SegFormer数据集制作及模型微调
本指南展示了如何微调 Segformer,这是一种最先进的语义分割模型。我们的目标是为披萨送货机器人建立一个模型,这样它就可以看到要行驶的方向并识别障碍物 🍕🤖。
我们将首先在 Segments.ai 上标记一组人行道图像。然后,我们将使用 🤗 transformers 微调预先训练的 SegFormer 模型,transformers 是一个开源库,提供最先进模型的易于使用的实现。在此过程中,我们将学习如何使用 Hugging Face Hub,这是最大的开源模型和数据集目录。
语义分割是对图像中的每个像素进行分类的任务。你可以将其视为对图像进行更精确分类的方法。它在医学成像和自动驾驶等领域有广泛的用例。例如,对于我们的披萨送货机器人来说,重要的是要确切地知道人行道在图像中的位置,而不仅仅是是否有人行道。
因为语义分割是一种分类,所以用于图像分类和语义分割的网络架构非常相似。 2014 年,Long 等人发表了一篇开创性的论文,使用卷积神经网络进行语义分割。 最近,Transformers 已用于图像分类(例如 ViT),现在它们也用于语义分割,进一步推动了最先进的技术。
SegFormer 是 Xie 等人于 2021 年引入的语义分割模型。 它有一个不使用位置编码的分层 Transformer 编码器(与 ViT 相反)和一个简单的多层感知器解码器。 SegFormer 在多个常见数据集上实现了最先进的性能。 让我们看看我们的披萨送货机器人在人行道图像上的表现如何。
让我们从安装必要的依赖项开始。因为我们要将数据集和模型推送到 Hugging Face Hub,所以我们需要安装 Git LFS 并登录 Hugging Face。
git-lfs 的安装在您的系统上可能有所不同。请注意,Google Colab 已预装 Git LFS。
pip install -q transformers datasets evaluate segments-ai
apt-get install git-lfs
git lfs install
huggingface-cli login
1、创建/选择数据集
任何 ML 项目的第一步都是组装一个好的数据集。为了训练语义分割模型,我们需要一个带有语义分割标签的数据集。我们可以使用 Hugging Face Hub 中的现有数据集(例如 ADE20k),也可以创建自己的数据集。
对于我们的披萨外送机器人,我们可以使用现有的自动驾驶数据集(例如 CityScapes 或 BDD100K)。但是,这些数据集是由行驶在道路上的汽车捕获的。由于我们的送货机器人将在人行道上行驶,因此这些数据集中的图像与机器人在现实世界中看到的数据会不匹配。
我们不希望送货机器人感到困惑,因此我们将使用在人行道上拍摄的图像创建自己的语义分割数据集。我们将在接下来的步骤中展示如何标记我们拍摄的图像。如果你只想使用我们完成的标记数据集,则可以跳过“创建自己的数据集”部分,然后继续“使用 Hub 中的数据集”。
1.1 创建自己的数据集
要创建语义分割数据集,需要两样东西:
- 涵盖模型在现实世界中将遇到的情况的图像
- 分割标签,即每个像素代表一个类/类别的图像。
我们继续拍摄了一千张比利时人行道的图像。收集和标记这样的数据集可能需要很长时间,因此你可以从较小的数据集开始,如果模型表现不够好,则可以扩展它。

要获得分割标签,我们需要指出这些图像中所有区域/对象的类别。这可能是一项耗时的工作,但使用正确的工具可以大大加快任务速度。对于标注,我们将使用 Segments.ai,因为它具有用于图像分割的智能标记工具和易于使用的 Python SDK。
1.2 在 Segments.ai 上设置标注任务
首先,前往segments.ai 创建一个帐户。接下来,创建一个新的数据集并上传你的图像。你可以从 Web 界面或通过 Python SDK 执行此操作(参见这个笔记本)。
1.3 标注图像
现在原始数据已加载,请转到segments.ai/home 并打开新创建的数据集。单击“开始标记”并创建分割蒙版。你可以使用由 ML 驱动的超像素和自动分割工具更快地进行标记。

1.4 将结果推送到 Hugging Face Hub
完成标注后,创建一个包含标记数据的新数据集版本。你可以在 Segments.ai 上的发布选项卡上执行此操作,也可以通过 SDK 以编程方式执行此操作,如笔记本中所示。
请注意创建发布可能需要几秒钟。你可以检查 Segments.ai 上的发布选项卡,以检查你的发布是否仍在创建中。
现在,我们将通过 Segments.ai Python SDK 将发布转换为 Hugging Face 数据集。如果你尚未设置 Segments Python 客户端,请按照笔记本的“在 Segments.ai 上设置标记任务”部分中的说明进行操作。
请注意,转换可能需要一段时间,具体取决于数据集的大小。
from segments.huggingface import release2dataset
release = segments_client.get_release(dataset_identifier, release_name)
hf_dataset = release2dataset(release)
