用RAG实现语义路由
本文深入探讨如何通过集成向量数据库增强我们系统的语义路由能力。我们将探索架构、实现细节和优势,重点介绍这种方法如何提升LLM处理复杂和多样化任务的能力。
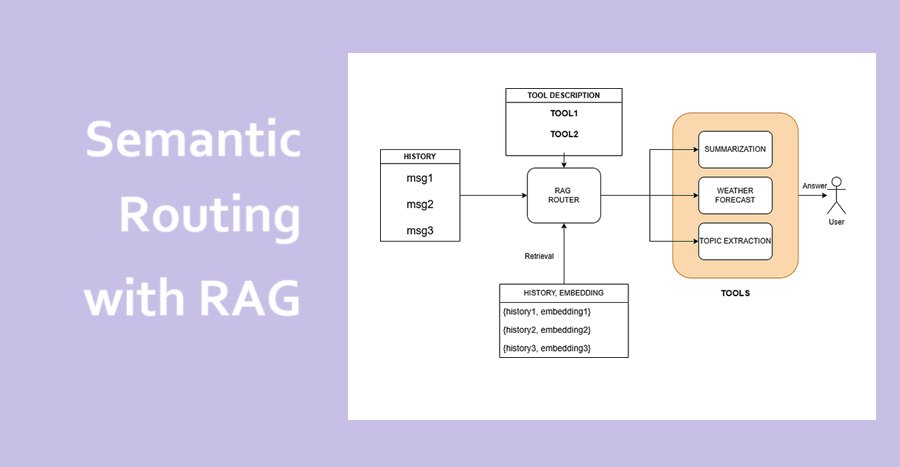
封面图说明了一个RAG(检索增强生成)系统如何充当语义路由器。该系统处理聊天历史记录(msg1、msg2、msg3),并从向量数据库中检索相关的历史消息和嵌入。它使用工具描述来决定调用哪个工具(例如,总结、天气预报、主题提取),为用户提供适当的答案。
1、引言
在本系列的第一部分(你可以在这里找到),我们探讨了配备多种工具的大规模语言模型(LLM)如何充当语义路由器以有效处理不同的用户查询。LLM分析聊天历史并根据用户的请求调用适当的工具,提供无缝的交互体验。这种方法展示了使用LLM管理各种任务(从摘要到天气预报)的潜力,而无需针对每个特定任务进行广泛的预训练或微调。
在此基础上,本系列的第二部分引入了对我们的系统的改进:将向量数据库集成到RAG(检索增强生成)系统中以实现语义路由。通过整合向量数据库,我们的LLM现在可以访问丰富的过去消息及其对应嵌入的存储库。这种额外的上下文增强了LLM在将用户查询路由到适当工具时做出更明智决策的能力。
向量数据库充当记忆库,允许LLM检索可能包含类似工具调用或上下文信息的相关历史交互。此检索功能增强了语义路由过程,提高了工具选择的准确性和效率。例如,如果用户要求对最近的消息进行摘要,LLM现在可以检索过去的摘要或类似的请求,从而优化其对任务的理解。
在本文的后续部分中,我们将深入探讨如何通过集成向量数据库增强我们系统的语义路由能力。我们将探索架构、实现细节和优势,重点介绍这种方法如何提升LLM处理复杂和多样化任务的能力。到本文结束时,您将全面了解RAG系统如何提升基于LLM的应用程序性能,为更智能和上下文感知的交互铺平道路。
指南将使用Google Colab开发,并使用Python编写,利用多个关键包,包括用于数据库管理的PostgreSQL、用于在PostgreSQL中处理向量嵌入的pgvector以及用于实例化Llama3.2 LLM的Ollama。这套工具提供了一个强大的框架,用于增强我们系统的语义路由能力。
完整的笔记本,包括代码和设置详细信息,可在我的GitHub仓库中参考。在下一节中,我们将介绍设置过程,确保您拥有跟随本教程所需的一切。
在接下来的部分中,我们将逐步介绍设置过程,并深入探讨如何将向量数据库与我们的LLM集成,以增强其语义路由能力。
2、设置
为了在Google Colab中构建我们的语义路由器RAG系统,我们首先需要设置PostgreSQL作为我们的向量数据库。我们将安装PostgreSQL、设置用户和数据库,并安装pgvector扩展以处理向量嵌入。最后,我们将安装必要的Python包以与数据库交互。
2.1 安装和设置PostgreSQL
首先,更新软件包列表并安装PostgreSQL及其contrib软件包:
!apt update
!apt install postgresql postgresql-contrib
启动PostgreSQL服务:
!service postgresql start
创建一个新的PostgreSQL用户和数据库:
!sudo -u postgres psql -c "CREATE USER rag_router WITH PASSWORD 'password';"
!sudo -u postgres psql -c "CREATE DATABASE rag_db OWNER rag_router;"
检查PostgreSQL版本以确保正确安装(应为PostgreSQL 14):
!psql --version
接下来,安装PostgreSQL服务器开发所需的软件包:
!sudo apt install postgresql-server-dev-14 #将14替换为下载的PostgreSQL版本
克隆pgvector存储库,构建并安装扩展。更多信息请访问其GitHub存储库。
!git clone --branch v0.8.0 https://github.com/pgvector/pgvector.git
!cd pgvector && make && sudo make install
重启PostgreSQL服务以应用更改:
!sudo service postgresql restart
最后,在数据库中启用向量扩展:
!sudo -u postgres psql -d rag_db -c "CREATE EXTENSION IF NOT EXISTS vector;"
为了从Python中与PostgreSQL交互,安装以下包:
!pip install sqlalchemy psycopg2-binary pgvector sentence-transformers
在PostgreSQL设置完毕且必要包安装完成后,我们现在准备开始构建RAG系统。在下一节中,我们将连接到数据库并开始构建系统。
2.2 连接到数据库并定义表
在PostgreSQL和pgvector扩展设置完毕后,我们现在可以连接到数据库并定义表结构以存储我们的消息历史和嵌入。我们将使用SQLAlchemy,一个流行的Python对象关系映射器(ORM),以无缝处理数据库交互。
我们首先使用SQLAlchemy设置连接到PostgreSQL数据库。以下是创建引擎和会话的代码:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker, declarative_base
