_ytd": 11156.93,
"unitemized_contributions_this_period": 319638.17,
"unitemized_contributions_ytd": 358571.99,
"subtotal_contributions_this_period": 329124.56,
"subtotal_contributions_ytd": 369728.82,
"total_contributions_this_period": 458230.56,
"total_contributions_ytd": 547085.06,
"itemized_expenditures_this_period": 351502.14,
"itemized_expenditures_ytd": 439630.18,
"unitemized_expenditures_this_period": 2729.41,
"unitemized_expenditures_ytd": 34557.87,
"subtotal_expenditures_this_period": 354231.55,
"subtotal_expenditures_ytd": 443086.05,
"cash_on_hand_this_period": 103999.01,
"cash_on_hand_ytd": 103999.01,
"debts_owed_by_committee": 0,
"debts_owed_to_committee": 0
}由于 GPT-4o 可以提取其上下文窗口适合的尽可能多的图像,因此这种方法还可以处理跨多页的数据。考虑一下来自 2023 年新罕布什尔州共和党初选的民意调查数据:

数据格式良好,但与竞选财务报告一样,它们很难被机器分析提取。有些问题会跨越多页,布局包括与问题和答案本身无关的格式和信息。但我们可以定义一个仅与我们关心的文档部分相对应的模式,将所有页面作为图像一次性发送到模型,并从此调查中获取一份完整的问题和答案列表:
from pydantic import BaseModel
class Response(BaseModel):
response_text: str
response_n: int
response_percentage: float
class Question(BaseModel):
question_number: int
question_text: str
responses: List[Response]
class Poll(BaseModel):
questions: List[Question]{
"questions": [
{
"question_number": 1,
"question_text": "Are you a resident of New Hampshire?",
"responses": [
{
"response_text": "Yes",
"responses_n": 467,
"responses_percentage": 93.4
},
{
"response_text": "No",
"responses_n": 33,
"responses_percentage": 6.6
}
]
},
{
"question_number": 2,
"question_text": "How likely are you to vote in the New Hampshire Republican Primary?",
"responses": [
{
"response_text": "Very Likely",
"responses_n": 467,
"responses_percentage": 93.4
},
{
"response_text": "Somewhat Likely",
"responses_n": 33,
"responses_percentage": 6.6
}
]
},
...
]
}在这三种情况下,重要的是要注意,一致的结构并不等同于完美的数据质量。对于竞选财务封面,该模型在几个细节上出错(例如,混淆了分项和非分项捐款)。对于个人捐款,它在捐款人职业方面遇到了困难,并且会犯转录错误(例如,转置数字、拼写错误的街道名称)。虽然它能够准确地记录民意调查数据,但这些示例需要注意——对于关键数据,仍然非常需要人工审查模型输出。
由于 LLM 非常灵活,我们可以进一步扩展这种基于模式的方法。我们不需要映射文档中的每个字段、为其分配数据类型并编写模式,而是可以输入文档并让模型生成模式本身。要获得准确有效的模式,这种方法需要几个步骤 - 首先推理文档中包含哪种数据,然后生成模式的第一遍,然后清理它以符合 OpenAI 的 API 要求。但是,此管道生成的模式足以作为起点,并且通常可以按原样用于数据提取。
你可以使用我上传到 Streamlit 的原型演示,在自己的文档中尝试这种基于模式的数据提取。
4、如何比较?
