拯救量化LLM的准确性
使用量化 LoRA (QLoRA) 对大型语言模型进行微调可以有效更新原始模型权重,但在将 LoRA 权重与量化基础权重合并时,最初可能会降低准确性。

使用量化 LoRA (QLoRA) 对大型语言模型进行微调可以有效更新原始模型权重,但在将 LoRA 权重与量化基础权重合并时,最初可能会降低准确性。解决方案是首先对这些层进行反量化,确保合并保留模型的微调性能。这种方法在合并 LoRA 权重后保持准确性,同时保持模型轻量级以实现资源高效的推理。
1、故事
在微调大型语言模型 (LLM) 时,目标是调整权重以更好地捕获数据中的模式。但是,由于计算成本高、内存需求大以及过度拟合的风险(尤其是在数据有限的情况下),对具有大量参数的模型进行全面微调可能具有挑战性。
因此,你正在考虑根据自己的数据对 LLM 进行微调。也许你希望它掌握你所在领域的特定模式,或者你可能有一个下游任务,需要该模型胜过现成的替代方案。
你已经选择了模型、准备好了数据并启动了 GPU 机器,一切准备就绪,可以开始编码和训练了。但有一个问题:你的资源不是无限的,时间也非常紧迫。
你需要一种有效的微调方法,而又不能过多地影响性能。
这时你偶然发现了 LoRA(低秩自适应)。使用 LoRA,你可以避免训练整个模型的权重,而是专注于更节省资源的微调方法。
你尝试了一下,但很快遇到了可怕的内存不足 (OOM) 错误。你开始寻找替代方案,这时你发现了 QLoRA ,这种方法既遵循 LoRA 的效率,又量化了模型权重,使它们在微调时可以轻松地安装在单台机器上。
问题解决了!
或者你是这么想的。
使用 QLoRA 进行训练后,你可以运行评估并看到很好的结果。你保存了模型;将 LoRA 权重与原始权重合并,将学习到的适应性整合为一个统一的模型。这个合并步骤至关重要,它确保最终模型无需依赖额外的 LoRA 模块即可部署或存储。当你重新加载它并运行另一次评估时,结果令人震惊。无论你以更高还是更低的精度加载它,准确度都会下降。
