10个最好的多模态数据集
本文收集了10个最好的多模态数据集以及这些数据源的链接。这些数据集对于多模态深度学习至关重要。

多模态数据集就像是我们感官的数字等价物。就像我们用视觉、声音和触觉来解释世界一样,这些数据集结合了各种数据格式(文本、图像、音频和视频),以提供对内容的更丰富的理解。
可以这样想:如果你试图仅通过阅读剧本来理解一部电影,那么你就会错过让故事栩栩如生的视觉和听觉元素。多模态数据集提供了那些缺失的部分,使人工智能能够捕捉到如果局限于单一类型的数据就会丢失的细微差别和背景。
另一个例子是分析医学图像和患者记录。这种方法可以揭示如果单独检查每种类型的数据可能会遗漏的模式,从而导致疾病诊断方面的突破。这就像组装多个拼图块以创建更清晰、更全面的画面。
在这篇博客中,我们收集了最好的多模态数据集以及这些数据源的链接。这些数据集对于多模态深度学习至关重要,多模态深度学习需要整合多个数据源来提高图像字幕、情绪分析、医疗诊断、视频分析、语音识别、情绪识别、自动驾驶汽车和跨模态检索等任务的性能。
0、什么是多模态深度学习?
多模态深度学习是机器学习的一个子领域,涉及使用深度学习技术同时分析和整合来自多个数据源和模态(如文本、图像、音频和视频)的数据。这种方法使用来自不同类型数据的互补信息来提高模型性能,从而实现增强图像字幕、视听语音识别和跨模态检索等任务。
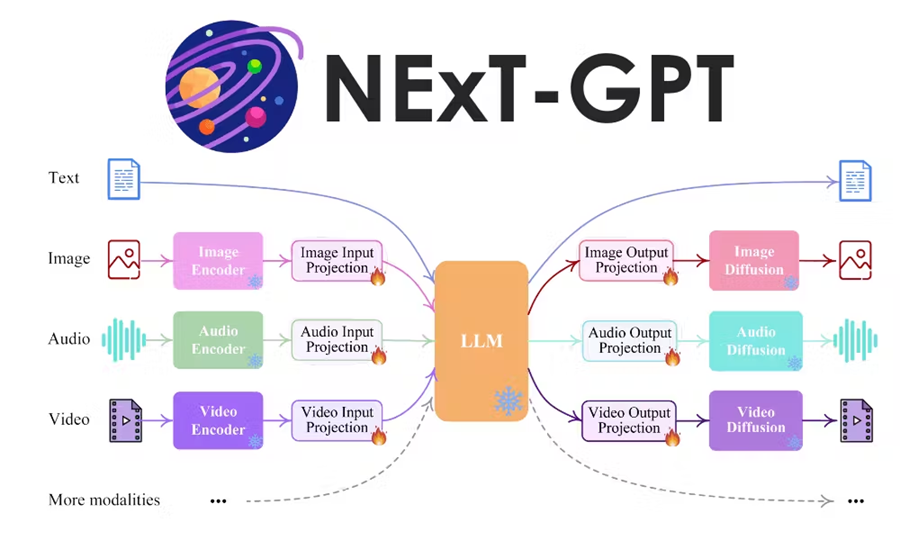
多模态数据集通过提供更丰富、更具上下文信息,显著增强了计算机视觉应用:
- 通过将视觉数据与其他模态和数据源(如文本、音频或深度信息)相结合,模型可以在对象检测、图像分类和图像分割等任务中实现更高的准确性。
- 多模态模型不易受到单一模态的噪声或变化的影响。例如,结合视觉和文本数据可以帮助克服遮挡或模糊图像内容等挑战。
- 多模态数据集允许模型学习对象与其上下文之间更深层次的语义关系。这使得视觉问答 (VQA) 和图像生成等更复杂的任务成为可能。
- 多模态数据集为计算机视觉、大型语言模型、增强现实、机器人技术、文本到图像生成、VQA、NLP 和医学图像分析等新应用开辟了可能性。
- 通过整合来自不同模态数据源的信息,模型可以更好地理解视觉数据的上下文,从而产生更智能、更像人类的大型语言模型。
1、Flickr30K Entities数据集
Flickr30K Entities数据集专门用于改进自动图像描述研究并了解语言如何引用图像中的对象。它为图像文本理解任务提供了更详细的标注。
Flickr30K Entities数据集建立在 Flickr30k 数据集之上,其中包含从 Flickr 收集的 31K+ 幅图像。Flickr30k Entities中的每个图像都与五个描述图像内容的众包标题相关联。数据集为图像标题中提到的所有实体(人、物体等)添加了边界框标注。
Flickr30K 允许开发更好的大型语言模型,具有用于图像字幕的视觉功能,其中模型不仅可以描述图像内容,还可以精确定位所描述的实体的位置。它还可以提高基础语言理解能力,即机器理解与物理世界相关的语言的能力。

- 研究论文:Flickr30k Entities:收集区域与短语对应关系,以构建更丰富的图像与句子模型
