Tiny-R1小模型比肩DeepSeek-R1
Tiny-R1–32B-Preview模型是由Qihoo360开发的第一代推理模型,旨在利用仅占全R1模型5%的参数的情况下提供接近R1的性能。
几天前,DeepSeek-R1震惊了世界。由于模型如此优秀且开源,它成为了每个人的首选。但不幸的是,即使已经开源,普通用户仍然无法在本地使用该模型。
为什么?因为它太大了。确切地说,有671B个参数
对于硬件条件一般的用户来说,运行DeepSeek-R1仍然是一个梦想。但现在不再如此,因为一个新的模型Tiny-R1,仅有32B个参数,即DeepSeek-R1总参数的约5%,几乎在主要基准测试中达到了其性能。
1、Tiny-R1 32B简介
Tiny-R1–32B-Preview模型是由Qihoo360开发的第一代推理模型,旨在利用仅占全R1模型5%的参数的情况下提供接近R1的性能。该模型采用SuperDistillation技术进行优化,并在数学、编码和科学等任务中优于多个较大的模型,例如Deepseek-R1-Distill-Llama-70B。
什么是SuperDistillation?
SuperDistillation是一种改进的知识蒸馏(将大型模型的知识转移到较小模型)过程的技术。传统的蒸馏涉及训练一个小模型(学生)来复制一个预先训练好的大模型(教师)的行为,而超级蒸馏通过专注于转移更细粒度的知识,如内部表示或中间特征,而不仅仅是最终输出,从而增强了这一点。这导致了更高效和有效的学生模型。
主要特性:
- 性能:Tiny-R1–32B-Preview在各个领域均取得了高分:
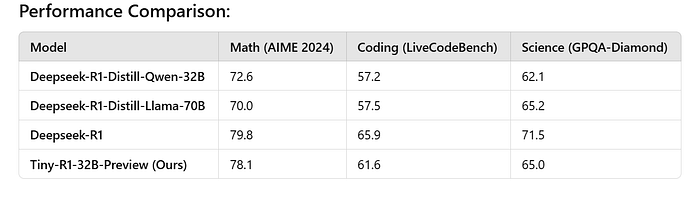
数学:
Tiny-R1–32B-Preview(78.1)非常接近Deepseek-R1(79.8),但略低。
Deepseek-R1-Distill模型表现较差,得分分别为72.6(Qwen-32B)和70.0(Llama-70B)。
编程:
Tiny-R1–32B-Preview(61.6)优于Deepseek-R1-Distill模型(57.2和57.5)。
Deepseek-R1在这一领域表现出最高性能(65.9)。
科学:
Tiny-R1–32B-Preview(65.0)与Deepseek-R1-Distill-Llama-70B(65.2)相当,但仍落后于Deepseek-R1(71.5)。
2、Tiny-R1是如何训练的?
基础模型选择:
- 团队从Deepseek-R1-Distill-Qwen-32B,一个大型预训练模型开始。
监督微调(SFT):
- 他们应用了监督微调(SFT)来适应模型到三个特定领域:数学、编程和科学。
- 这包括在特定领域的数据上训练模型,使其专门化为每个任务。
360-LLaMA-Factory框架:
- 微调是在360-LLaMA-Factory训练框架下完成的,该框架设计用于在专业化任务上高效地训练大型模型。
使用开源数据:
- 对于每个领域,开源数据被用作种子(起点)。
- 这些种子包含数学、编程和科学中的问题,以帮助模型学习任务特定知识。
使用Deepseek-R1生成响应:
- 模型Deepseek-R1基于种子问题为每个领域(数学、编程和科学)生成适当的响应。
创建专业化模型:
- 由此产生了三个专业化模型,每个领域一个:数学模型、编程模型和科学模型。
使用Mergekit合并模型:
- 然后团队使用Mergekit工具(由Arcee团队开发)将这三个专业化模型合并成一个统一的模型。
创建Tiny-R1–32B-Preview:
- 最终结果是Tiny-R1–32B-Preview,这是一个紧凑的模型,在所有三个领域都展示了强大的性能。
3、如何使用Tiny-R1?
该模型已开源,权重可在这里下载。
原文链接:Tiny-R1: 32B model achieves DeepSeek-R1 performance
汇智网翻译整理,转载请标明出处
