Grep与语义搜索的细微差别
Cursor发布了一篇博客,介绍了他们如何结合向量搜索和grep使用。谁曾想到会有这样的细微差别!
两年前,RAG(检索增强生成)意味着向量数据库和嵌入模型。现在,Claude Code、Codex、Cline等通过使用grep、bash工具和老式的推理方法,使一种无向量的方法变得流行起来。如果你相信Twitter上的常规智慧,那么你可能会认为向量是多余的,而使用grep的代理搜索1才是你需要的一切。
直到Cursor发布了一篇博客,介绍了他们如何结合向量搜索和grep使用。谁曾想到会有这样的细微差别!
1、一个非常人为的例子
我对代理搜索的最初反应是(天真的)不屑一顾。浪费计算资源!为什么在你有紧凑且高效的嵌入模型时还要用你的辛苦赚来的Jenson Bucks?这种无向量的方法显然有效。它什么时候不起作用?它是否总是优于向量?
所以我建立了一个非常愚蠢的测试环境。我将自然问题语料库中的每一行拆分出来,并保存为文本文件。对于每个查询,我删除了停用词,并用grep查找所有包含剩余关键词之一的文档2。
简单!但很慢3。
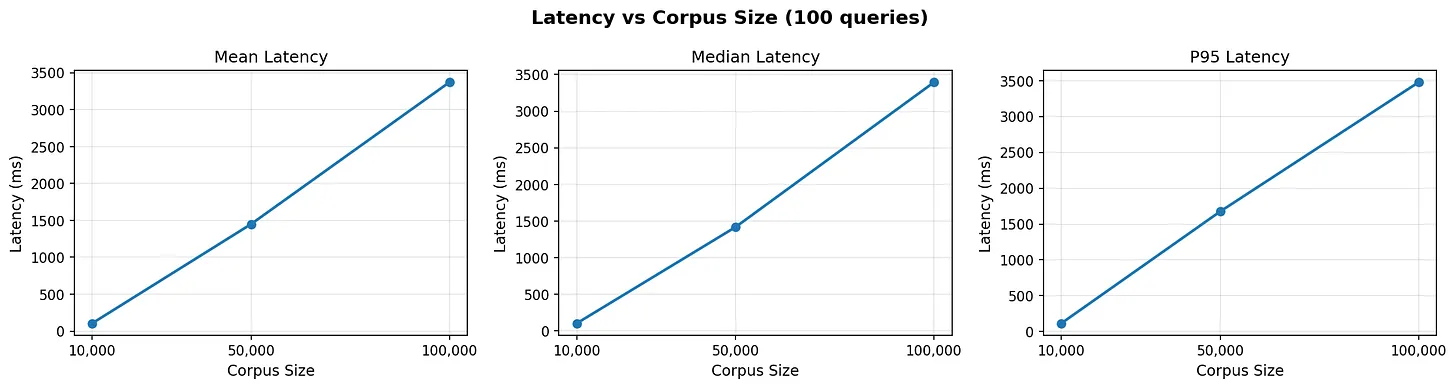