如果我们检查新数据集的特征,可以看到图像列和相应的标签。标签由两部分组成:标注列表和分割位图。标注对应于图像中的不同对象。对于每个对象,注释包含一个 id 和一个 category_id。分割位图是一幅图像,其中每个像素都包含该像素处对象的 ID。更多信息可在相关文档中找到。
对于语义分割,我们需要一个语义位图,其中包含每个像素的 category_id。我们将使用 Segments.ai SDK 中的 get_semantic_bitmap 函数将位图转换为语义位图。要将此函数应用于数据集中的所有行,我们将使用 dataset.map。
from segments.utils import get_semantic_bitmap
def convert_segmentation_bitmap(example):
return {
"label.segmentation_bitmap":
get_semantic_bitmap(
example["label.segmentation_bitmap"],
example["label.annotations"],
id_increment=0,
)
}
semantic_dataset = hf_dataset.map(
convert_segmentation_bitmap,
)
你还可以重写 convert_segmentation_bitmap 函数以使用批次并将 batched=True 传递给 dataset.map。这将显著加快映射速度,但你可能需要调整 batch_size 以确保该过程不会耗尽内存。
我们稍后要微调的 SegFormer 模型需要为特征指定特定名称。为方便起见,我们现在将匹配此格式。因此,我们将图像特征重命名为 pixel_values,将 label.segmentation_bitmap 重命名为 label,并丢弃其他特征。
semantic_dataset = semantic_dataset.rename_column('image', 'pixel_values')
semantic_dataset = semantic_dataset.rename_column('label.segmentation_bitmap', 'label')
semantic_dataset = semantic_dataset.remove_columns(['name', 'uuid', 'status', 'label.annotations'])
我们现在可以将转换后的数据集推送到 Hugging Face Hub。这样,你的团队和 Hugging Face 社区就可以使用它了。在下一节中,我们将了解如何从 Hub 加载数据集。
hf_dataset_identifier = f"{hf_username}/{dataset_name}"
semantic_dataset.push_to_hub(hf_dataset_identifier)
1.5 使用 Hub 中的数据集
如果你不想创建自己的数据集,但在 Hugging Face Hub 上找到了适合你用例的数据集,可以在此处定义标识符。
例如,你可以使用完整标注的人行道数据集。请注意,您可以直接在浏览器中查看示例。
hf_dataset_identifier = "segments/sidewalk-semantic"
2、加载并准备 Hugging Face 数据集进行训练
现在我们已经创建了一个新数据集并将其推送到 Hugging Face Hub,我们可以在一行中加载数据集。
from datasets import load_dataset
ds = load_dataset(hf_dataset_identifier)
让我们打乱数据集,并将数据集拆分为训练集和测试集。
ds = ds.shuffle(seed=1)
ds = ds["train"].train_test_split(test_size=0.2)
train_ds = ds["train"]
test_ds = ds["test"]
我们将提取标签数量和人类可读的 ID,以便我们稍后可以正确配置分割模型。
import json
from huggingface_hub import hf_hub_download
repo_id = f"datasets/{hf_dataset_identifier}"
filename = "id2label.json"
id2label = json.load(open(hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
label2id = {v: k for k, v in id2label.items()}
num_labels = len(id2label)
2.1 图像处理器和数据增强
SegFormer 模型要求输入具有特定形状。为了转换我们的训练数据以匹配预期形状,我们可以使用 SegFormerImageProcessor。我们可以使用 ds.map 函数提前将图像处理器应用于整个训练数据集,但这会占用大量磁盘空间。相反,我们将使用转换,它只会在实际使用数据时(即时)准备一批数据。这样,我们就可以开始训练,而无需等待进一步的数据预处理。
