Stable-diffusion.cpp简明教程
本文教你如何在本地PC上使用stable-diffusion.cpp生成图像。好的部分是,它假设你没有NVIDIA GPU。

本文教你如何在本地PC上生成图像。好的部分是,它假设你没有NVIDIA GPU。
但也许你有一个强大的最新一代Intel芯片……所以有很大机会你有足够的能力来完成它。
如果你不相信我,只需检查一下这些数字
以下是不同硬件性能的快速概述,相同的设置和提示:
一个在巨大洞穴中建造的幻想城市,光滑的玻璃建筑,优雅的塔楼间走道,插画,下雨,黑暗而阴郁的灯光,数字艺术,油画,幻想,8k,艺术站上的趋势,详细
步骤 = 10
大小 = 512*256
采样 = euler_a

图像生成是生成式AI中最繁重的计算任务之一。如果你没有专用GPU,这看起来是不可能的任务。
如果我告诉你这是可能且简单的呢?
在过去我写过一篇教程:但几天前我尝试了一种完全不同的方法,使用了新的模型……这是完全可以做到的!
我在一台破旧的小型PC上进行了测试,内存为16Gb,没有专用GPU:虽然需要时间,但你可以做到。事实上,如果你有一个清晰的想法,这是值得的。
我还尝试用相同的设置在AI PC上运行它。
这是一个小型格式迷你PC,配备了32Gb内存和Intel Core Ultra AI芯片。这就是我用来测试StableDiffusion.cpp的设备
这就是我决定开始这一出版物的主要原因,所有关于OpenVINO的文章都将100%免费。
我将我的结果与其他两种硬件配置进行了比较:当然,速度差异是惊人的。拥有GPU改变了游戏规则,很多。
公平地说,新一代Intel AI PC确实是一个惊喜,值得购买。在接下来的文章中我将与大家分享我的结果。
不多赘述,让我们开始构建一个文本界面来生成图像吧!
1、过程概述
在我的第一次实验中,早在时,我使用了stable-diffusion-cpp-python的Python绑定。这很好,但有一个问题:
- Python绑定(一个库,用于在Python中与C++库进行繁重的通信)更新得相当慢
- 原始的C++库现在有了预编译的二进制文件
- 新模型的支持通过原始库得到保证,相当快
所以这次我采用了与LLM相同的方法:外部运行模型,并使用Python作为接口与AI模型交互。
2、什么是Stable Diffusion CPP?
你可能听说过这个名字与图像生成相关。事实上,Stability AI 随着Stable Diffusion的发布进入了公众视野。
Stable Diffusion是一个能够根据文本描述生成图像的人工智能(AI)模型。你可以在这里了解更多。
当用户开始使用SD和SDXL模型时,世界陷入了混乱:你可以想象!绘制或创作一幅图画所需的唯一技艺就是能够写出指令……
图像生成真的令人着迷:它让你觉得想象力没有限制,因为你几乎可以立即看到结果。
除非你想在你的计算机上实现它,那就不那么“立即”了……运行Stable Diffusion所需的硬件规格相当高要求:
- 一个具有6 GB RAM的NVIDIA GPU(尽管你可能可以使用4 GB RAM)
- SDXL需要更多的RAM来生成更大的图像。
- 你可以让AMD GPU工作,但它们需要一些调整
先锋Georgi Gerganov编写了一个纯C++的惊人库,可以在量化格式下运行LLM,这样你就可以在没有GPU的情况下运行它们,但需要CPU和足够的RAM:这个库称为llama.cpp。
遵循他的例子,其他出色的程序员改编了源代码,使其可用于Stable Diffusion模型,这就是@leejet的 stable-diffusion.cpp库,这个库后来甚至被移植到 stable-diffusion-cpp-python,我们将使用它来生成图像,即使我们的笔记本电脑配备不足。
3、准备工作
我们需要安装Python(我使用的是版本3.12)、stable-diffusion-cpp二进制文件和模型权重。
3.1 Python
希望你已经安装了Python:如果没有,可以从官方网站获取。
你需要一个新的项目目录,在那里我们将安装几个包并创建一个虚拟环境。
我强烈建议克隆我的GitHub仓库,这会使事情变得更容易。进入你的根目录(可能是Projects或Documents……)并在终端中运行:
git clone https://github.com/fabiomatricardi/StableDiffusionCPP-usage.git
cd StableDiffusionCPP-usage
# 创建虚拟环境
python -m venv venv
# 激活它
venv\Script\activate
# 安装包
pip install gradio Pillow
在同一文件夹中,你将找到已经包含的stable-diffusion-cpp二进制文件的ZIP文件:选择你的一个(见下一节)并简单地将其解压缩到项目目录中。
如果你想自己从头做:
创建一个新的项目目录(我的叫StableDiffusionCPP-usage),然后从那里创建并激活虚拟环境。之后安装以下两个包:
mkdir StableDiffusionCPP-usage
cd StableDiffusionCPP-usage
# 创建虚拟环境
python -m venv venv
# 激活它
venv\Script\activate
# 安装包
pip install gradio Pillow
现在你将不得不挑选并下载SD-cpp二进制文件并将其解压缩到项目目录中(见下一节)
3.2 StableDiffusion cpp二进制文件
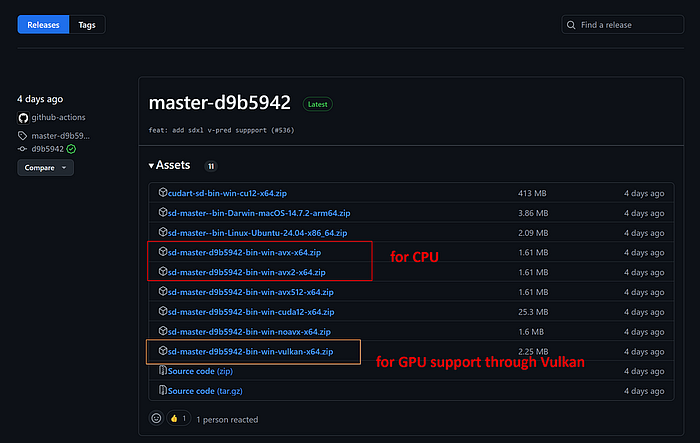
如前所述,官方仓库的一个惊人之处在于,每当创建一个新的主分支时,二进制文件也会随之发布。在上面的图片中,你可以看到几个操作系统支持,包括特殊版本:
- avx/avx2通常由所有现代CPU支持。这些是你下载如果没有专用GPU的话的ZIP文件
- cuda12/cudart是为NVIDIA GPU硬件准备的二进制文件
- vulkan是带有二进制文件的ZIP存档,支持Vulkan驱动程序。Vulkan是一种跨平台的行业标准,使开发人员能够使用相同的图形API针对各种设备
如果你安装了Vulkan,你将自动获得对专用(或集成)GPU的支持,而无需特定的Python库。例如,你可以使用Vulkan二进制文件即使在NVIDIA GPU上运行SD.CPP。
或者,如果你有一台Intel PC,它会识别你的GPU并提供访问权限,而无需安装任何其他内容!你可以在这里阅读更多信息。
我下载了AVX2版本(完全不使用GPU),但你可以使用Vulkan二进制文件:在这种情况下,在运行时,stable-diffusion-cpp将尝试将模型层的一部分卸载到GPU。
下载SD-cpp二进制文件并将其解压缩到项目目录中。
注意:如果你克隆了我的GitHub仓库,你将已经找到两个准备使用的ZIP归档文件
git clone https://github.com/fabiomatricardi/StableDiffusionCPP-usage.git
在这里,你只需要将ZIP文件解压缩到项目目录中。
3.3 扩散模型
扩散模型的最佳资源无疑是CivitAI。这里有指南、教程以及成千上万的模型、LoRa和示例。你可以免费注册并访问这些模型。
对于我们的教程,我将使用Lykon创建的DreamShaper版本8:在CivitAI仓库中有多个选项、版本,甚至LCM(潜在一致性模型)模型(能够在一步内生成图像)。
你可以从这里下载文件dreamshaper_8.safetensors
只需下载(1.9 Gb)到主项目目录中。
记住,如果你有GPU,必须下载Vulkan或CUDA二进制文件
完成上述步骤后,你应该在主目录中拥有以下文件和文件夹:
[img]
[venv]
#sd-master-d9b5942-bin-win-avx2-x64.zip
#sd-master-d9b5942-bin-win-vulkan-x64.zip
dreamshaper_8.safetensors
examples.txt
ggml.txt
README.md
sd.exe
stable-diffusion.cpp.txt
stable-diffusion.dll
_RUN-SDCPP.py
vulkan-shaders-gen.exe (如果你使用了Vulkan版本)
