11个最佳大模型安全工具
LLM 和其他 AI/ML 技术的日益普及,引发了有关安全性和保障的重大而多方面的担忧。这篇文章介绍了一些可集成到你的策略中的最佳 LLM 安全工具

大型语言模型 (LLM) 是基础人工智能技术,为生成式人工智能和其他基于语言的人工智能工具提供支持。它们内置于公司用来编写软件代码、提供自动化客户服务聊天机器人、生成营销内容等的应用程序中。LLM 的类人语言能力和闪电般的推理能力可以帮助各个行业的组织提高生产力和收入,这就是为什么近几个月来它们的采用率激增的原因。
LLM 和其他 AI/ML 技术的日益普及,以及对其决策能力的日益依赖,引发了有关安全性和保障的重大而多方面的担忧。其中包括:
- LLM 如何收集和使用消费者数据(尤其是敏感或个人身份信息 (PII))。
- 训练数据集固有的公平性和包容性,以及如何避免 LLM 的偏见推理(决策)。
- 模型及其支持基础设施的安全性,包括其抵御篡改(可能影响推理的公平性和准确性)或数据提取(可能泄露敏感的消费者信息)的能力。
- LLM 有可能在输出给最终用户时生成非法、暴力或其他有害内容。
- 确保安全和道德保障不会对模型性能和准确性产生负面影响,以便其推理仍然值得信赖并提供商业价值。
缓解这些问题的最佳方法是采用针对你的用例和环境的多层安全策略。这篇文章介绍了一些可集成到你的策略中的最佳 LLM 安全工具。
1、Granica Screen
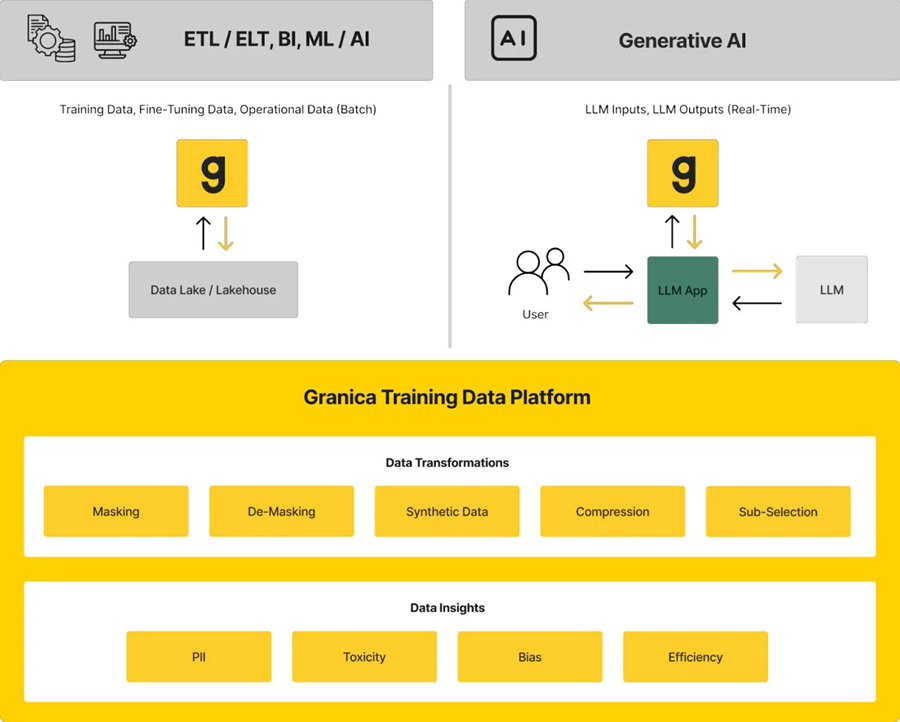
Granica Screen 是一种隐私和安全解决方案,可帮助组织以合乎道德的方式开发和使用 AI。Screen“AI 安全室”可在训练、微调、推理和 RAG 期间保护表格和自然语言处理 (NLP) 数据和模型。
它以最先进的精度检测敏感和不需要的数据,如个人身份信息 (PII)、偏见和毒性,并使用合成数据生成等屏蔽技术来确保 LLM 和生成 AI 的安全有效使用。
Granica Screen 帮助组织在数据隐私方面向左移动,使用 API 直接集成到支持数据科学和机器学习 (DSML) 工作流的数据管道中。
2、Purple Llama

Purple Llama 是 Meta 创建的一组开源 LLM 安全工具和评估基准,旨在帮助开发人员使用开放的 genAI 模型进行合乎道德的构建。这个综合项目不断增加新功能,但其当前的功能集包括 Llama Guard 输入和输出审核模型、用于检测和阻止恶意提示的 Prompt Guard、用于降低 LLM 生成不安全代码建议的风险的 Code Shield 以及用于安全和渗透测试的 CyberSec Eval 基准。
3、Garak
Garak 是一款免费的开源漏洞扫描工具,适用于聊天机器人和其他 LLM。它可以探测可能导致 LLM 失败或出现其他不良行为的多种弱点。例如幻觉、数据泄露、提示注入、错误信息、毒性生成和越狱。扫描后,Garak 会提供一份完整的安全报告,详细说明模型、基于 LLM 的应用程序或第三方集成中的优势和劣势。
4、Vigil