在我们的转换中,我们还将定义一些数据增强,以使我们的模型更能适应不同的光照条件。我们将使用 torchvision 的 ColorJitter 函数随机更改批次中图像的亮度、对比度、饱和度和色调。
from torchvision.transforms import ColorJitter
from transformers import SegformerImageProcessor
processor = SegformerImageProcessor()
jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
def train_transforms(example_batch):
images = [jitter(x) for x in example_batch['pixel_values']]
labels = [x for x in example_batch['label']]
inputs = processor(images, labels)
return inputs
def val_transforms(example_batch):
images = [x for x in example_batch['pixel_values']]
labels = [x for x in example_batch['label']]
inputs = processor(images, labels)
return inputs
# Set transforms
train_ds.set_transform(train_transforms)
test_ds.set_transform(val_transforms)
3、微调 SegFormer 模型
SegFormer 作者定义了 5 个大小逐渐增大的模型:B0 到 B5。下图(取自原始论文)显示了这些不同模型在 ADE20K 数据集上与其他模型相比的性能。

在这里,我们将加载最小的 SegFormer 模型 (B0),该模型在 ImageNet-1k 上进行了预训练。它只有大约 14MB 的大小!使用小模型将确保我们的模型可以在我们的披萨送货机器人上顺利运行。
from transformers import SegformerForSemanticSegmentation
pretrained_model_name = "nvidia/mit-b0"
model = SegformerForSemanticSegmentation.from_pretrained(
pretrained_model_name,
id2label=id2label,
label2id=label2id
)
3.1 设置 Trainer
为了在我们的数据上微调模型,我们将使用 Hugging Face 的 Trainer API。我们需要设置训练配置和评估指标以使用 Trainer。
首先,我们将设置 TrainingArguments。这定义了所有训练超参数,例如学习率和 epoch 数、保存模型的频率等。我们还指定在训练后将模型推送到 hub( push_to_hub=True)并指定模型名称( hub_model_id)。
from transformers import TrainingArguments
epochs = 50
lr = 0.00006
batch_size = 2
hub_model_id = "segformer-b0-finetuned-segments-sidewalk-2"
training_args = TrainingArguments(
"segformer-b0-finetuned-segments-sidewalk-outputs",
learning_rate=lr,
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
save_total_limit=3,
evaluation_strategy="steps",
save_strategy="steps",
save_steps=20,
eval_steps=20,
logging_steps=1,
eval_accumulation_steps=5,
load_best_model_at_end=True,
push_to_hub=True,
hub_model_id=hub_model_id,
hub_strategy="end",
)
接下来,我们将定义一个函数来计算我们想要使用的评估指标。因为我们正在进行语义分割,所以我们将使用平均交并比 (mIoU),可直接在evaluate库中访问。IoU 表示分割掩码的重叠。平均 IoU 是所有语义类的 IoU 的平均值。请查看此博客文章以了解图像分割评估指标的概述。
由于我们的模型输出尺寸为高度/4 和宽度/4 的 logits,因此我们必须对其进行升级,然后才能计算 mIoU。
import torch
from torch import nn
import evaluate
metric = evaluate.load("mean_iou")
def compute_metrics(eval_pred):
with torch.no_grad():
logits, labels = eval_pred