# 定义连接详细信息
DATABASE_URL = "postgresql+psycopg2://rag_router:password@localhost:5432/rag_db"
engine = create_engine(DATABASE_URL)
Base = declarative_base()
SessionLocal = sessionmaker(bind=engine)
session = SessionLocal()
这段代码使用rag_router用户连接到rag_db数据库。SessionLocal用于创建与数据库交互的会话。
接下来,我们定义History表以存储消息及其对应的嵌入。我们将使用pgvector扩展将嵌入存储为向量。我们指定嵌入将存储为384维向量,因为我们稍后将在实现中使用名为all-MiniLM-L12-v2的句子转换器模型:
from pgvector.sqlalchemy import Vector
class History(Base):
__tablename__ = "history"
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
user_query = Column(String)
embedding = Column(Vector(384))
history = Column(String)
Base.metadata.create_all(bind=engine)
具体来说,user_query将存储用户发送的最后一条消息,embedding将是用户消息的向量表示,history将包含与用户对话的示例以及所执行的工具调用。这样,搜索嵌入时仅考虑用户发送的最后一条消息,同时我们将通过包括工具调用来丰富提供给语言模型的信息。
最后,我们在数据库中创建表:
Base.metadata.create_all(bind=engine)
通过此设置,我们已建立与PostgreSQL数据库的连接并定义了存储历史聊天消息及其嵌入的模式。此结构将使LLM能够检索过去的交互并做出更明智的决策,当将用户查询路由到适当工具时。
在下一节中,我们将探讨如何使用句子转换器模型生成嵌入并将历史消息填充到我们的数据库中。
3、准备数据集并填充数据库
现在我们已经设置了数据库,我们需要用有意义的数据填充它,以便我们的RAG系统可以使用。为此,我们将使用包含聊天的样本数据集。 相互作用,这将使我们能够在检索相关历史消息时执行相似性搜索。
3.1 下载数据集
数据集是一个CSV文件,包含用户消息及其相关的对话历史。我使用ChatGPT生成了这个数据集,以模拟各种查询-响应对。您可以使用以下命令下载它:
!wget https://github.com/Sopralapanca/medium-articles/blob/main/llm-routing/chat_sample.csv?raw=true -O chat_sample.csv
3.2 探索数据集
一旦数据集被下载,我们可以将其加载到pandas DataFrame中并检查其结构:
import pandas as pd
df = pd.read_csv("chat_sample.csv")
df.head()
数据集中的每一行包含:
history:一个JSON格式的对话历史记录,跟踪查询是如何处理的。message:用户的输入消息。
示例行的例子:
{
"history": "[{\"role\": \"user\", \"content\": \"What is the topic of this statement? 'The construction of the Great Wall of China stood as a symbol of defense and perseverance.'\"}, {\"role\": \"assistant\", \"content\": \"\", \"refusal\": null, \"audio\": null, \"function_call\": null, \"tool_calls\": [{\"id\": \"call_618996\", \"function\": {\"arguments\": \"{}\", \"name\": \"get_topic\"}, \"type\": \"function\", \"index\": 0}]}, {\"role\": \"tool\", \"content\": \"{\\\"result\\\": \\\"The topic of the sentence is The and its significance in history or technology.\\\"}\", \"tool_call_id\": \"call_618996\"}, {\"role\": \"assistant\", \"content\": \"The topic of the sentence is The and its significance in history or technology.\"}]",
"message": "What is the topic of this statement? 'The construction of the Great Wall of China stood as a symbol of defense and perseverance.'"