- 作者:Bryan A. Plummer、Liwei Wang、Chris M. Cervantes、Juan C. Caicedo、Julia Hockenmaier 和 Svetlana Lazebnik
- 数据集大小:31,783 张真实世界图像、158,915 个标题(每张图片 5 个)、大约 275,000 个边界框、44,518 个唯一实体实例。
- 许可:数据集通常遵循原始 Flickr30k 数据集许可,允许在非商业项目中进行研究和学术使用。但是,您应该验证当前的许可条款,因为它们可能已更改。
- 访问链接:Bryan A. Plummer 网站
2、Visual Genome
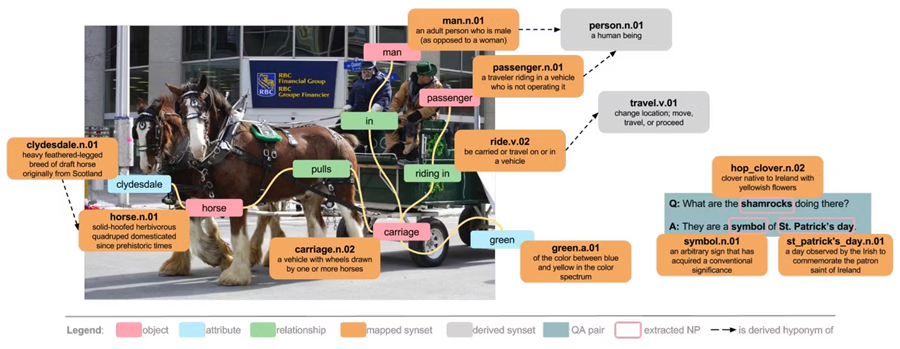
Visual Genome 数据集是一个多模态数据集,弥补了图像内容和文本描述之间的差距。它为从事图像理解、发现、VQA 和多模态学习等领域的研究人员提供了丰富的资源。
Visual Genome 结合了两种模态,第一种是 Visual,包含来自 MSCOCO 数据集的超过 108,000 张图像作为视觉组件,第二种是 Textual,其中图像广泛地标注了文本信息(即对象、关系、区域标题、问答对)。
该数据集的多模态性质提供了诸多优势,例如更深层次的图像理解,可以识别场景中对象之间的含义和关系,而不仅仅是简单的对象检测;VQA 可以理解上下文并回答需要推理视觉内容的问题;多模态学习可以从视觉和文本数据中学习。
- 研究论文:Visual Genome:使用众包密集图像标注连接语言和视觉
- 作者:Ranjay Krishna、Yuke Zhu、Oliver Groth、Justin Johnson、Kenji Hata、Joshua Kravitz、Stephanie Chen、Yannis Kalantidis、Li-Jia Li、David A. Shamma、Michael S. Bernstein、Fei-Fei Li
- 数据集大小:108,077 张真实世界图像、540 万个区域描述、170 万个 VQA、380 万个对象实例、280 万个属性、230 万个关系
- 许可:Ranjay Krishna 的Visual Gnome已获得 Creative Commons Attribution 4.0 International 许可。
- 访问链接:Hugging Face 的 Visual Genome 数据集
3、MuSe-CaR
MuSe-CaR(汽车评论中的多模态情绪分析)是一个多模态数据集,专门用于研究用户生成的视频评论“真实”环境中的情绪分析。
MuSe-CaR 结合了三种模态(即文本、音频、视频)来理解汽车评论中的情绪。文本评论以口语形式呈现,在视频录制中捕捉到,音频由声音特质(如音调、音高和重音)组成,以揭示评论的情感方面,而不仅仅是口语,视频由面部表情、手势和整体肢体语言组成,为评论者的情绪提供额外的线索。
MuSe-CaR 旨在通过提供丰富的数据集来训练和评估能够理解通过各种模态表达的复杂人类情感和观点的模型,从而推动多模态情绪分析的研究。

- 研究论文:汽车评论中的多模态情感分析 (MuSe-CaR) 数据集:收集、见解和改进