logits_tensor = torch.from_numpy(logits)
# scale the logits to the size of the label
logits_tensor = nn.functional.interpolate(
logits_tensor,
size=labels.shape[-2:],
mode="bilinear",
align_corners=False,
).argmax(dim=1)
pred_labels = logits_tensor.detach().cpu().numpy()
metrics = metric.compute(
predictions=pred_labels,
references=labels,
num_labels=len(id2label),
ignore_index=0,
reduce_labels=processor.do_reduce_labels,
)
# add per category metrics as individual key-value pairs
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
per_category_iou = metrics.pop("per_category_iou").tolist()
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
return metrics
最后,我们可以实例化一个 Trainer 对象。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
现在我们的训练器已经设置好了,训练就像调用 train 函数一样简单。我们不需要担心管理我们的 GPU,训练器会处理好这些。
trainer.train()
训练完成后,我们可以将经过微调的模型和图像处理器推送到 Hub。
这还将自动创建一个包含结果的模型卡。我们将在 kwargs 中提供一些额外信息来让模型卡更完成。
kwargs = {
"tags": ["vision", "image-segmentation"],
"finetuned_from": pretrained_model_name,
"dataset": hf_dataset_identifier,
}
processor.push_to_hub(hub_model_id)
trainer.push_to_hub(**kwargs)
4、推理
现在是激动人心的部分,使用我们经过微调的模型!在本节中,我们将展示如何从中心加载模型并将其用于推理。
但是,你也可以直接在 Hugging Face Hub 上试用你的模型,这要归功于托管推理 API 支持的酷炫小部件。如果你在上一步中将模型推送到 Hub,应该会在模型页面上看到一个推理小部件。你可以通过在模型卡中定义示例图像 URL 向小部件添加默认示例。请参阅此模型卡作为示例。
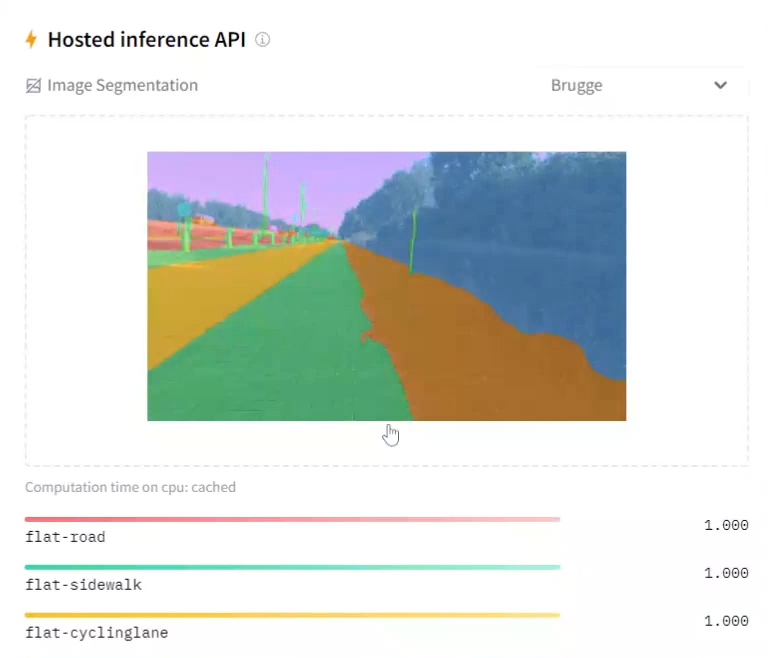
4.1 使用来自 Hub 的模型
我们首先使用 SegformerForSemanticSegmentation.from_pretrained() 从 Hub 加载模型。
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained(f"{hf_username}/{hub_model_id}")
接下来,我们将从测试数据集加载图像。
image = test_ds[0]['pixel_values']
gt_seg = test_ds[0]['label']
image
要分割此测试图像,我们首先需要使用图像处理器准备图像。然后我们将其转发给模型。
我们还需要记住将输出 logits 放大到原始图像大小。为了获得实际的类别预测,我们只需在 logits 上应用 argmax。
from torch import nn
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
# First, rescale logits to original image size
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1], # (height, width)
mode='bilinear',
align_corners=False
)
# Second, apply argmax on the class dimension
pred_seg = upsampled_logits.argmax(dim=1)[0]
现在是时候显示结果了。我们将结果显示在真实蒙版旁边。

你觉得如何?你会带着这些分割信息让披萨送货机器人上路吗?
结果可能还不完美,但我们始终可以扩展数据集以使模型更加稳健。我们现在还可以训练更大的 SegFormer 模型,看看它的表现如何。
5、结束语
就是这样!
你现在知道如何创建自己的图像分割数据集以及如何使用它来微调语义分割模型。
原文链接:Fine-Tune a Semantic Segmentation Model with a Custom Dataset
汇智网翻译整理,转载请标明出处