当然,使用基础模型进行基于模式的提取并不是处理文档的唯一方法。OCR 已经存在很长时间了,并且有专门构建的工具
帮助记者处理 PDF。使用这些相同的测试用例,我将介绍上述流程与一些替代方法之间的一些比较点。
4.1 本地 LLM
我概述的方法的缺点之一是它需要将你的数据发送给 OpenAI 或其他外部模型提供商。这意味着会产生与查询基础模型相关的成本,以及承担外部组织获取您的数据访问权限的风险——对于某些报道项目来说,这是行不通的。为了缓解这种情况,我们可以使用完全在本地运行的小型、许可的模型测试相同的管道。除了指定不同的模型外,此更改甚至不需要对我们的实现进行任何更改。Qwen2-VL-7B-Instruct 接受多模态输入,如果我们通过 LM Studio 运行它,我们可以继续使用结构化输出来定义我们所需的模式。
一个很大的警告——这些本地模型很难在一次调用中处理多幅图像(尽管能处理多少张可能会因机器上的内存量而异)。但对于单页,我们测试用例的结果与 GPT-4o 的结果相差不大。对于竞选财务封面,本地模型遗漏了一些字段,并且再次出现了转录错误,但这是我测试的唯一一种正确识别所有财务信息的方法。
因此,虽然本地模型可能需要更多的耐心来处理数据,并且需要更多的人工审核,但当成本或数据安全很重要时,它也可能是一种可行的解决方案。
4.2 OCR + 表格提取
这是从文档中提取数据的最成熟方法。对于这些测试用例,我使用了 Docling,这是一个由 IBM 研究人员开发的最先进的系统,具有 OCR 和表格提取模型。虽然 Docling 的转录质量与 LLM 相当,但输出通常无法使用(尤其是当数据不遵循标准表格格式时)。例如,以下是 Docling 针对投票数据输出的片段(采用 markdown 格式):
Just for clarification, you are currently registered as a Democrat, but plan to vote in the Republican Primary?
(N=3)
n
%
Yes----------------------------------------------------------------------3 ---------------------------------------------------------------100.004.3 Pinpoint
上面描述的选项都需要一定程度的技术投入才能实现。为了获得现成的解决方案,我选择了 Google 的 Pinpoint。Pinpoint 被誉为记者的研究工具,旨在搜索、过滤和分析大量文档。Pinpoint 还具有一项功能(目前处于测试阶段),允许记者从这些文档中提取结构化数据。
此功能非常适合表格。在 UI 中,你可以突出显示表格,Pinpoint 会自动识别列标题和值。它还会查看项目中上传的所有文档,查找具有相同架构的表格,并自动从这些表格中提取数据。
但是,Pinpoint 也有一些限制。它不允许对输出表中的列进行任何调整。这意味着,例如,我们上面探讨的贡献者数据将姓名、地址和职业集中在一起,形成有时杂乱的文本块。要自动将表格架构应用于所有出现的情况,它们必须包含在多个文档中 — 它不适用于同一文档中的不同页面。而且结构化数据功能对于非表格数据用处不大。例如,使用这种方法实际上无法提取投票数据。因此,虽然某些表格数据可能非常适合这种方法,并且它提供了(目前免费的)现成解决方案,但 Pinpoint 并不像基于架构的解决方案那样灵活。
5、结束语
使用基础模型进行基于架构的文档处理占据了一个有趣的中间地带。它比传统的 OCR 方法更灵活,使我们能够处理各种文档格式并提取复杂信息。它比纯 LLM 聊天界面更可靠,通过架构实施进行内置验证。这种方法仍然存在局限性:它需要 Python 编程的技术知识,并且它不会消除转录错误或人工审核的需要。但与此同时,它可以大大简化将文档转换为结构化数据的机械工作。
对于处理地方政府文件的记者、处理调查回复的研究人员或构建文档分析管道的开发人员来说,这种方法提供了一条实用的前进道路。无论你是使用 GPT-4o 还是在本地运行所有内容,都可以大规模处理文档,同时保持对输出格式的控制。这项技术并不完美——仔细的验证仍然是必不可少的,尤其是对于关键数据。但通过将 LLM 输出限制为特定模式,我们可以开始构建可靠的文档处理工作流程,帮助我们减少复制和粘贴的时间,将更多时间花在实质性分析上。
原文链接:Structured Outputs: Making LLMs Reliable for Document Processing
汇智网翻译整理,转载请标明出处