}
3.3 使用Sentence Transformers对消息进行编码
为了在我们的向量数据库中实现高效的相似性搜索,我们使用句子转换器模型对消息进行编码。这里我们使用Hugging Face的sentence-transformers/all-MiniLM-L12-v2,但你可以根据需要使用任何其他模型。
首先,我们下载并加载模型:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L12-v2')
要为给定文本计算嵌入,我们可以使用:
# 示例字符串以计算嵌入
example_string = "这是一个用于嵌入的示例字符串。"
# 计算嵌入
embedding = model.encode(example_string)
embedding = embedding.astype(float).tolist()
3.4 实现相似性搜索
有了存储在数据库中的嵌入,我们需要一种方法来根据给定的查询检索最相似的历史交互。我们使用L2距离实现了一个相似性搜索函数:
def similarity_search(session, query: str):
vector = model.encode(query)
records = (
session.query(History)
.order_by(History.embedding.l2_distance(vector))
.limit(3)
.all()
)
if records:
return records
else:
return None
3.5 使用消息嵌入填充数据库
现在我们已经有了数据集和编码模型,我们可以用聊天历史和消息嵌入填充PostgreSQL数据库。
# 向PostgreSQL添加记录
records = []
for i, row in df.iterrows():
embedding = model.encode(row["message"]).astype(float).tolist()
records.append(
History(
user_query=row["message"],
embedding=embedding,
history=row["history"]
)
)
try:
session.add_all(records)
session.commit()
except Exception as e:
print(e)
session.rollback()
print("异常发生,回滚中...")
3.6 验证数据插入
要确认记录是否成功插入,我们可以查询数据库:
# 检查数据是否正确插入
history = session.query(History).all()
for msg in history:
print(f"消息: {msg.user_query}\n嵌入: {msg.embedding}\n历史记录: {msg.history}\n")
break
消息: What is the topic of this statement? 'The construction of the Great Wall of China stood as a symbol of defense and perseverance.'
嵌入: [ 3.56391110e-02 1.39516190e-01 -5.41455634e-02 1.03664258e-02
5.39230816e-02 3.67860869e-02 6.48062080e-02 -1.38131268e-02
-2.76730061e-02 -1.11560058e-02 1.47463987e-02 -5.28952740e-02
9.83905196e-02 -1.85867175e-02 -1.47388298e-02 1.54635549e-01
-1.80432014e-02 2.56070755e-02 -4.38161269e-02 1.75370611e-02
6.85141832e-02 -8.59485939e-02 1.80035885e-02 -1.59655511e-02
3.60874161e-02 -7.78923854e-02 5.48197068e-02 -2.57355394e-04
9.83621106e-02 6.14276296e-03 -6.19777888e-02 1.48288729e-02
2.15548966e-02 -9.35294840e-04 4.90635224e-02 4.82670143e-02
1.11774608e-01 8.08627345e-03 5.07231131e-02 2.47926861e-02
4.28537503e-02 4.14998718e-02 6.81590289e-02 -2.15036981e-02
8.12526420e-02 2.77387793e-03 3.68143395e-02 6.26895428e-02
-5.55345230e-03 -6.85127266e-03 6.40913546e-02 -3.92634273e-02
-2.17473134e-02 -5.86708933e-02 -3.40111516e-02 7.87436664e-02
6.57240022e-03 4.95278835e-02 -4.15265560e-02 9.48650911e-02
-3.59242558e-02 1.24758534e-01 2.37003900e-02 2.68134382e-02
3.97864431e-02 9.00040846e-03 3.82129252e-02 7.64965937e-02
1.03782411e-04 1.88976265e-02 -6.49116933e-02 -1.23188486e-02
-4.75398637e-03 2.99789850e-02 3.54540278e-03 5.00601949e-03
8.93896259e-03 3.41104530e-02 4.67196945e-03 -1.00443669e-01
3.16508338e-02 1.45623286e-03 -4.84539643e-02 7.12452531e-02
-9.68752429e-03 -9.10218284e-02 -5.55495620e-02 -3.10241226e-02
-4.22470417e-04 -1.19265001e-02 -3.66672128e-02 1.46445353e-02
4.96426970e-02 6.59978241e-02 1.02954879e-01 -3.09354644e-02