4、代码
我们安装了gradio和Pillow,但对于本教程来说,Pillow就足够了。这是一个著名的库,能够使用Python处理图像。我们将在下一篇文章中使用gradio。
首先我们导入主要的库:subprocess是运行终端命令所需,PIL是我们处理所有图像的魔法师。像往常一样,我还有一个生成随机序列的函数,用于文件名。
import subprocess
import random
import string
from datetime import datetime
from PIL import Image
from PIL.PngImagePlugin import PngInfo
def genRANstring(n):
"""
n = int 数字的字符长度
返回 -> str,生成n个随机字母数字字符的文件名
"""
N = n
res = ''.join(random.choices(string.ascii_uppercase +
string.digits, k=N))
print(f'Logfile_{res}.png 已创建')
return f'IMAGE_SDCPP_{res}.png'
因为这是一个简单的文本界面,我们将从用户那里获取输入:提示和步数。
注意,你需要提供一个没有换行符的提示(没有新行)。
fILENAME = genRANstring(5)
PROMPT = input('/IMAGINE ')
STEPS = input('步数:')
WIDTH = '512'
HEIGHT = '256'
print(f'正在保存使用dreamshaper_8生成的图像:{fILENAME}')
除了PROMPT和STEPS,我们将保持其他所有生成参数的值不变(有很多——我会把它们放在文章末尾)。
接下来的部分(虽然有很多行……但实际上是一条命令)是我们的Python作为终端命令行运行stable-diffusion-cpp二进制文件:
start = datetime.now()
mc = ['sd.exe',
'-m',
'dreamshaper_8.safetensors',
'--cfg-scale',
'5',
'--steps',
STEPS,
'-W',
WIDTH,
'-H',
HEIGHT,
'--sampling-method',
'euler',
'-p',
PROMPT,
'-o',
fILENAME]
res = subprocess.call(mc,shell=True)
delta = datetime.now() - start
print(f'完成时间:{delta}'
subprocess.call()方法需要每个标志和参数作为字符串列表的一部分。当我们调用该方法时,终端命令将被执行:
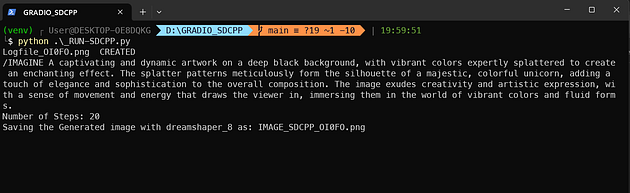
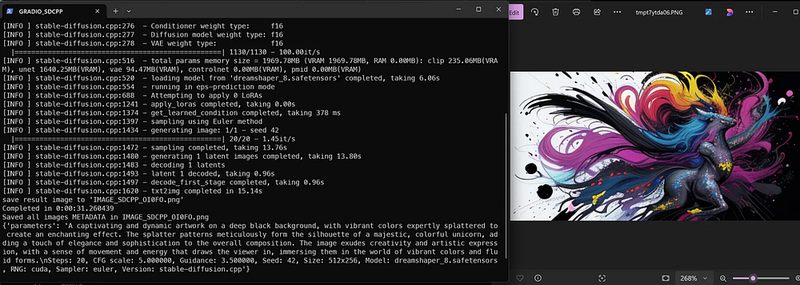
这里是如何在CPU上(在我的小型PC上测试)的日志看起来的:
[INFO ] stable-diffusion.cpp:195 - 从'.\dreamshaper_8.safetensors'加载模型
[INFO ] model.cpp:888 - 使用safetensors格式加载.\dreamshaper_8.safetensors
[INFO ] stable-diffusion.cpp:242 - 版本:SD 1.x
[INFO ] stable-diffusion.cpp:275 - 权重类型: f16
[INFO ] stable-diffusion.cpp:276 - 条件器权重类型: f16
[INFO ] stable-diffusion.cpp:277 - 扩散模型权重类型: f16
[INFO ] stable-diffusion.cpp:278 - VAE权重类型: f16
|==================================================| 1130/1130 - 125.00it/s