如果这听起来很熟悉,或者你正在探索类似的路径,请继续阅读。本文将指导你完成在使用 QLoRA 进行微调时保持准确度所需的确切步骤,同时实现比原始模型轻得多的内存占用。
1、LoRA 微调的简要介绍
2021 年推出的低秩适应 (LoRA) 提出了一种替代完全微调的有效方法。LoRA 不会在微调期间更新所有模型权重,而是只修改一小部分参数,同时保持模型性能。
核心概念包括冻结预训练模型的原始权重,并将可训练的低秩分解矩阵注入选定的层。只有这些新矩阵经过训练,从而减少内存和计算负载。
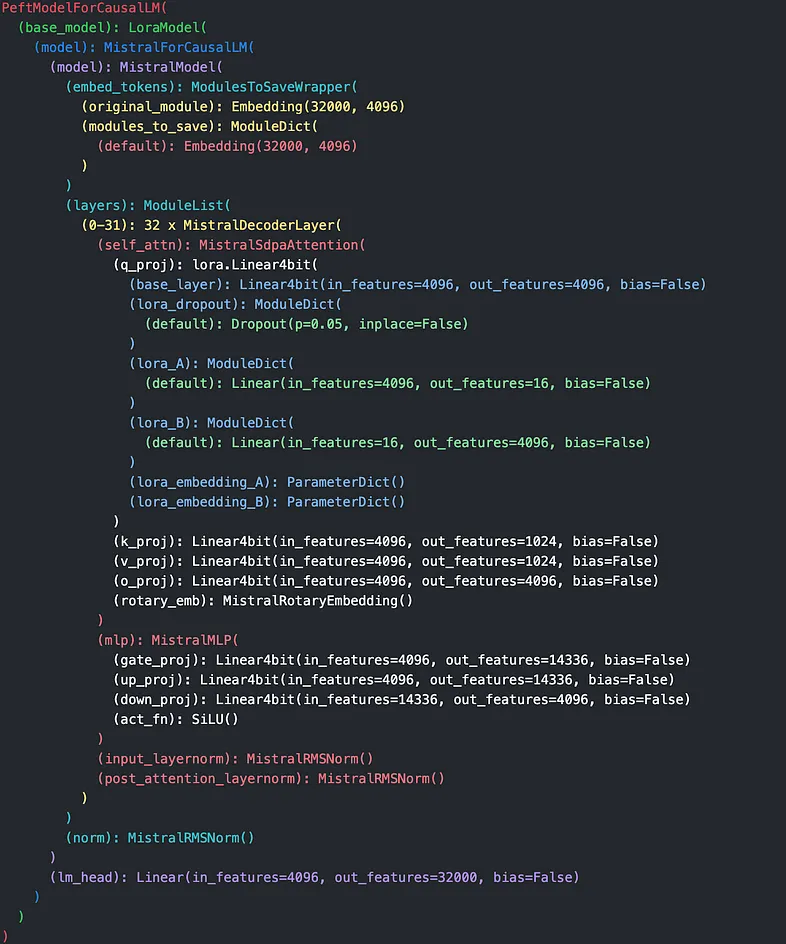
例如,考虑 mistral-7b-instruct-v0.1 模型,这是我们在本文中的重点(尽管这些方法也适用于其他模型)。当你从 HuggingFace 加载此模型并检查其架构(图 1)时,你会注意到多个线性层(黄色)。
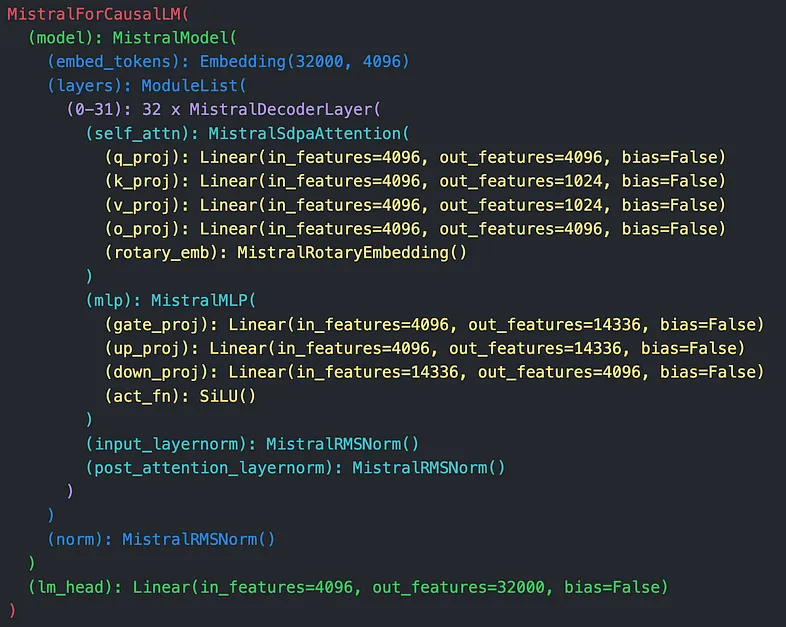
每个线性层代表一个形状为 ℝᵐ * ⁿ 的矩阵 W,其中 𝓂 是层的输入特征,𝓃 是输出特征。 LoRA 将此矩阵分解为两个较小的矩阵 A 和 B,其维度由用户选择的超参数 𝓇 等级决定。此等级 𝓇 比 𝓂 或 𝓃 小得多,允许新矩阵的维度仅为原始大小的一小部分,因此大大减少了训练所需的资源。
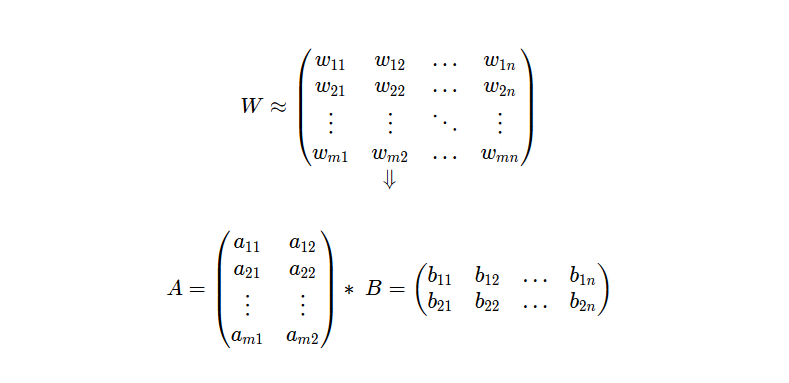
为了说明和简单起见,让我们使用 PEFT 将 LoRA 应用于单个线性层 q_proj。如图 1 所示(蓝色和绿色),你将看到 q_proj 现在包含其他组件:
- lora_dropout
- lora_a 和
- lora_b
lora_b
原始 q_proj 层具有 in_features=4096 和 out_features=4096,使其形状为 (4096, 4096)。
对于等级为 16 的 LoRA 操作, lora_a 和 lora_b 的维度调整如下:
- lora_a 的 in_features = 4096 和 out_features = 16。
