TimesFM时间序列基础模型
我们能否为时间序列学习一个基础模型,并用聊天机器人对其进行查询,用智能代理对其进行推理,并执行其他有用的生成式AI应用?

生成式AI,尤其是语言和视觉的基础模型(LLMs、LLVMs等)在过去几年中对自然语言处理NLP和计算机视觉计算机视觉任务做出了巨大贡献。这得益于我们能够扩展这些模型,并且存在一种可靠的关系:随着训练数据量和模型规模的增加,在许多任务上的错误率会下降。此外,研究人员成功地在同一个基础模型中结合了不同的模态,例如文本和图像。
基础模型背后的技术——Transformer架构——已被证明可以成功应用于语言和视觉之外的多种模态的机器学习任务。这引发了这样一个问题:对于在其他模态的大数据上训练的Transformer是否存在类似的神经缩放定律?它们是否会表现出类似的“涌现行为”,如零样本预测?
时间序列数据在商业、金融、工程、科学和制造等领域广泛可用,并且一直是传统机器学习任务(如回归模型预测)的重要数据来源。想想这样的应用:预测月度收入、未来交易价格、地震活动或工厂中即将失效的重要机器部件。我们能否为时间序列学习一个基础模型,并用聊天机器人对其进行查询,用智能代理对其进行推理,并执行其他有用的生成式AI应用?
当使用像Milvus这样的向量数据库构建RAG或Agent应用程序时,基础模型是核心组件之一,无论是用于生成响应还是计算中间值。在这篇文章和配套笔记本中,我们将探讨最近关于时间序列基础模型的工作,重点介绍其中一个模型:TimesFM (Das et al., 2024)。相关工作几乎同时发生:参见Lag-Llama (Rasul et al., 2024)、TimeGPT-1 (Garza et al., 2024)、Tiny Time Mixers (Ekambaram et al., 2024)、Morai (Woo et al., 2024) 和 MOMENT (Goswami et al., 2024)。
我们解释了该模型如何将标准的语言模型架构适应到时间序列。我们还解释了其中最重要的组成部分之一,即大规模的时间序列数据集及其组装方式。最后,我们将展示这些模型的应用并讨论其局限性。
1、应用
为什么我们要训练一个时间序列基础模型呢?最直接的答案是为了能够有效地进行零样本和少样本预测任务,比如预测、填补缺失数据和分类。零样本和少样本预测在许多方面都非常有用:
首先,当我们拥有的时间序列数据很少时非常有用。此外,正如TimesFM (Das et al., 2024) 所述,令人惊讶的是,某些情况下,具有零样本学习能力的基础模型的表现优于专门为此任务训练的非基础模型。而且我认为,针对特定任务微调的基础模型将优于从头开始为此任务训练的模型。
其次,它作为代理执行时间序列任务的一种快速且健壮的工具非常有用。当然,我们可以给代理提供模型训练作为工具,尽管这对实时代理来说是不够的。我们在配套笔记本中探讨了零样本学习作为代理工具的想法以及一些挑战。
2、模型
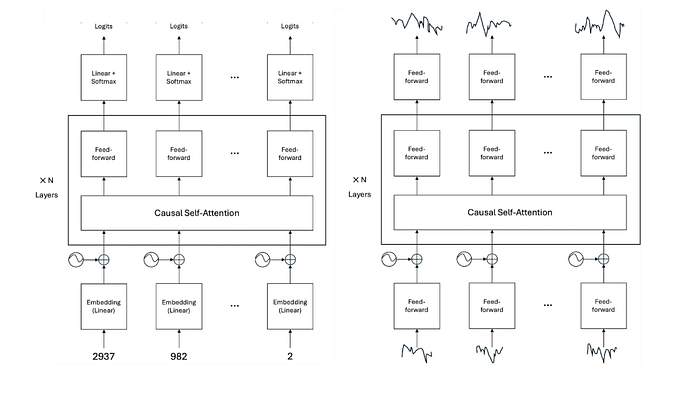
TimesFM 改进了通常用于语言模型的标准解码器-only Transformer 架构,例如 Open 的 GPT、Meta 的 Llama 和 Google 的 Gemma。在上图中,我们比较了(简化后的)架构及其与解码器-only Transformer 的类比。
