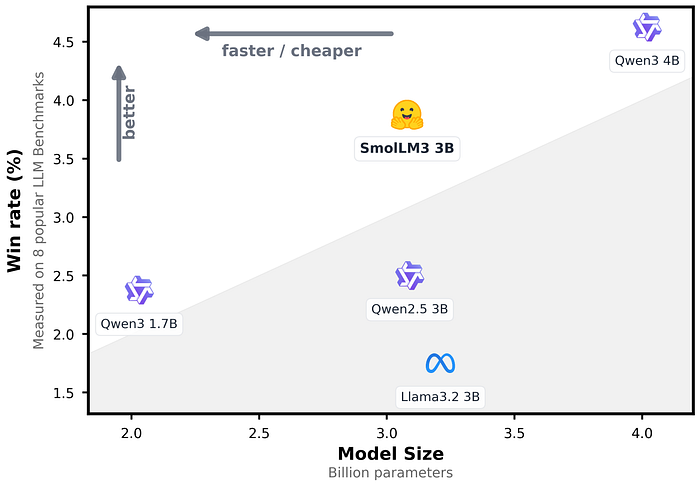
SmolLM3最佳通用小模型
Hugging Face刚刚发布了SmolLM3,一个30亿参数的模型,但它的表现就像它有两倍那么多,甚至击败了拥有70亿参数的模型。

Hugging Face刚刚发布了SmolLM3。而且,这个名字不是讽刺。这是一个30亿参数的模型,但它的表现就像它有两倍那么多,甚至击败了拥有70亿参数的模型。
1、训练设置
- SmolLM3看到了11.2万亿个标记。这是相当大的数据量。数据混合是分层的:网络内容、代码库、数学问题、推理任务。
- 然后他们做了大多数人都跳过的步骤:中期训练。1400亿个标记纯粹用于推理。之后:监督微调和APO(锚定偏好优化)以对齐。
这很重要,因为该模型不仅仅重复模式。它可以遵循逻辑,解决多步骤的问题,并且在这一规模下比通常更长时间保持主题。
2、扩展思考模式
你可以打开“思考”模式。它使模型逐步推理而不是直接得出答案。它实际上会影响任务如数学或研究生水平QA的表现。
如果你想要快速的答案:关闭它。
如果你想了解答案是如何得出的:打开它。
3、多语言性质
六种语言被正式支持:英语、法语、西班牙语、德语、意大利语、葡萄牙语。该模型在每种语言中都使用真实数据进行训练,而不是像许多其他模型那样仅进行“标记对齐”。
它也看到了少量的阿拉伯语、中文和俄语。那里的性能略有下降,但仍然优于同规模的大多数模型。
4、长文本,非常长的上下文
这个模型原生支持64k个标记。并且通过YaRN外推,它可以扩展到128k个标记而不会崩溃。这足以处理长文档、转录本、书籍甚至更多。
Llama3 8B在长上下文一致性方面仍然存在困难。SmolLM3,虽然只有3B,却不会。
5、工具调用支持
SmolLM3可以调用工具。你可以将工具作为JSON或代码样式提供给它。它可以调用函数,处理参数,并返回结构化的响应。
这使其可用于基本自动化、检索系统、API调用机器人,而无需包装器或第三方粘合代码。
基准测试
它正在基准测试中占据主导地位,轻松击败了一些大小是它两倍的模型
- GSM-Plus(数学):83.4
- GPQA(研究生推理):41.7
- 工具调用基准(BFCL):88.8
- Global MMLU(多语言QA):在顶级语言中处于中上水平
- LiveCodeBench v4(编程):30.0
- AIME 2025(数学奥林匹克级别):36.7(开启推理)
在很多这些任务中,它与Qwen 4B和Llama3 8B相抗衡。这不是营销。模型卡中的原始数据就是证明。
6、部署选项
SmolLM3可以在以下环境中运行:
transformersvLLMSGLangllama.cpp、ONNX、MLC用于本地/边缘设备
Hugging Face上有量化版本。不需要80GB的VRAM来运行。适合笔记本电脑、边缘设备或单GPU设置。
7、它适合做什么
很多事
- 构建代理的人
- 大规模摘要
- 长文档问答
- 代码推理
- 任何需要具有实际深度的小型模型的人都适用
不适合你的情况
- 你需要跨所有领域达到GPT-4级别的深度
- 你想要花哨的对话或精美的小谈话
- 你正在进行超出支持的六种语言的高强度多语言生成
8、如何使用SmolLM3?
权重是开源的,可在HuggingFace上获取。
代码也可以在这里找到
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tools = [
{
"name": "get_weather",
"description": "获取一个城市的天气",
"parameters": {"type": "object", "properties": {"city": {"type": "string", "description": "要获取天气的城市"}}}}
]
messages = [
{
"role": "user",
"content": "你好!今天哥本哈根的天气怎么样?"
}
]
inputs = tokenizer.apply_chat_template(
messages,
enable_thinking=False, # True 也可以,取决于你的选择!
xml_tools=tools,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt"
)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
9、结束语
SmolLM3是一个真正的小型模型。没有游戏。完整的训练堆栈是公开的。真实的推理。长上下文。工具调用。
没有API锁定。没有付费墙。没有虚假的“开放权重”噱头。
如果你正在寻找一个能完成工作的模型,它是这个范围内少数真正能实现的模型之一。
原文链接:SmolLM3 : The best small LLM for everything
汇智网翻译整理,转载请标明出处