[INFO ] stable-diffusion.cpp:516 - 总参数内存大小 = 1969.78MB (VRAM 0.00MB, RAM 1969.78MB):clip 235.06MB(RAM),unet 1640.25MB(RAM),vae 94.47MB(RAM),controlnet 0.00MB(VRAM),pmid 0.00MB(RAM)
[INFO ] stable-diffusion.cpp:520 - 从'.\dreamshaper_8.safetensors'加载模型完成,耗时4.97秒
[INFO ] stable-diffusion.cpp:550 - 正在运行eps预测模式
[INFO ] stable-diffusion.cpp:682 - 尝试应用0个LoRA
[INFO ] stable-diffusion.cpp:1235 - 应用lora完成,耗时0.00秒
[INFO ] stable-diffusion.cpp:1368 - 获取学习条件完成,耗时1572毫秒
[INFO ] stable-diffusion.cpp:1391 - 使用Euler方法进行采样
[INFO ] stable-diffusion.cpp:1428 - 生成图像:1/1 - 种子 42
|==================================================| 10/10 - 477.33s/it
[INFO ] stable-diffusion.cpp:1466 - 采样完成,耗时4613.73秒
[INFO ] stable-diffusion.cpp:1474 - 生成1个潜像完成,耗时4613.85秒
[INFO ] stable-diffusion.cpp:1477 - 解码1个潜像
[INFO ] stable-diffusion.cpp:1487 - 潜像1解码完成,耗时490.42秒
[INFO ] stable-diffusion.cpp:1491 - 解码第一阶段完成,耗时
当sd.exe完成其工作后,我们将收集元数据并将其保存在PNG文件中。最后我们打开图像并显示它。
print(f'完成时间:{delta}')
metadata = PngInfo()
metadata.add_text("提示", PROMPT)
metadata.add_text("图像大小", f'WxH: {WIDTH} x {HEIGHT}')
metadata.add_text("步数", f'步数:{STEPS} 采样方法:euler')
metadata.add_text("生成时间", f'{str(delta)}')
targetimage = Image.open(fILENAME)
targetimage.save(fILENAME,pnginfo=metadata)
print(f'已保存所有图像元数据:{fILENAME}')
print(targetimage.text)
targetimage.show()
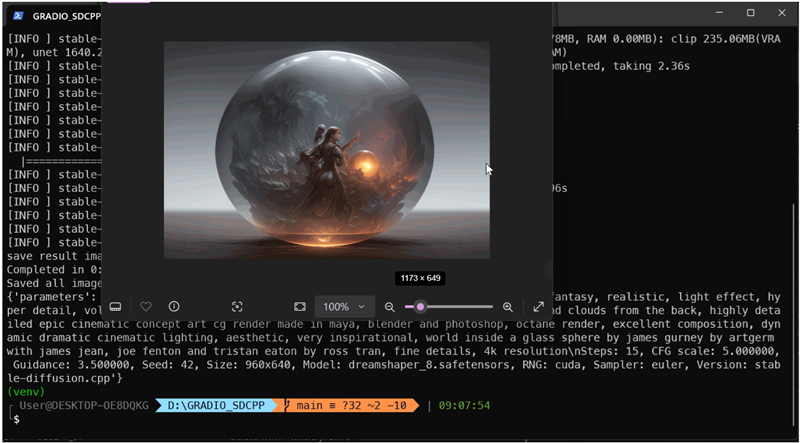
就是这样,真的。上述提示的结果如下:
5、生成的图像和性能
应用程序运行得很好。根据你的处理器或GPU,生成一张图像可能需要相当长的时间。例如,紧接着本文的目录,是在CPU上仅用了……48分钟生成的!
这是因为有几个因素需要考虑:
- 图像尺寸越大(在这个例子中是1344*768),生成图像所需的时间就越长
- 步数也是一个因素:使用LCM模型,4或5步足以生成高质量图像。对于普通的扩散模型,至少需要15步
- 如果图像尺寸非常大,可能会发生你的GPU无法处理的情况。实际上,图像尺寸等于LLM的上下文窗口。联想Legion S7搭载RTX 2060(8GB显存)在我要求生成1344*768图像时崩溃了。
6、结束语
扩散模型不再是GPU用户的奢侈品。Stable Diffusion CPP是每个人丰富教育内容的绝佳入口,通过AI生成的图像。
一旦你找到了自己的风格,你可以将其应用于所有未来的图像!
原文连接:Why most AI enthusiasts overlook this crucial tool for Intel hardware
汇智网翻译整理,转载请标明出处