延迟似乎随着索引大小线性增长,在我的Macbook上比numpy要慢得多。
不出所料,仅使用查询中出现的关键词显示了较差的性能。我们没有获得嵌入的软匹配和灵活性。只有当查询和文档之间有确切的关键词匹配时,我们才能找到正确的文档。
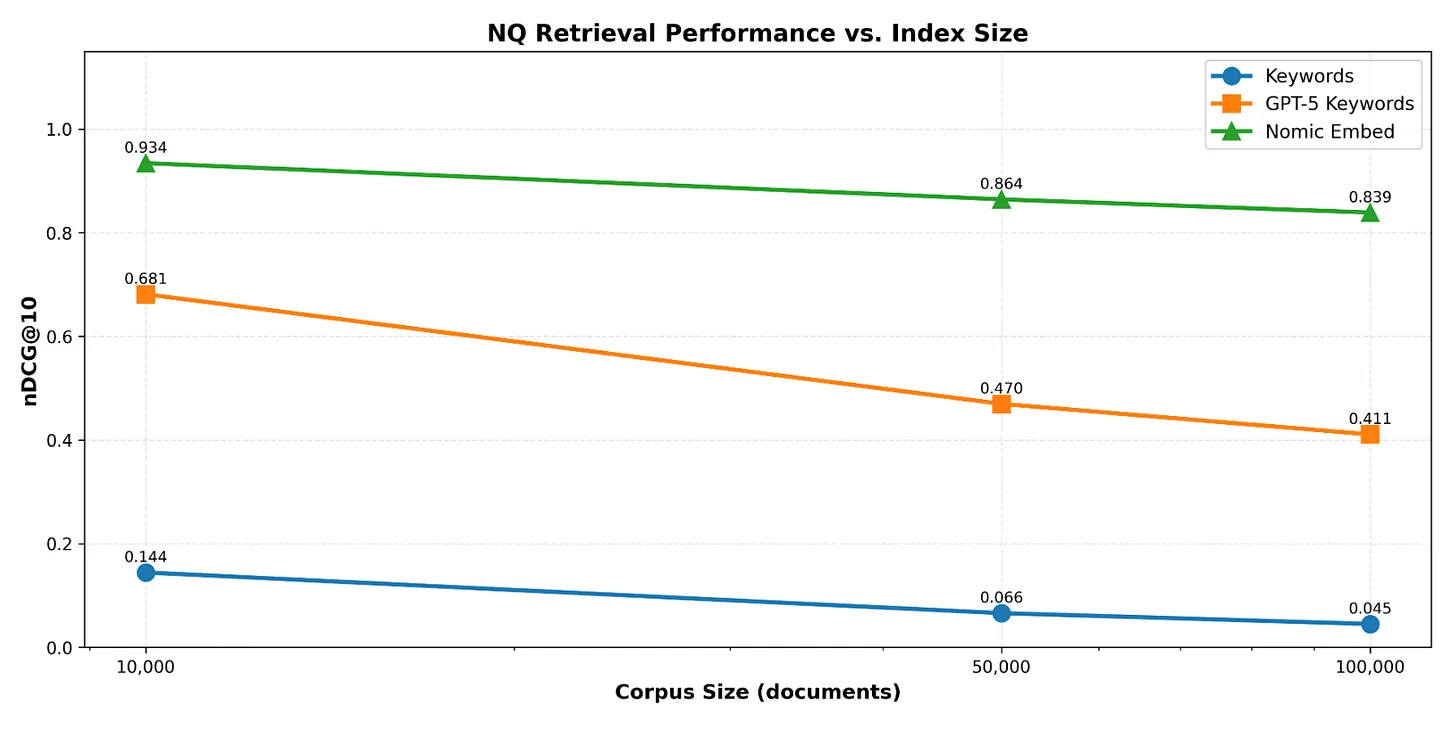
但是使用像gpt-5-mini这样的廉价模型根据查询返回相关关键词,几乎使性能提高了10倍4
那么grep有什么用呢?对于已知或容易推导出的关键词的确切匹配5。但这些关键词并不总是已知的。
2、RAG已死……长生不老RAG?
与numpy向量搜索相比,grep要慢得多。但嵌入模型收敛到一个语义标记的集合,并且对于训练数据之外的查询没有太多灵活性。
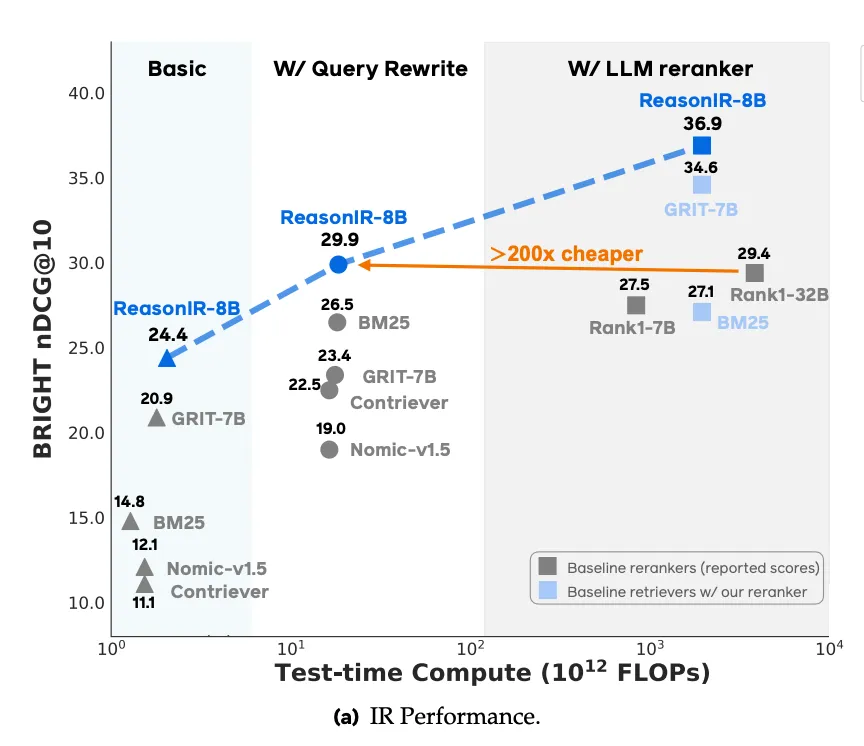
以BRIGHT基准为例:许多模型已经转向包括某种重写和扩展。ReasonIR表明,使用扩展查询6和使用LLM重新排序7可以提高基线性能。
简而言之,当你使用grep+关键词而不是嵌入时,你在延迟和令牌上做了交易,以换取灵活性。
但什么时候应该使用其中任何一个呢?
