17个最好的文本转语音API
文本转语音(TTS),也称为语音合成,可用于各种应用,包括个人助理、导航系统、电子学习平台以及视障人士或阅读困难人士的辅助工具。本文介绍开发者最常用的17个语音合成API。

文本转语音 (TTS) API,也称为语音合成,允许用户将书面文本转换为口语。它接收文本输入并将其转换为各种语言和口音的可听语音输出。TTS技术可用于各种应用,包括个人助理、导航系统、电子学习平台以及视障人士或阅读困难人士的辅助工具。
本文介绍开发者最常用的17个语音合成API。
1、AWS - Amazon Polly
Amazon Polly 是一种强大的文本转语音 API,可将书面内容转换为自然语音。利用深度学习技术,它可为多种语言和用例提供高质量的语音合成。
Amazon Polly 使用高级语音合成模型处理文本输入,生成音频文件或流式传输实时响应。开发人员可以自定义语音特性,确保为特定应用程序提供量身定制的输出。它允许用户自定义语音输出并使用词典和语音合成标记语言 (SSML) 标签创建个性化语音。Amazon Polly 允许以 MP3 和 OGG 等标准格式存储和共享语音,同时提供逼真的声音和快速的响应时间。
AWS 的 TTS 能够生成不同语言的语音,使其成为具有全球通信需求的企业和个人的高度通用和有用的工具。用户还可以调整生成的语音的说话风格、语速、音调和音量,从而实现更大的自定义和灵活性。
Amazon Polly API的主要功能:
- 多语言支持:提供各种语言和方言的数十种声音,实现全球覆盖。
- SSML 集成:允许开发人员使用暂停、强调和语音拼写标签来控制语音输出。
- 音频存储和分发:支持将合成语音存储为 MP3 或 OGG 文件以供离线使用和分发。
2、Colossyan TTS API
Colossyan 的 TTS API 提供了一个文本到语音转换器,允许用户以 70 多种语言和口音创建自然的画外音。使用 Colossyan,用户可以从各种配音演员中进行选择,甚至可以克隆自己的声音以增加个性化。
Colossyan 的声音不断更新和添加,在同一语言中提供多种口音。此外,该 API 通过提供清晰的生成音频消除了对麦克风和音响设备的需求。
3、Descript TTS API
Descript 是一项面向最终用户媒体开发的 AI 服务,可用于制作播客和视频等。其文本转语音工具主要侧重于旁白。它包括语音编辑,如配音语音修复、画外音和语音克隆。
Descript 的 TTS API 利用 Lyrebird AI 提供超逼真的声音,该 AI 在语音合成方面达到了最先进的水平。 Descript API的突出之处在于它能够模仿人类语音的细微差别和语调,使其能够与自然录音无缝融合,同时匹配双方的音调特征。可以创建多种声音以适应任何表演风格或设置。该 API 甚至使纠正录音变得像打字一样简单。
Descript API的主要特点:
- 执行语音克隆
- 生成不同的语调
- 访问语音库
4、ElevenLabs
ElevenLabs提供一种先进的文本转语音解决方案,它使用先进的人工智能来生成具有无与伦比的真实感和情感深度的语音。它专为真实性和参与度至关重要的应用量身定制。
ElevenLabs 提供最先进的文本转语音 API,利用先进的神经网络模型将文本转换为自然的语音。该 API 提供具有可自定义参数的高质量语音合成,允许开发人员根据特定应用程序和用例定制语音输出。ElevenLabs 的文本转语音 API 支持多种语言和口音,可以为各种平台和设备创建多样化且引人入胜的音频内容。其无缝集成功能使其成为通过支持语音的应用程序和服务增强用户体验的宝贵工具。
ElevenLabs API的主要特点:
- 逼真的声音:利用人工智能创建自然而富有表现力的语音输出。
- 情感范围:包括调整音调和语调以获得更具吸引力的内容的功能。
- 广泛的语言支持:提供多种语言和口音的语音,适合全球使用。
5、Google Cloud TTS API
Google Cloud 文本转语音 API 是一款功能强大、用途广泛的工具,可将文本转换为自然语音。它由 DeepMind 的 WaveNet 技术提供支持,可提供适用于各种应用的高质量语音合成。
该 API 使用 Google 的高级 AI 模型处理文本输入以生成语音。开发人员可以将此功能集成到他们的应用程序中,通过 SSML 标签自定义输出,以获得量身定制的用户体验。该 API 还支持实时合成,确保快速响应。
Google Cloud 提供强大的 TTS API,该 API 建立在 DeepMind 的语音合成专业知识的基础上,可生成接近人类质量且语调自然的语音。拥有 380 多种声音50 多种语言和变体,用户可以选择最适合自己需求的声音。此外,Google Cloud 的 API 允许用户创建独特的声音,在所有客户接触点上代表他们的品牌。