- lora_b 的 in_features = 16 和 out_features = 4096。
当 lora_a 乘以 lora_b 时,得到的张量维度为 (4096, 4096),与原始 q_proj 层的形状匹配。这种匹配是故意的,以确保与原始模型架构兼容。虽然 LoRA
没有明确使用奇异值分解 (SVD),而是受到低秩近似原理的启发,其中高维张量可以通过较小的低秩张量的乘积来近似。
为什么采用这种方法?
简而言之,它显著减少了可训练参数的数量,将训练更新重点放在 lora_a、lora_b 和 lora_dropout 上,同时保持原始模型层冻结。一旦 LoRA 操作完成,lora_a、lora_b 和 lora_dropout 的组合乘积将作为低秩更新添加回 q_proj。由于此更新与原始矩阵 W 共享相同的 (4096, 4096) 维度,因此它可以无缝集成。
该技术是一种减少训练要求、节省计算资源的有效方法。然而,随着大型语言模型的不断增长,即使这种方法也可能不足以避免 GPU 内存耗尽。为了进一步缓解这个问题,提出了一种量化方法,压缩模型参数以更有效地管理内存。
2、LLM 中的量化简介
量化降低了基本模型权重的精度,同时努力不损失太多的准确性。通常,模型以 FP32(32 位浮点格式)存储。通过量化,可以将模型保存为 FP16、BF16、INT8、NF4 等。这些格式中的每一种都在精度和内存效率之间进行了权衡,低位格式通常消耗较少的内存,但可能会牺牲一些模型准确性。
量化类型包括:
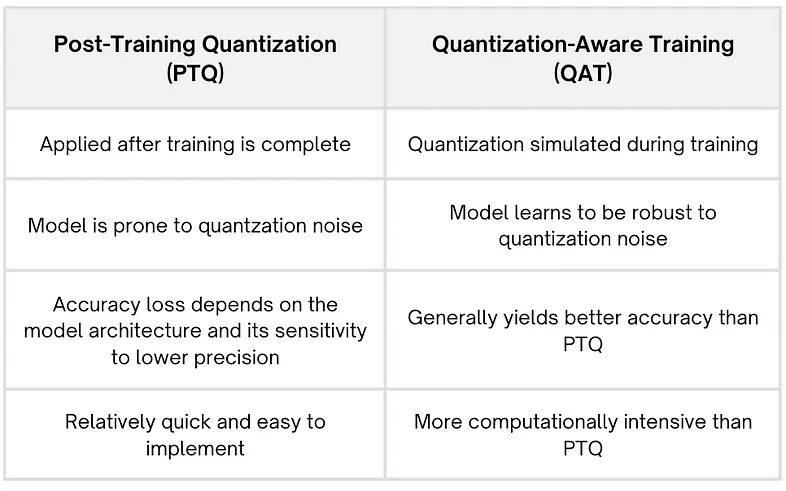
- 训练后量化 (PTQ)
PTQ 在模型完全训练后应用。它涉及将模型的权重和激活转换为较低精度的格式,而无需在量化权重时重新训练模型。此方法易于实施,但可能会导致性能下降:
- 量化感知训练 (QAT)
QAT 在训练过程中结合了量化效果。QLoRA 属于这一类。这种方法允许模型适应降低的精度,通常比 PTQ 具有更好的性能。
下表总结了两者之间的差异:
为什么要量化?