-3.20205912e-02 -5.73691204e-02 3.43689173e-02 6.34342879e-02
2.55851224e-02 6.27490729e-02 1.06596723e-02 -8.67631882e-02
-6.63076481e-03 4.63875290e-03 -3.32081765e-02 -5.73190972e-02
-3.84991691e-02 -2.44544484e-02 8.25658254e-03 -2.55440194e-02
1.12267323e-02 7.35786632e-02 2.79526003e-02 -4.73383553e-02
-1.58503968e-02 1.05204647e-02 -1.86165944e-02 -2.96575539e-02
7.48385042e-02 -2.12699007e-02 5.57069527e-03 -1.62029061e-02
-6.61655515e-02 -9.45105404e-02 4.32871394e-02 -4.66416441e-02
2.62509473e-02 4.39372985e-03 -1.38002979e-02 1.33248335e-02
-8.18160269e-03 -8.02748129e-02 2.70134453e-02 1.23223849e-02
-7.47878617e-03 -3.02926470e-02 -4.14032638e-02 -5.72613478e-02
3.09377201e-02 1.01244375e-01 3.20321359e-02 -2.97183786e-02
-1.10303320e-01 -2.09869090e-02 -4.43669371e-02 -1.02053648e-02
8.20063427e-02 7.62664452e-02 -8.12128708e-02 -5.02047921e-03
5.78943007e-02 1.44760739e-02 4.03009541e-02 7.63541367e-03
-8.50614384e-02 1.66245596e-03 8.43952596e-03 -2.15932019e-02
-4.56671417e-02 4.75338548e-02 -3.62151600e-02 4.73676398e-02
-2.97146812e-02 -1.55824600e-02 -8.67354870e-03 2.77717058e-02
1.74703321e-03 1.81635134e-02 2.87144631e-03 -5.41020604e-03
1.12942189e-01 4.22507748e-02 3.91682814e-04 -8.53203014e-02
-4.47661914e-02 -4.76459078e-02 -3.29743652e-03 -1.56637095e-02
-4.58651893e-02 -4.28264774e-02 2.43080705e-02 -5.89831397e-02
-9.11172256e-02 3.48661244e-02 8.31293017e-02 4.01404984e-02
-3.10640279e-02 1.24621168e-02 -2.74060816e-02 1.26842916e-01
-2.19727959e-02 9.75351129e-03 -5.09146526e-02 -1.67063437e-02
-3.23992246e-03 2.87737064e-02 -1.79229793e-03 3.00386106e-04
3.36830020e-02 -1.28349945e-01 -5.14890850e-02 -3.70209031e-02
-1.97049398e-02 -1.65791754e-02 3.59189548e-02 -3.81764360e-02
-7.11437687e-02 -3.98273207e-02 8.34823996e-02 4.33139391e-02
-1.99118759e-02 -2.18496043e-02 8.09674039e-02 -6.74301088e-02
5.46612293e-02 -4.60898355e-02 2.00929865e-02 -4.15070616e-02
6.55146763e-02 1.45574342e-02 -9.53789726e-02 1.94731380e-32
-4.41746990e-04 8.25959083e-04 2.97364648e-02 -7.46690028e-04
7.88325816e-02 -4.50695232e-02 -6.51104674e-02 -8.05454850e-02
-7.88509473e-03 3.96083333e-02 -4.75353599e-02 -2.30434928e-02
-6.51504025e-02 2.76793819e-02 -5.01169302e-02 -6.53670430e-02
-5.98709285e-02 4.23941482e-03 -8.36451054e-02 1.13330772e-02
-2.34593190e-02 -4.59063910e-02 3.57888849e-03 -4.64538410e-02
-2.98117474e-02 7.94593543e-02 -2.64531281e-02 -1.59601942e-01
4.22903225e-02 -2.06399094e-02 2.75755525e-02 1.84438974e-02
-9.15093422e-02 5.66963106e-02 1.66896638e-02 -3.73455472e-02
1.52522415e-01 -8.48315880e-02 2.63659228e-02 -3.79037857e-02
1.38341263e-02 4.33253236e-02 -2.34484095e-02 9.58907083e-02
-1.31546184e-01 -1.39121357e-02 4.28867005e-02 -2.43927296e-02
4.78442991e-03 -1.73287131e-02 -6.86097741e-02 3.76354791e-02
1.17679916e-01 -4.43245620e-02 3.07631288e-02 1.20571703e-02