- 作者:Lukas Stappen、Alice Baird、Lea Schumann、Björn Schuller
- 数据集大小:40 小时用户生成的视频材料,包括来自 YouTube 的 350 多条评论和 70 位主持人(以及 20 位配音解说员)。
- 许可:最终用户许可协议 (EULA)
- 访问链接:Muse Challenge 网站
4、CLEVR
CLEVR 代表组合语言和基本视觉推理,是一种多模态数据集,旨在评估机器学习模型使用视觉信息和自然语言推理物理世界的能力。它是一个合成的多模态数据集,旨在测试 AI 系统对视觉场景进行复杂推理的能力。
CLEVR 结合了两种模态,即视觉和文本。视觉模态包括包含各种对象的渲染 3D 场景。每个场景都有一个简单的背景和一组具有不同属性的物体,如形状(立方体、球体、圆柱体)、大小(大、小)、颜色(灰色、红色、蓝色等)和材料(橡胶、金属)。文本模态包括用自然语言提出的有关场景的问题。这些问题要求模型不仅要“看到”物体,还要理解它们的关系和属性,以便准确回答。
CLEVR 用于机器人和其他领域的视觉推理等应用中,以实时了解物体之间的空间关系(例如,“哪个物体在蓝色橡胶立方体前面?”),计数和比较以枚举具有特定属性的物体(例如,“有多少个小球体?”),以及逻辑推理以理解场景和问题以得出正确答案,即使答案不是直接可见的(例如,“橡胶物体完全在立方体后面。它是什么颜色的?”)。

- 研究论文:CLEVR:用于组合语言和基本视觉推理的诊断数据集
- 作者:Justin Johnson、Bharath Hariharan、Laurens van der Maaten、Fei-Fei Li、Larry Zitnick、Ross Girshick
- 数据集大小:100,000 张图像、864986 个问题、849,980 个答案、85,000 个场景图注释和功能程序表示。
- 许可:Creative Commons CC BY 4.0 许可。
- 访问链接:斯坦福大学 CLEVR 页面
5、InternVid
InternVid 是一个相对较新的多模态数据集,专门用于使用生成模型进行视频理解和生成相关任务。InternVid 专注于视频文本模态,结合了大量包含日常场景和活动的视频,并附有详细的字幕,描述视频中的内容、动作和对象。
InternVid 旨在支持各种与视频相关的任务,例如视频字幕、视频理解、视频检索和视频生成。

- 研究论文:InternVid:用于多模态理解和生成的大型视频文本数据集
- 作者:Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, LiMin Wang, Yu Qiao
- 数据集大小:InternVid 数据集包含超过 700 万个视频,时长近 76 万小时,产生了 2.34 亿个视频片段,并附有总计 41 亿个单词的详细描述。
- 许可:InternVid 数据集根据 Apache 许可 2.0 获得许可
- 访问链接:Huggingface 上的 InternVid 数据集
6、MovieQA
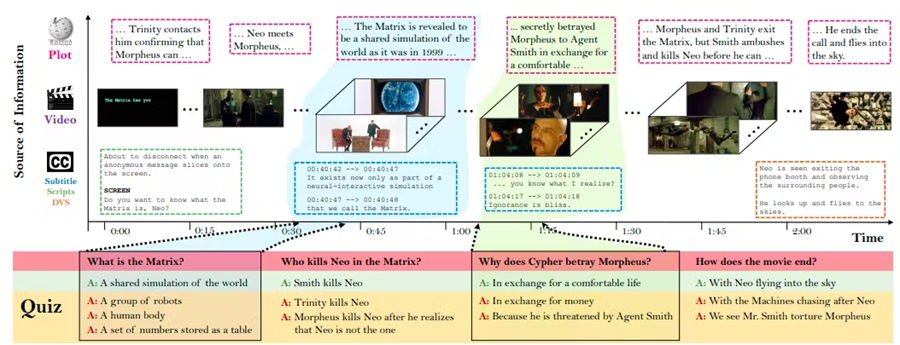