量化有两个主要好处:更小的模型尺寸和更少的内存使用量。
- 更小的模型尺寸:量化模型占用更少的空间,使其更易于存储、传输和跨设备部署。
- 减少内存消耗:较低精度的格式减少了训练和推理期间的内存需求,使模型能够在内存有限的设备上运行。
值得注意的是,尽管内存使用量减少,量化也可能导致更长的推理时间。要深入了解这种权衡,你可以参考 LitGPT 提供的基准测试结果,这些结果显示了量化对内存使用量和推理速度的影响。我们还观察到量化模型的推理速度更长。
量化技术
HuggingFace 在各种硬件平台上支持多种量化技术,包括 CPU、CUDA GPU、RoCm GPU、Metal(Apple Silicon)。他们提供了一个兼容性表(图 3),以便选择技术。
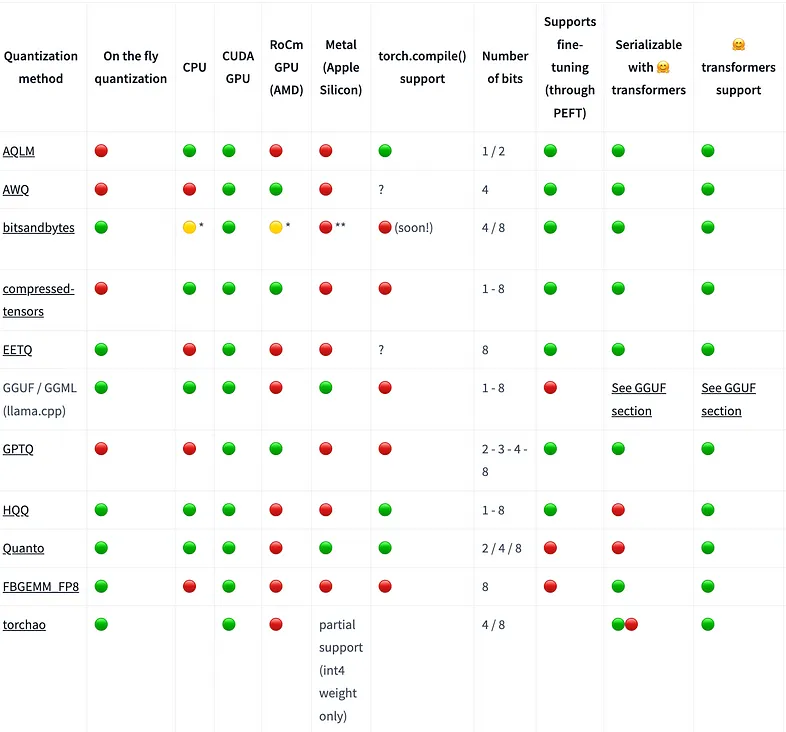
有关详细信息,您可以参考这篇文章 。
3、QLoRA:平衡效率和准确性
量化 LoRA 微调 (QLoRA) 提供了一种微调大型语言模型的方法,它将 LoRA 在训练参数子集方面的效率与基本权重的量化相结合,从而节省了微调期间的内存。
让我们回到使用 QLoRA 进行微调时我们的模型结构的样子(图 4):
关注蓝线,每层包含一个量化为 4 位的 base_layer(由 Linear4bit 模块表示),以及保持高精度的 lora_A 和 lora_B 层(由绿色的 Linear 模块表示)。这种结构允许高效训练,同时保持对 LoRA 更新至关重要的精度。
在许多情况下,由于前向传递中权重的精度较低,你可能会预计模型性能在微调期间会下降。但是,经过微调后,无论 LoRA 权重是否合并回基权重,推理结果都应该是一致的。在非合并模型中,输入会同时通过基础层和 LoRA 层,而在合并模型中(在“卸载”过程中移除 LoRA 层后),输入会通过具有组合权重的单个层,理论上会产生相同的输出。不幸的是,情况并非总是如此。在以下部分中,我们将探讨为什么错误地合并 LoRA 权重有时会导致意外的准确率下降以及如何解决此问题。
4、合并和卸载
如果我们直接使用此模型进行推理,则输入 token 将被嵌入并通过 Transformer 的多个层,包括量化基础层和 LoRA 层。最后一层将为每个 token 生成输出嵌入,然后对其进行处理以生成预测 token。此过程,然后进行解码,产生最终的文本输出。
但是,为了简化推理,我们希望“合并和卸载”LoRA 层。在此步骤中,我们通过线性变换将 LoRA 层(lora_A 和 lora_B)合并到基础层,然后移除(或“卸载”)LoRA 层,因为它们不再需要用于推理。
合并过程遵循以下公式:
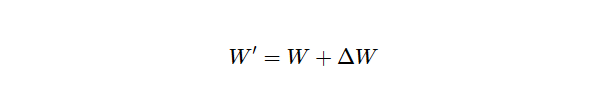
其中:
- W 是原始的、以高精度冻结的权重矩阵。
- ΔW 是模型在微调过程中学习到的 LoRA 调整矩阵,表示为两个低秩矩阵 Α 和 Β 的乘积。

合并过程转换为:
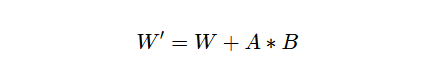
这里,W′ 成为更新后的权重矩阵,它结合了原始权重和 LoRA 调整,将替换原始基础层权重 W。
在推理过程中,模型将在前向传递中使用这个合并的权重矩阵 W′。 合并后,我们现在可以安全地丢弃 LoRA 层,这就是所谓的“卸载”步骤。
下面是一个代码示例,说明了基本但“不准确”的合并和卸载函数可能是什么样子:
import torch
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def calculate_lora_weights(
rank: int, lora_alpha: float, lora_A: torch.Tensor, lora_B: torch.Tensor
) -> torch.Tensor:
"""
Computes the LoRA (Low-Rank Adaptation) weights by scaling the matrix product
of LoRA A and B matrices.
Args:
rank (int): The rank (r) used in LoRA.
lora_alpha (float): Scaling factor for LoRA.
lora_A (torch.Tensor): LoRA A matrix.