Seconds描述得非常清楚:
如果变量或管道的特定阶段的名称不是显而易见的,但你可以引用它的某个间接方面,嵌入会比grep更接近你。
3、Cursor的嵌入模型
Cursor的嵌入模型似乎在他们的内部Cursor Context Bench上提高了所有模型的性能。
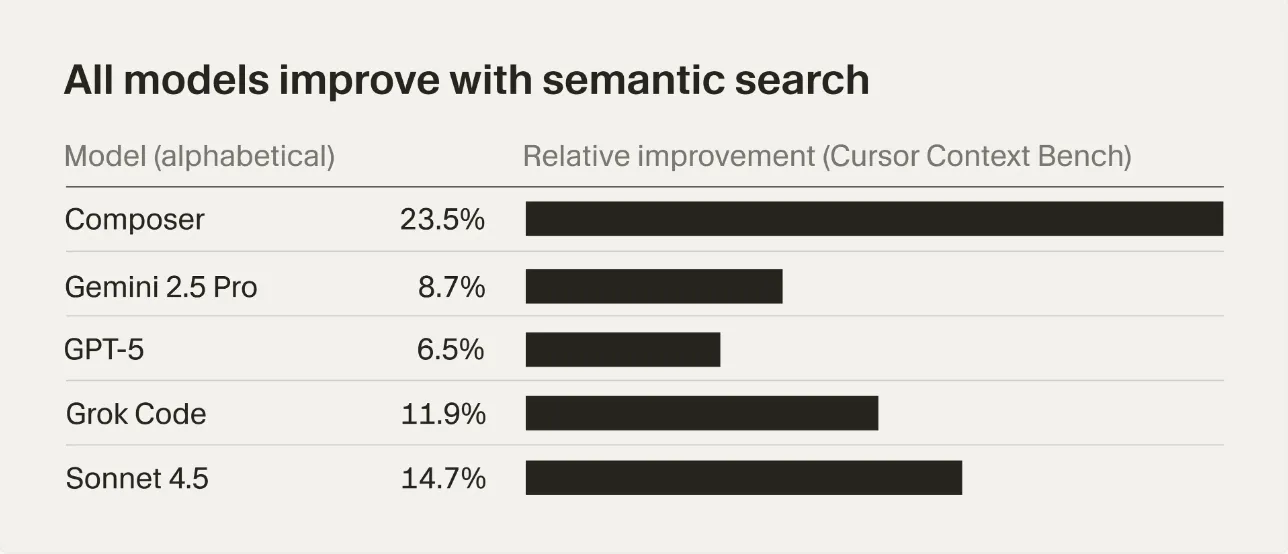
那它与其他常规代码嵌入模型有什么不同?他们利用丰富的用户代理交互:
我们将这些跟踪提供给LLM,该LLM对每一步最可能有用的内容进行排序。然后,我们训练我们的嵌入模型,使其相似度评分与这些LLM生成的排序相一致。这创建了一个反馈循环,使模型能够从代理实际处理编码任务的方式中学习,而不是依赖通用代码相似性。
利用这些跟踪(扩展查询),他们训练嵌入模型以检索由使用grep和文件读取工具的代理找到的文档。这与ReasonIR非常相似!虽然他们可能没有明确建模查询/关键词扩展,但通过跟踪训练可以从中提取相关信息。
对于嵌入模型来说,显式学习查询扩展还是隐式地通过挖掘正确的跟踪来学习,哪种更好?也许SPLADE是另一种选择。谁知道呢,但尝试一下会很有趣 :)
归根结底,比较grep与语义搜索缺少上下文。代理搜索通过将嵌入模型的已学习语义卸载到LLM来提供灵活的检索。这也使得在任何代码库中使用grep变得简单。你不再需要维护索引,担心任何潜在的安全影响,或者考虑如何最佳地对文件进行分块以供你的嵌入模型使用。然而,我认为代理搜索展示了嵌入模型可以也应该改进的地方。
1 - “with grep”在这里承担了很多繁重的工作
2 - 功能上,我这样做了 f”rg -i -c {‘|’.join(query)}”。文档是按每个单词的计数“评分”的。因为这是一个玩具示例,我没有费心进行任何评分归一化。如果我们想要的话,可以使用BM25
3 - Cognition最近为更快(和并行)的代理检索训练了专用模型。
4 - 我意识到这个数据集非常受欢迎,可能不是最公平的比较。
5 - 然而,嵌入仍然是连续领域的首选方式
6 - 值得注意的是,模型本身不会重写查询
原文链接:On the Lost Nuance of Grep vs. Semantic Search
汇智网翻译整理,转载请标明出处