MovieQA 是一个多模态数据集,专门为使用文本和视频信息进行视频问答 (VideoQA) 任务而设计。
MovieQA 结合了三种模态,即视频、文本和问答对。该数据集由来自各种电影剪辑的视频剪辑组成,并配有字幕或文字记录,提供口头对话和屏幕动作的文本描述。
每个视频剪辑都与多个问题配对,这些问题需要理解视频的视觉内容和字幕/文字记录中的文本信息才能准确回答。
MovieQA 旨在评估模型对视频剪辑中发生的动作、交互和事件的理解程度。它可以利用字幕/文字记录等文本信息来补充视觉理解并回答可能需要两种模态信息的问题并提供信息丰富的答案。
- 研究论文:MovieQA:通过问答了解电影中的故事
- 作者:Makarand Tapaswi、Yukun Zhu、Rainer Stiefelhagen、Antonio Torralba、Raquel Urtasun、Sanja Fidler
- 数据集大小:该数据集包含 15,000 个问题,涉及 400 部具有高度语义多样性的电影。
- 许可证:未知
- 访问链接:Metatext 上的数据集
7、MSR-VTT
MSR-VTT 代表 Microsoft Research Video to Text,是一个大型多模态数据集,旨在训练和评估自动视频字幕任务的模型。MSR-VTT 的主要重点是训练能够根据视觉内容自动为未看过的视频生成字幕的模型。
MSR-VTT 结合了两种模态,即视频和文本描述。视频是涵盖各种类别和活动的网络视频集合,每个视频都配有多个自然语言字幕,描述视频中的内容、动作和对象。
MSR-VTT 有助于使用大量数据进行大规模学习,从而使模型能够学习强大的视频表示并生成更准确、更具描述性的字幕。来自不同类别的视频有助于模型很好地推广到未见过的视频内容,每个视频的多个字幕可以更深入地理解内容。

- 研究论文:MSR-VTT:用于连接视频和语言的大型视频描述数据集
- 作者:Jun Xu、Tao Mei、Ting Yao、Yong Rui
- 数据集大小:大型视频字幕数据集,包含 10,000 个剪辑(38.7 小时)和 200,000 个描述。与其他类似数据集相比,它涵盖了不同的类别,并且拥有最多的句子/词汇。每个剪辑都有大约 20 个由人工注释者编写的字幕。
- 许可证:未知
- 访问链接:Kaggle上的数据集
8、VoxCeleb2
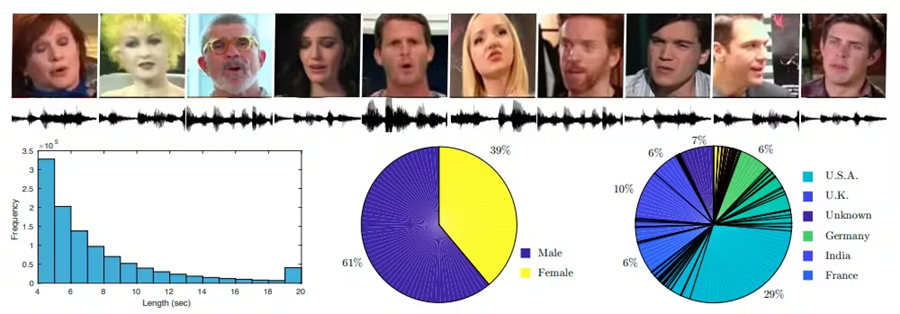
VoxCeleb2 是一个大型多模态数据集,专为与说话人识别和其他视听分析相关的任务而设计。VoxCeleb2 结合了两种模态,音频和视频。音频由来自不同个体的语音录音和说话者的相应视频剪辑组成,允许提取视觉特征。
VoxCeleb2 主要侧重于说话人识别,包括根据说话人的声音识别或验证说话人。但是,数据集的视听性质还允许进行人脸识别和说话人验证。
- 研究论文:VoxCeleb2:深度说话人识别
- 作者:Joon Son Chung、Arsha Nagrani、Andrew Zisserman
- 数据集大小:VoxCeleb2 是一个大型数据集,包含 6,112 位名人的 100 多万条话语,这些话语是从上传到 YouTube 的视频中提取的。