-2.17988212e-02 6.58176616e-02 1.77962612e-02 -4.60228510e-02
7.70573970e-03 3.27375829e-02 6.07456602e-02 -4.94542122e-02
1.00167699e-01 -2.38578729e-02 4.65676300e-02 4.62845601e-02
-4.97905863e-03 1.85510435e-03 -1.16905391e-01 3.51430066e-02
-1.06304400e-01 8.91971216e-02 -3.10810525e-02 5.48285544e-02
-3.63852121e-02 -2.21131593e-02 3.69688943e-02 1.48576617e-01
2.97230985e-02 -6.04069978e-02 1.77705847e-02 -5.33979535e-02
2.62360368e-02 -6.37743762e-03 -7.56596848e-02 2.04473902e-02
7.99300298e-02 2.35495856e-03 -3.24344523e-02 -1.81301851e-02
-1.31327033e-01 -3.24439183e-02 -7.39989849e-03 4.80660492e-32
2.95547321e-02 -7.94379134e-03 -9.85979363e-02 3.08770710e-03
1.08095780e-02 2.17941068e-02 9.08277463e-03 -3.99402045e-02
1.82272941e-02 3.61790732e-02 2.63478216e-02 1.13106752e-02
-6.57167435e-02 -3.85014787e-02 -4.57616001e-02 -1.21498890e-02
1.38666248e-02 -7.27558360e-02 1.94157399e-02 -2.25873925e-02
4.49696966e-02 -2.24020313e-02 -5.85773066e-02 -5.40203154e-02
-3.80695499e-02 6.43591136e-02 1.37437014e-02 5.77405235e-03
1.27854757e-02 -2.48799287e-02 1.23569416e-03 -1.18192136e-02
-2.60241125e-02 -5.27605973e-02 4.36215987e-03 -9.67641175e-03
4.66862544e-02 -5.00502773e-02 7.56993815e-02 -7.21424446e-02
-3.45649831e-02 6.74557760e-02 2.10934952e-02 3.93601432e-02
-1.10357683e-02 3.09072342e-02 9.55893192e-03 3.02247368e-02
-2.37568989e-02 -4.54251878e-02 -7.33901784e-02 2.13674009e-02
7.13499486e-02 -2.92651337e-02 -7.71111762e-03 1.10905610e-01
2.95666140e-02 4.70999219e-02 9.64558974e-04 -4.27337065e-02
3.81121859e-02 5.68572134e-02 -1.32158529e-02 5.79213873e-02]
历史记录: "[{\"role\": \"user\", \"content\": \"长城的建造作为防御和毅力的象征。\"}, {\"role\": \"assistant\", \"content\": \"\", \"refusal\": null, \"audio\": null, \"function_call\": null, \"tool_calls\": [{\"id\": \"call_618996\", \"function\": {\"arguments\": \"{}\", \"name\": \"get_topic\"}, \"type\": \"function\", \"index\": 0}]}, {\"role\": \"tool\", \"content\": \"{\\\"result\\\": \\\"该句子的主题是长城及其在历史或技术方面的意义。\\\"}\", \"tool_call_id\": \"call_618996\"}, {\"role\": \"assistant\", \"content\": \"该句子的主题是长城及其在历史或技术方面的意义。\"}]"
现在我们的数据库已经用示例聊天消息和嵌入数据填充完毕,我们已经准备好将我们的基于LLM的检索系统与PostgreSQL集成。在下一节中,我们将下载Ollama和Llama3.2。接下来,我们将使用向量数据库来改进我们的LLM路由机制。
4、设置Ollama和大型语言模型(LLMs)
Ollama是一个设计用于在本地机器上高效运行和管理大型语言模型(LLMs)的强大框架。它允许用户下载、提供和交互模型,而无需依赖外部API。通过Ollama,开发人员可以优化模型部署并针对各种任务进行执行,从聊天机器人应用程序到复杂的AI驱动工作流。
4.1 下载和设置Ollama
要安装Ollama,请运行以下命令:
!curl https://ollama.ai/install.sh | sh安装完成后,启动Ollama服务器:
!ollama serve > server.log 2>&1 & # Ollama runs by default at 127.0.0.1:11434
4.2 下载大型语言模型
在这个实现中,我们使用llama3.2:3b既作为路由器又作为专门的任务代理。这个选择是为了简单性和说明目的。用户可以根据需要选择不同的模型进行路由和专门任务,只要所选的路由模型支持工具调用。
要下载模型,请执行:
%%capture
agents_model = "llama3.2:3b"
#!ollama pull {agents_model}
%%capture
router_model = "llama3.2:3b"
!ollama pull {router_model}检查可用模型:
!ollama lsNAME ID SIZE MODIFIED
llama3.2:3b a80c4f17acd5 2.0 GB Less than a second ago 4.3 在不同端口上服务模型