lora_B (torch.Tensor): LoRA B matrix.
Returns:
torch.Tensor: The scaled LoRA weights.
"""
scaling_factor = lora_alpha / rank
logger.debug(f"Calculating LoRA weights with scaling factor: {scaling_factor}")
return (lora_B @ lora_A) * scaling_factor
def merge_lora_weights(
base_layer: torch.nn.Module,
finetuned_layer: torch.nn.Module,
rank: int,
lora_alpha: float,
) -> torch.nn.Module:
"""
Merges the base pretrained weights with LoRA weights into the finetuned layer.
Args:
base_layer (torch.nn.Module): The base pretrained layer.
finetuned_layer (torch.nn.Module): The LoRA finetuned layer.
rank (int): The rank (r) used in LoRA.
lora_alpha (float): Scaling factor for LoRA.
Returns:
torch.nn.Module: The finetuned layer with LoRA weights merged.
"""
logger.info("Merging LoRA weights into the finetuned layer.")
# Extracting input/output features and weights
input_features = finetuned_layer.lora_A.default.in_features
output_features = finetuned_layer.lora_B.default.out_features
logger.debug(f"Input features: {input_features}, Output features: {output_features}")
lora_A_weight = finetuned_layer.lora_A.default.weight
lora_B_weight = finetuned_layer.lora_B.default.weight
logger.debug(f"LoRA A shape: {lora_A_weight.shape}, LoRA B shape: {lora_B_weight.shape}")
# Calculate the LoRA weight matrix
lora_weights = calculate_lora_weights(rank, lora_alpha, lora_A_weight, lora_B_weight)
# Merge LoRA weights with base weights
pretrained_dtype = finetuned_layer.base_layer.weight.data.dtype
with torch.no_grad():
logger.info("Adding LoRA weights to the pretrained base layer.")
base_weight = finetuned_layer.weight
finetuned_layer.weight.data += lora_weights.to(
device=base_weight.data.device, dtype=pretrained_dtype
)
logger.info("LoRA weights successfully merged.")
return finetuned_layer
def unload_model(model: torch.nn.Module) -> torch.nn.Module:
"""
Unloads the model to free resources or return a reduced state.