- 许可:VoxCeleb2 元数据已获得 Creative Commons Attribution-ShareAlike 4.0 国际许可。
- 访问链接:VoxCeleb2 数据集
9、VaTeX
VaTeX(变分文本和视频)是专为研究视频和语言任务而设计的多模态数据集。
模态:VaTeX 结合了两种模态,一组描述各种活动和场景的视频,以及每个视频的文本描述,用英文和中文描述内容。一些字幕对是平行翻译,允许进行视频引导的机器翻译研究。
VaTeX支持与视频和语言相关的多个研究领域,例如多语言视频字幕,为多种语言的视频生成字幕,视频引导机器翻译,以提高机器翻译的准确性,以及视频理解,以分析和理解视频内容的含义,而不仅仅是简单的对象识别。

- 研究论文:VaTeX:用于视频和语言研究的大规模、高质量多语言数据集
- 作者:王欣、吴嘉伟、陈俊昆、李雷、王远芳、王杨威廉
- 数据集大小:该数据集包含超过 41,250 个视频和 825,000 个英文和中文字幕。
- 许可:该数据集受 Creative Commons Attribution 4.0 International 许可。
- 访问链接:VATEX 数据集
10、WIT
WIT 代表基于维基百科的图像文本,是一个最先进的大规模数据集,专为与图像文本检索和其他多媒体学习应用相关的任务而设计。
模式:WIT 结合了两种模式,图像是来自维基百科的大量独特图像集合,以及从相应的维基百科文章中提取的每幅图像的文本描述。这些描述提供了有关图像中描述的内容的信息。
WIT 主要关注涉及图像与其文本描述之间关系的任务。一些关键应用是图像文本检索,用于使用文本查询检索图像,图像字幕,用于为未见过的图像生成字幕,以及多语言学习,可以理解图像并将其与各种语言的文本描述联系起来。

- 研究论文:WIT:基于维基百科的多模式多语言机器学习图像文本数据集
- 作者:Krishna Srinivasan、Karthik Raman、Jiecao Chen、Michael Bendersky、Marc Najork
- 数据集大小:WIT 包含一组精选的 3760 万个实体丰富的图像文本示例,其中有 1150 万张独特图像,涵盖 108 种维基百科语言。 I
- 许可:此数据在 Creative Commons Attribution-ShareAlike 3.0 Unported 许可下可用。
- 访问链接:Google 研究数据集 github
11、结束语
多模态数据集融合了来自文本、图像、音频和视频等不同数据源的信息,提供了对世界的更全面的表征。这种融合使 AI 模型能够解读复杂的模式和关系,从而提高图像字幕、视频理解和情感分析等任务的性能。通过涵盖不同的数据方面,多模态数据集突破了人工智能的界限,促进了更像人类的理解和与世界的互动。
这些来自各种数据源的数据集推动了各个领域的重大进步,从卓越的图像和视频分析到更有效的人机交互。随着技术的不断进步,多模态数据集无疑将在塑造 AI 的未来方面发挥关键作用。拥抱这一发展,我们可以期待更智能、更直观的 AI 系统,更好地理解和与我们多面的世界互动。
原文链接:Top 10 Multimodal Datasets
汇智网翻译整理,转载请标明出处