为了在同一台机器上同时服务于多个模型并使用不同的端口,设置环境变量并运行多个Ollama实例:
import os
os.environ['OLLAMA_HOST'] = "127.0.0.1:11438"
!ollama serve > server.log 2>&1 &
os.environ['OLLAMA_HOST'] = "127.0.0.1:11439"
!ollama serve > server.log 2>&1 &5、设置路由器模型和专门代理
在定义路由器模型及其工具之前,请安装必要的Python包:
!pip install openai==1.57.4 ollama==0.4.4 pydantic==2.10.3这些包允许我们与Ollama交互,使用Pydantic定义结构化数据,并使用OpenAI的API。
5.1 定义可用工具
在功能调用的LLM设置中,工具是模型可以在用户请求特定任务时调用的专用函数。我们定义了两个工具:
from openai import OpenAI
import openai
summarizer_tool = {
"type": "function",
"function": {
"name": "get_summarization",
"description": "Call this method whenever you need to perform a summarization task, for example when a user asks 'Summarize this paragraph'. This method does not accept input parameters.",
"parameters": {
"type": "object",
"properties": {},
"required": [],
"additionalProperties": False
}
}
}
topics_tool = {
"type": "function",
"function": {
"name": "get_topics",
"description": "Call this whenever you need to perform a topic extraction task, for example when a user asks 'What are the topics of this paragraph?'. This method does not accept input parameters.",
"parameters": {
"type": "object",
"properties": {},
"required": [],
"additionalProperties": False
}
}
}
tools = [topics_tool, summarizer_tool]这些工具适用于两种任务:
- 摘要:提取给定文本的简洁摘要。
- 主题提取:识别段落中的关键主题。
请注意,在这种情况下,我们不会让语言模型生成工具的输入参数。这是因为,对于所选任务,LLM可能会发明或更改输入文本。相反,我们将向工具传递用户的最后一条消息。
为简单起见,我们只定义了两个工具,但可以通过相同的结构创建更多工具。描述必须准确,因为模糊的描述可能会使模型在决定调用哪个工具时感到困惑。
5.2 定义专门代理
每个专门代理负责处理特定任务。摘要和主题提取代理定义如下:
from openai import OpenAI
summarizer_client = OpenAI(
base_url='http://localhost:11439/v1',
api_key='ollama', # required, but unused
)
topic_client = OpenAI(
base_url='http://localhost:11438/v1',
api_key='ollama', # required, but unused
)- summarizer_client 连接到运行在端口
11439的模型,用于处理摘要。 - topic_client 连接到运行在端口
11438的模型,用于处理主题提取。
然后我们定义一个辅助函数来构建对话历史:
def build_history_agents(messages: list[dict[str, str]], sys_prompt: str):
history = [{"role": "system", "content": sys_prompt}]
for message in messages:
if message["role"] != "system":
history.append(message)
return history此函数确保:
- 每个代理都收到带有明确角色说明的系统消息。
- 对话历史被正确维护。
5.3 摘要代理
def get_summarization(history: list[dict[str, str]]):
print("calling summarization model")
sys_prompt = "You are a summarizer agent. Your only role is to summarize user messages. If the user requests any other action or chit-chat, just answer 'Pass.'"
k = build_history_agents(history, sys_prompt)
response = summarizer_client.chat.completions.create(
model=agents_model,
messages=k,
)
return response.choices[0].message.content此函数:
- 调用摘要模型。
- 强制代理严格遵守角色(仅总结,忽略无关请求)。
- 返回生成的摘要。
5.4 主题提取代理
def get_topics(history: list[dict[str, str]]):
print("calling topic model")
sys_prompt = "You are a topic extractor model. Your role is to examine user messages and extract the topics. If the user requests any other action or chit-chat, just answer 'Pass.'"