Args:
model (torch.nn.Module): The input model to be unloaded.
Returns:
torch.nn.Module: The unloaded model.
"""
logger.info("Unloading the model.")
return model.unload()5、将基础模型权重与 LoRA 层合并的错误方法
前面的代码演示了一种常见但不正确的合并 LoRA 层的方法,这导致合并前和合并后的模型质量存在差异表示。
理论上,将 LoRA 层与基础模型合并不应影响推理质量,因为它本质上是一种线性变换。然而,许多开发人员依赖现成的 merge_and_unload 函数,例如 Hugging Face 的实现。虽然这些函数遵循相同的合并逻辑 - 将 A * B LoRA 调整重新添加到 base_layer 权重中 - 但直接在量化模型上使用它们会导致微调模型的质量下降,与使用未合并的层进行推理相比。
量化模型上的基本合并问题
这里发生的事情是,我们将高精度 LoRA 调整合并到 4 位量化基础层中。为了说明为什么这种方法有问题,让我们来看一个简单的例子。
首先,让我们生成一个随机的 float32 数字,我们将其称为 𝒮:
import numpy as np
s = np.float32(np.random.uniform(-1, 1))
print("S:", s)假设 𝒮 等于 -0.22289008。
接下来,让我们将 𝒮 量化为 4 位精度,就像我们在模型量化中需要做的那样。
我们将遵循均匀量化,其中输入序列的范围被划分为多个等距区域。这是使用以下公式对 𝒮 进行直接的标准化和缩放。
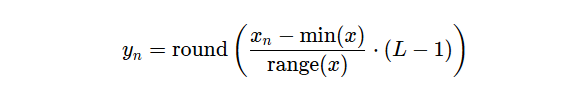
- 𝓎ₙ 是量化序列
- 𝓍ₙ 是输入序列
- L 是按 2ᵇ 计算的量化级别,其中 b 是用于量化的位数。
假设我们的量化范围是 -1 到 1,采用 4 位量化(16 级 (²⁴)),我们将得到:
quantization_levels = 16
min_val, max_val = -1.0, 1.0
quantized_s = np.round((s - min_val) / (max_val - min_val) * (quantization_levels - 1))
print("Quantized S:", quantized_s)量化后,Quantized 𝒮 为 6.0,表示基础模型权重的缩放值的量化版本。
现在,假设我们有第二个 float32 值 G,这是使用 LoRA 进行微调的结果:
g = np.float32(np.random.uniform(-1, 1))
print("G:", g)假设 G 等于 0.8382505。
使用基本的合并方法,我们会将 G(以其高精度格式)直接添加到量化的 𝒮 (6.0) 中,从而得到合并后的权重 6.8382505。然而,由于该结果结合了精度差异很大的值,因此无法准确捕捉真正的权重调整。
6、正确合并:去量化优先方法
为了正确处理这个问题,我们应该先将𝒮去量化(量化的逆过程)恢复到其原始的float32精度,然后再进行合并,如下所示:
dequantized_s = (quantized_s / (quantization_levels - 1)) * (max_val - min_val) + min_val
print("Dequantized S:", dequantized_s)对于这个随机生成的数字,去量化后的𝒮大约为-0.1999996。
现在,当我们合并𝒮和G时,我们得到0.6382509,与基本合并结果6.8382505有显著差异
让我们探索这种去量化优先方法如何应用于具有冻结的4位量化基础层和高精度float32 LoRA层的模型,如下图5所示。
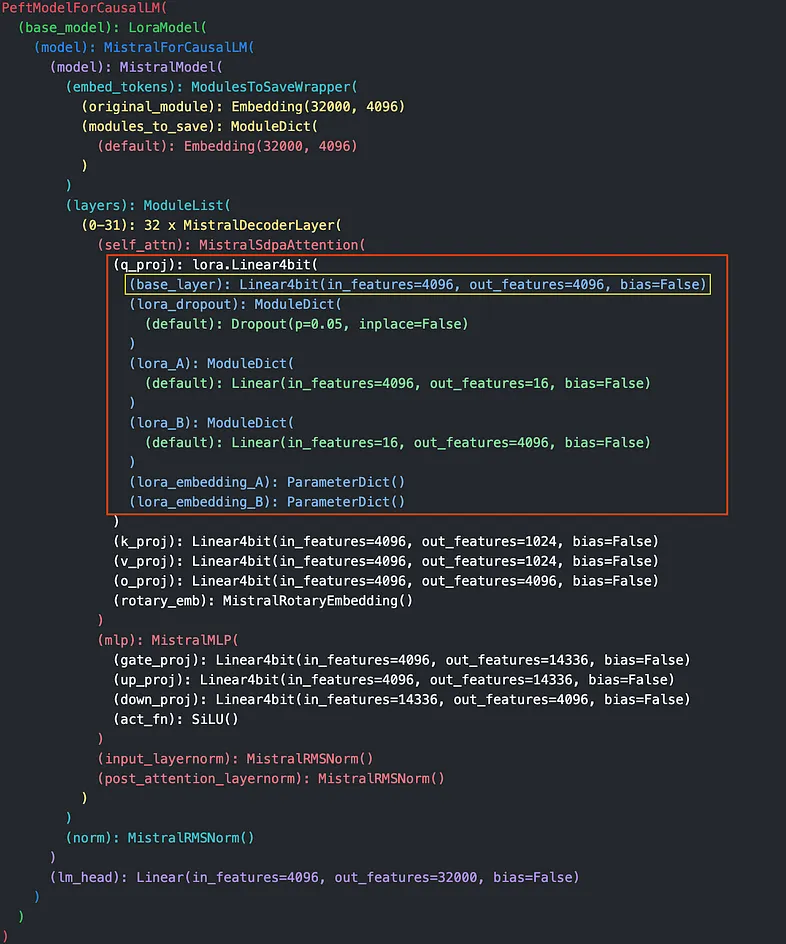
在此模型中,我们需要迭代其层,当遇到量化为 4 位的层时,将其反量化回 float32。对于我们的模型,需要进行此反量化的特定层在图中黄色框中突出显示。
反量化优先方法中的步骤:
- 识别量化层:循环遍历每个层并检查它是否是量化层,如 bnb.nn.Linear4bit 实例所示。
- 反量化权重:对于每个量化层,从 quant_state 检索其量化信息并使用 bnb. functional.dequantize_4bit 将 4 位权重转换为更高的精度。
- 创建具有反量化权重的新层:初始化一个新的 torch.nn.Linear 层,其输入和输出大小与原始 4 位层相同,然后将反量化权重分配给这个新层。
- 替换旧层:使用 peft.utils 中的 _get_submodules 定位目标层的父模块,然后用新的高精度模块替换旧的量化层。
import bitsandbytes as bnb
from peft.utils import _get_submodules
import torch
import copy
import logging
from typing import Union
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def dequantize_model(
model: torch.nn.Module,
dtype: torch.dtype = torch.float32,
device: str = "cuda"
) -> torch.nn.Module:
"""
Converts all Linear4bit layers in the given model to standard PyTorch Linear layers
with dequantized weights.
Args:
model (torch.nn.Module): The input model containing quantized layers.
dtype (torch.dtype): The target data type for the dequantized weights (default: torch.float32).
device (str): The target device for the new layers (default: "cuda").
Returns:
torch.nn.Module: The model with Linear4bit layers replaced by standard Linear layers.