Vigil 也称为 Vigil LLM,以区别于许多其他称为“Vigil”的 AI 相关工具,它是一个 Python 库和 REST API,用于检测针对基于 LLM 的技术的威胁。它评估 LLM 输入和输出,以查找提示注入、越狱和其他有针对性的 AI 攻击的迹象。Vigil LLM 目前处于 alpha 状态,因此仍在进行中,应谨慎使用。
5、Rebuff

Rebuff 是一种 LLM 威胁检测工具,主要侧重于防止提示注入攻击。它在四个方面提供保护:启发式方法,在潜在恶意提示到达 LLM 之前将其过滤掉;专用的 LLM 用于分析输入并识别恶意内容;先前攻击嵌入的矢量数据库,有助于识别和防止未来的攻击;以及金丝雀令牌,用于检测泄漏并允许框架将嵌入存储在矢量数据库中。
6、Private AI

Private AI(不要与 PrivateAI 混淆,后者是另一种产品)是一种数据最小化解决方案,可识别、匿名化和替换 50 多个敏感和个人身份信息实体。PrivateGPT 产品会在将用户提示发送到 ChatGPT 之前清除其中的个人信息,以降低意外泄露的风险。
7、PrivateSQL
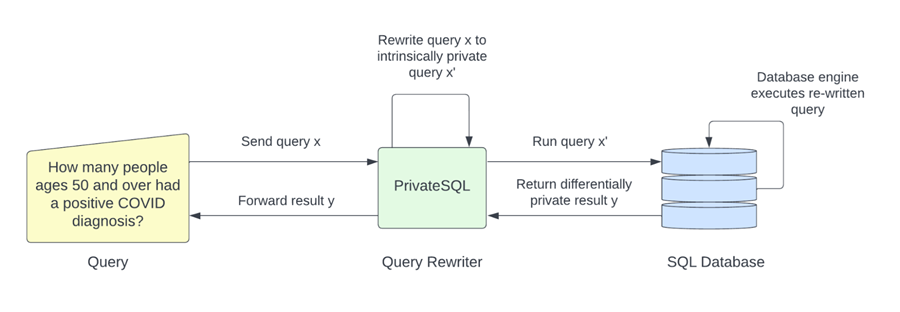
PrivateSQL 是一种差异隐私解决方案,可自动将聚合查询重写为差异隐私。母公司 Oasis Labs 还提供隐私预算跟踪工具,并与 Meta 合作发布了采用差异隐私、多方计算加密和同态加密等技术的偏见和公平性检测系统。
8、Adversarial Robustness Toolbox

Adversarial Robustness Toolbox(ART:对抗鲁棒性工具箱 ) 是一个对抗训练工具的 Python 库,用于教导 LLM 和其他 AI 应用程序如何发现逃避、中毒、提取和推理攻击。它还提供防御模块来强化 LLM 应用程序,并支持多种估算、鲁棒性指标和认证。值得注意的是,ART 被许多其他对抗训练工具使用或集成,包括 Microsoft Counterfit。
9、NVIDIA FLARE
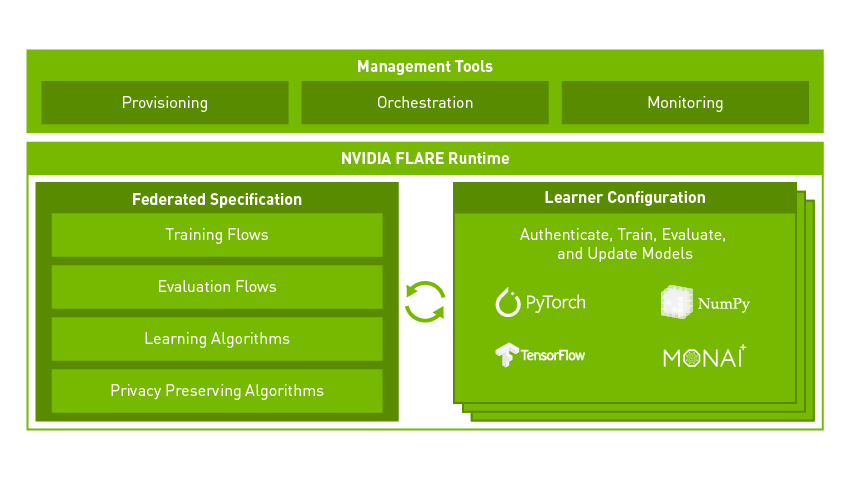
FLARE(联合学习应用程序运行时环境)是来自 NVIDIA 的开源、领域无关的联合学习 SDK(软件开发工具包)。它帮助公司将现有的 AI/ML 架构(从 PyTorch、RAPIDS、TensorFlow 等)调整为联合范式。
10、Flower

Flower 是一个用于构建联合学习系统的“友好”框架。它是一种与框架无关的解决方案,可在开发人员现有的 AI/ML 库中运行,并且可以扩展和适应任何用例。Flower 易于使用,可以在 LLM 研究、开发和微调的任何阶段实施。
11、Microsoft Counterfit
Microsoft Counterfit 是一款 CLI(命令行界面)工具,用于编排针对 AI 模型的对抗性训练攻击。它本身不会生成攻击,而是添加一个自动化层,与 ART 等对抗性训练框架交互以简化流程。
汇智网翻译整理,转载请标明出处