response = topic_client.chat.completions.create(
model=agents_model,
messages=build_history_agents(history, sys_prompt),
)
return response.choices[0].message.content此函数:
- 调用主题提取模型。
- 使用严格的提示确保代理不执行其他任务。
- 返回提取的主题。
5.5 工具执行实用函数
import json
import re
def execute_function_call(response, history):
if response.choices[0].finish_reason == "tool_calls":
tool_call = response.choices[0].message.tool_calls[0]
function_name = tool_call.function.name
result = globals()[function_name](history)
function_call_result_message = {
"role": "tool",
"content": json.dumps({
"result": result
}),
"tool_call_id": response.choices[0].message.tool_calls[0].id
}
response_dict = response.model_dump()
response_dict["choices"][0]["message"]
history = history + [response_dict["choices"][0]["message"]] + [function_call_result_message]
return history此函数管理工具调用的执行。如果模型调用工具,它会获取函数名并执行它。工具的响应被格式化并附加到对话历史中。
5.6 构建路由器历史
def build_router_history(messages: list[dict[str, str]], response):
res = response.choices[0].message.content
messages.append(
{
"role": "assistant",
"content": res
}
)
print(res)
return messages这将路由器模型的响应附加到消息历史中,并帮助在多次对话中保持上下文。
5.7 路由器
路由器模型确定哪个工具或代理应处理用户的请求。
router_client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama', # required, but unused
)使用路由器处理请求的函数:
import copy
router_client = OpenAI(
base_url = 'http://localhost:11434/v1',
api_key='ollama', # required, but unused
)
def call_router(messages: list[dict[str, str]], use_tools=True):
user_request = messages[-1]["content"]
# retrieve similar query
res = similarity_search(session, user_request)
augmented_history = copy.deepcopy(messages)
augmented_message = f"User request: {user_request}\n"
if res:
results = "Retrieved results:\n"
for record in res:
results += record.history + "\n\n"
augmented_message += results
augmented_history[-1]["content"] = augmented_message
response = router_client.chat.completions.create(
model=router_model,
messages=augmented_history,
tools=tools if use_tools else None
)
return response此函数:
- 处理用户的请求并使用检索到的信息(如果可用)对其进行扩充。
- 将请求传递给路由器模型,路由器模型决定是否:直接处理请求,或通过函数调用调用专用代理。
- 如果启用(use_tools=True),则使用函数调用以允许路由到适当的工具
6、与助手聊天
现在我们已经设置了路由器模型和专用代理,我们可以与助手进行交互。路由器的工作是分析聊天记录和用户意图,确定要使用哪种工具,并调用适当的专用模型。如果请求不需要专用工具,路由器将直接回答。
下面,我们定义了一个系统提示,指导路由器如何处理用户请求。
6.1 系统提示说明
系统提示至关重要,因为它定义了路由器应如何表现。它通知模型它充当 RAG 路由模型,这意味着它应该分析用户请求和检索到的历史数据以决定调用哪个工具。
系统提示的关键元素:
- 定义路由器的角色:路由器根据聊天记录和可用工具了解用户意图。
- 列出可用工具:get_summarization 用于总结段落,get_topics 用于从段落中提取主题。
- 回答指南:如果请求与工具匹配,则调用该工具。如果请求不需要工具,则直接响应。
- 用户消息的结构:用户请求的格式为:
- 用户请求:-> 实际用户消息
- 检索到的结果:-> 从数据库检索到的类似请求列表
6.2 代码:与助手交互
我们创建对话历史记录并发送摘要请求。
sys_prompt = """
You are a RAG routing model. Your role is to understand the chat history and user intent and use available tools to answer the questions.
Your available tools are:
- get_summarization: use it to summarize a user paragraph.
- get_topics: use it to extract the topics from a user paragraph.
For all other requests you can answer directly.
User messages will be provided to you in the form of:
'User request: -> actual user message'
'Retrieved results: -> list of similar requests retrieved from a database that you can use to understand which tool to call'
"""
messages = [
{
"role": "system",
"content": sys_prompt
},
{
"role": "user",
"content": "Hi, can you summarize this paragraph? The red glow of tail lights indicating another long drive home from work after an even longer 24-hour shift at the hospital. The shift hadn’t been horrible but the constant stream of patients entering the ER meant there was no downtime. She had some of the “regulars” in tonight with new ailments they were sure were going to kill them. It’s amazing what a couple of Tylenol and a physical exam from the doctor did to eliminate their pain, nausea, headache, or whatever other mild symptoms they had. Sometimes she wondered if all they really needed was some interaction with others and a bit of the individual attention they received from the nurses."
}
]
response = call_router(messages)
print(response)我们得到如下的响应:
ChatCompletion(id='chatcmpl-793', choices=[Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_i71ihvtb', function=Function(arguments='{}', name='get_summarization'), type='function', index=0)]))], created=1742753707, model='llama3.2:3b', object='chat.completion', service_tier=None, system_fingerprint='fp_ollama', usage=CompletionUsage(completion_tokens=15, prompt_tokens=1222, total_tokens=1237, completion_tokens_details=None, prompt_tokens_details=None))分析响应时,我们观察到LLM正确调用了 get_summarization 工具。我们现在执行调用:
fun_call_result = execute_function_call(response, messages)分析工具调用的响应,我们得到:
calling summarization model
[{'role': 'system',
'content': "\nYou are a RAG routing model. Your role is to understand the chat history and user intent and use available tools to answer the questions.\nYour available tools are:\n- get_summarization: use it to summarize a user paragraph.\n- get_topics: use it to extract the topics from a user paragraph.\n\nFor all other requests you can answer directly.\n\nUser messages will be provided to you in the form of:\n'User request: -> actual user message'\n'Retrieved results: -> list of similar requests retrieved from a database that you can use to understand which tool to call\n"},
{'role': 'user',
'content': 'Hi, can you summarize this paragraph? The red glow of tail lights indicating another long drive home from work after an even longer 24-hour shift at the hospital. The shift hadn’t been horrible but the constant stream of patients entering the ER meant there was no downtime. She had some of the “regulars” in tonight with new ailments they were sure were going to kill them. It’s amazing what a couple of Tylenol and a physical exam from the doctor did to eliminate their pain, nausea, headache, or whatever other mild symptoms they had. Sometimes she wondered if all they really needed was some interaction with others and a bit of the individual attention they received from the nurses.'},
{'content': '',
'refusal': None,
'role': 'assistant',
'audio': None,
'function_call': None,
'tool_calls': [{'id': 'call_i71ihvtb',
'function': {'arguments': '{}', 'name': 'get_summarization'},
'type': 'function',
'index': 0}]},
{'role': 'tool',
'content': '{"result": "A nurse worked two shifts in the hospital due to constant patient flow, leaving her little time for rest or downtime. She dealt with \\"regulars\\" who seemed severe, but were often treated with relatively simple medications, leading her to wonder if some patients simply needed human interaction and care instead of urgent treatment."}',
'tool_call_id': 'call_i71ihvtb'}]从最后一条消息中可以看出,实际上我们有一个由摘要代理计算出的段落摘要。因此将其传回路由器。
response = call_router(fun_call_result, use_tools=False)
res = build_router_history(messages, response)
其应答是:
The nurse worked two long shifts in the hospital due to constant patient flow, leaving her little time for rest or downtime. She dealt with "regulars" who seemed severe, but were often treated with relatively simple medications, leading her to wonder if some patients simply needed human interaction and care instead of urgent treatment.现在我们要求助手提取第一条消息的主题:
messages.append({
"role": "user",
"content": "Now can you extract topics from the paragraph that I sent you on the first message?"
}
)
response = call_router(messages)
print(response)再次,我们分析响应并看到路由器正确调用了 get_topics 工具。
ChatCompletion(id='chatcmpl-648', choices=[Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_ipcwovno', function=Function(arguments='{"$":"[]"}', name='get_topics'), type='function', index=0)]))], created=1742753722, model='llama3.2:3b', object='chat.completion', service_tier=None, system_fingerprint='fp_ollama', usage=CompletionUsage(completion_tokens=17, prompt_tokens=1155, total_tokens=1172, completion_tokens_details=None, prompt_tokens_details=None))我们执行工具调用:
fun_call_result = execute_function_call(response, messages)
response = call_router(fun_call_result, use_tools=False)
res = build_router_history(messages, response)这时,主题被正确提取:
Here are the topics extracted from the original paragraph:
1. Nursing
2. Hospital shift
3. Patient care
4. ER (Emergency Room) environment
5. Human interaction
6. Physical and mental well-being of patients7、结束语
在本节中,我们演示了检索增强生成 (RAG) 系统如何充当语义路由器,有效地将用户查询引导至适当的专业模型。通过定义清晰的系统提示并指定可用的工具,我们使路由器能够做出明智的决定,决定是直接响应还是调用工具。
我们通过以下方式对此进行了测试:
- 请求对一段文字进行总结,正确触发了
get_summarization工具。 - 要求从同一段文字中提取主题,系统正确调用了
get_topics工具。
7.1 影响系统提示和工具定义的影响
路由器决策的准确性在很大程度上取决于系统提示的编写方式以及工具的定义方式。一个结构良好的提示确保模型理解何时调用工具以及选择哪个工具。每个工具描述得越清楚,歧义就越少,从而降低错误函数调用的风险。
通过修改系统提示或添加更多工具,我们可以扩展路由器的能力以处理其他任务,例如文本分类、情感分析或翻译。这种灵活性使系统能够高度适应不同的应用场景。
7.2 为不同任务使用不同的模型
这种方法的一个优点是其模块化设计,允许不同的模型处理不同的任务。路由器本身可以使用通用语言模型实现,而专门的任务如摘要生成或主题提取可以由针对这些特定领域优化的模型来处理。这种灵活性使得在准确率、效率和成本之间取得更好的权衡成为可能。
7.3 使用RAG作为语义路由器的优势
基于RAG的路由器相比传统的基于规则的方法提供了几个关键优势:
- 更好的意图理解:系统可以通过分析聊天记录和检索到的例子来推断用户的意图。
- 上下文感知的决策制定:检索到的过往互动有助于精炼工具选择并提高响应质量。
- 动态适应性:随着需求的变化,系统可以通过集成新的工具和模型来进化。
通过利用检索增强生成(RAG)与结构化的路由机制,我们增强了AI驱动助手的效率、准确性和灵活性。这种方法使语言模型能够超越通用响应,提供任务特定且上下文感知的交互,使其在现实世界的应用中更加可靠和有效。
原文链接:RAG Routers: Semantic Routing with LLMs and Tool Calling
汇智网翻译整理,转载请标明出处