TimesFM 在连续的时间序列片段上工作,而不是离散的标记。 时间序列被分割成固定长度的 N 个片段,并通过一个小的前馈网络嵌入。相比之下,语言模型只是简单地从表中查找每个标记的学习嵌入。然后,使用与语言模型相同的方法将位置编码添加到片段嵌入中。然后,将每个片段的组合嵌入输入到 N 个因果自注意力层中,以输出每个片段的上下文相关的嵌入。最后,每个上下文相关的嵌入通过第二个小的前馈网络传递,以产生一个固定预测窗口的点预测数组,该窗口位于所讨论片段之后。 相比之下,语言模型将上下文相关的嵌入传递给线性层,映射到下一个标记的 logits。
3、数据
TimesFM 的作者构建了一个新的时间序列数据集,旨在代表各种领域、趋势和季节性模式以及粒度。他们利用了测量 Google 搜索特定趋势的流量、Wikimedia 页面浏览量的流量、由经典回归模型构造的合成数据以及少量现有的开源时间序列数据。该数据集包含 3000 亿个时间点,其中大约 2500 亿来自 Wikimedia 流量,60 亿来自合成数据,50 亿来自 Google 趋势流量,其余来自现有的真实世界数据集。
4、训练
TimesFM 使用不同于语言建模的损失函数进行训练。模型被训练以最小化预测点(给定上下文片段)的点估计与其真实值之间的均方误差。另一方面,语言模型的生成预训练则最小化估计的下一个标记 logits 与真实值之间的交叉熵。
TimesFM 已经在 3000 亿个时间序列点上以 1000 亿、2000 亿和 5000 亿参数的规模进行了训练。作为一个对比,GPT-1 有 1.2 亿参数,而 GPT-2 有 15 亿参数。此外,GPT-1 在大约 10 亿个标记上进行了训练,而 GPT-2 在大约 100 亿个标记上进行了训练。然而,很难在模态之间绘制模型和数据大小的类比,但我们感觉到时间序列基础模型仍处于早期发展阶段。
5、讨论
TimesFM(及相关工作如 Lag-Llama 和 TimeGPT-1)成功展示了从头训练一个时间序列基础模型的可能性——类似于大型语言模型——它能够进行零样本学习并表现出神经缩放定律。有关其实验设置和结果的更多细节,请参阅论文。这与之前的尝试形成了对比,后者涉及微调预训练的语言模型。(Tan 等人,2024 提供证据表明,微调的语言模型在时间序列方面没有任何迁移学习能力。)
当然,仍然存在挑战。基础模型最重要的组成部分是大数据,这对于时间序列来说很难收集。正如我们所见,TimesFM 和 Lag-Llama 的作者为了这个目的巧妙地构建了新的时间序列数据集。然而,我们认为这些模型如果能扩大几个数量级将会受益匪浅——回想一下从 GPT-2(15 亿参数)到 GPT-3(1750 亿参数)的巨大飞跃。要为此目的获得更大的时间序列数据集将是一项挑战。
这里介绍的基本预测模型有许多扩展,这些扩展将提高它们在商业应用中的实用性。例如,预测多变量而非单变量时间序列,包括不确定性估计,条件外生变量,以及利用深度学习的最新进展。此外,一个真正有用的时间序列基础模型将是多模态的,能够输入文本等。在架构方面,未来的模型很可能会结合结构化状态空间模型和 xLSTM 的想法,以实现更长、更准确的预测,并提供可靠的不确定性估计。
总之,时间序列的基础模型还处于早期阶段,是一个令人兴奋的研究领域!您可以立即试验这些开源模型。参见配套笔记本,我将在其中向您展示如何构建一个零样本时间序列预测作为工具的代理工作流的概念验证。可以肯定的是,多样化模态中的基础模型爆炸只会不断增加。RAG和自主系统的重要性增加,从而提升了向量数据库的重要性。Milvus 胜出!
要观看本笔记本的实时演示,请在这里观看点播回放。
原文连接:Foundation Models for Times Series
汇智网翻译整理,转载请标明出处