"""
logger.info("Starting dequantization process for the model.")
layer_count = 0 # To count how many layers are dequantized
with torch.no_grad():
for module_name, module_instance, in model.named_modules():
if isinstance(module_instance, bnb.nn.Linear4bit):
logger.info(f"Dequantizing layer: {module_name}")
# Deep copy the quantization state to preserve original module properties
quantization_state: dict = copy.deepcopy(module_instance.weight.quant_state)
logger.debug(f"Quantization state for layer {module_name}: {quantization_state}")
# Dequantize the 4-bit weights and convert them to the desired dtype
dequantized_weights: torch.Tensor = bnb.functional.dequantize_4bit(
module_instance.weight.data,
quant_state=quantization_state,
quant_type="nf4"
).to(dtype)
logger.debug(f"Dequantized weights shape for layer {module_name}: {dequantized_weights.shape}")
# Create a new Linear layer with the dequantized weights
new_linear_layer: torch.nn.Linear = torch.nn.Linear(
in_features=module_instance.in_features,
out_features=module_instance.out_features,
bias=False,
dtype=dtype
)
new_linear_layer.weight = torch.nn.Parameter(dequantized_weights)
new_linear_layer.to(device=device, dtype=dtype)
# Replace the original module with the new one in the model
parent_module: torch.nn.Module
target_module: Union[torch.nn.Module, None]
target_name: str
parent_module, target_module, target_name = _get_submodules(model, module_name)
setattr(parent_module, target_name, new_linear_layer)
logger.info(f"Replaced {module_name} with dequantized Linear layer.")
layer_count += 1
logger.info(f"Dequantization process completed. Total layers dequantized: {layer_count}")
return model运行此函数后,基础模型将完全去量化,从而可以准确地与高精度 LoRA 层合并。
检查合并和卸载后的模型结构,我们会看到 LoRA 层消失,基础层以未量化的形式出现,如图 6 所示。
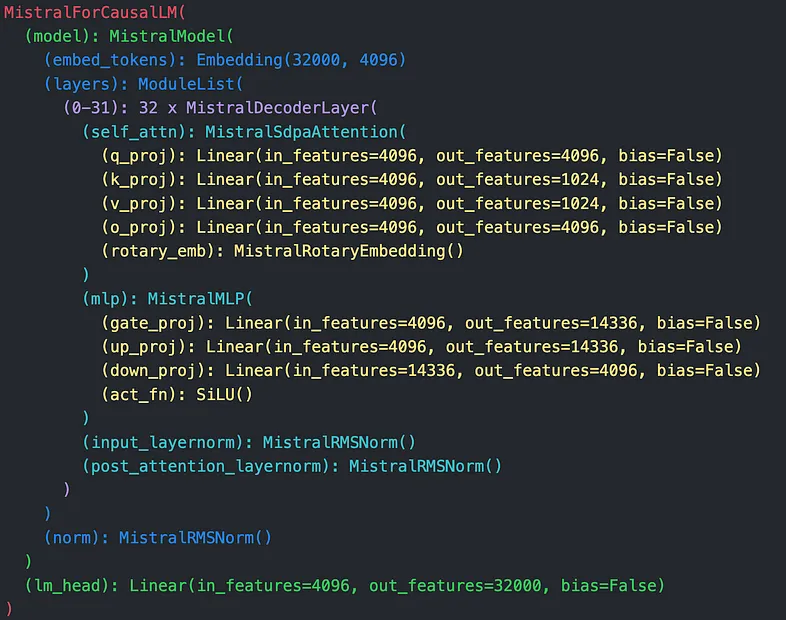
合并后,可以以高精度或低精度保存和重新加载模型,从而保留微调期间实现的质量。
7、结束语
量化 LoRA (QLoRA) 通过将量化基础权重与 LoRA 调整相结合,能够在有限的资源上对大型模型进行高效微调。将 LoRA 调整直接合并到量化层中可能会降低准确性由于精度不匹配而导致的。解决方案是先进行去量化,先对基本权重进行去量化,然后合并 LoRA 更新,在不牺牲内存效率的情况下保持准确性。这种方法保持了微调的性能,使 QLoRA 成为资源受限环境的理想选择。
原文链接:Stop Losing Accuracy after LLM Quantization!
汇智网翻译整理,转载请标明出处