该API 提供 Neural2 和 Studio 语音功能,允许使用录音室质量的材料进行国际化和专业叙述。用户可以训练自定义语音模型,调整音调、语速,并使用 SSML 标签进行语音定制。
Google Cloud TTS API的主要特点:
- 广泛的语音库:可访问多种语言和变体的 100 多种语音。
- 使用 SSML 进行自定义:利用语音合成标记语言 (SSML) 来控制音调、语速和发音等方面。
- Neural2 Voices:提供优质语音,增强用户参与度。
6、IBM Watson TTS API
IBM Watson 文本转语音 API 为开发人员提供了一种可靠且先进的工具,可将文本转换为自然、富有表现力的音频。它支持多种语言和细粒度的定制,是增强可访问性和用户参与度的理想选择。
Watson 的 API 通过神经语音模型处理文本以生成高质量音频。开发人员可以将 API 集成到应用程序中,利用其定制功能来制作针对其目标受众量身定制的语音。
IBM Watson 的服务能够使用先进的 AI 和机器学习技术提供多种语言的实时语音合成,使用户能够以母语与客户互动。此外,IBM 还通过其 Premium 服务为用户提供创建独特品牌声音的选项,这可以增强品牌的形象并提高客户参与度。
IBM Watson的主要特点:
- 富有表现力的声音:提供逼真、细致入微的语音合成,带来自然的聆听体验。
- 语言和口音多样性:支持多种语言和地区口音。
- SSML 功能:支持对语音特征(如音高、声调和节奏)的详细控制。
7、Lovo AI
Lovo AI提供下一代 TTS 解决方案,专为寻求逼真、引人入胜的语音合成的内容创作者和企业而设计。此 API 因专注于动态和类似人类的语音生成而脱颖而出。
Lovo 使用先进的 AI 算法来分析文本并生成听起来自然的音频。开发人员可以从各种声音中进行选择,自定义音调和风格,并将 API 集成到工作流程中以实现无缝音频制作。
Lovo 提供了一款名为 Genny 的高品质 AI 语音生成器。其最令人印象深刻的功能之一是情感语音,它可以表达多达 25 种情绪,为任何内容增添深度和真实感,从而使其更具吸引力和令人难忘。该平台还提供一站式视频配音服务,让用户可以轻松地为视频添加音效和背景音乐。
对于专业制作人,Genny 提供精细控制,能够在每个音素级别微调音高,强调单词,并调整单词或句子之间的停顿。Lovo 的 AI 语音还提供卓越的真实感和质量,拥有世界上最大的语音库。
Lovo API的主要特点:
- 广泛的语音选择:提供 100 多种语言的 500 多种声音,满足全球观众的需求。
- 语音克隆:允许用户为品牌和独特应用程序创建个性化的语音配置文件。
- 语音转文本,自动生成字幕
- 灵活集成:提供与各种平台和工具的轻松集成。
8、Microsoft Azure TTS API
Microsoft Azure 文本转语音 API 为开发人员提供了将文本转换为逼真语音的高级工具。其广泛的自定义选项可确保为各种应用程序提供量身定制的音频体验。
Microsoft Azure 提供了强大的文本转语音 API,使用户能够创建具有与人类声音相匹配的语调和情感的逼真合成语音。用户可以使用 Azure 创建独特的 AI 语音生成器,以反映其品牌的身份。
此外,音频控制功能可以通过调整速率、音调、发音、停顿等轻松调整特定场景的语音输出。Azure 还提供灵活的部署选项,允许用户在云、本地或容器边缘运行 TTS。最后,Azure 的 API 能够使用词典和 SSML 定制语音输出,以及使用自定义神经语音功能构建自定义语音的选项。
Microsoft Azure TTS API的主要特点:
- 多种说话风格:从对话、专业和富有同理心的语调中选择以匹配上下文。
- SSML 支持:使用 SSML 微调语音输出,以精确控制发音、停顿和强调。
- 灵活部署:使用容器在云、本地或边缘部署 API。
9、Murf AI
Murf AI 是一种围绕内容创建和软件集成而设计的文本转语音服务。它以 HTML 嵌入代码的形式提供与 Canva、Google Slides、Adobe Audition、Adobe Captivate 和网站的直接集成。它还具有适用于 Windows 的前端应用程序,并与支持 Microsoft Speech API 的平台集成。它具有语音生成器、语音克隆、配音语言翻译和应用程序开发功能。
Murf AI提供逼真的 AI 语音,为视频和演示文稿提供专业的配音。他们选择的 20 种语言的类人 AI 语音经过数十个参数的质量检查,以避免听起来像机器人的声音。用户可以从多种口音中进行选择,并可以使用音调、停顿和发音等功能自定义配音,使其听起来像他们想要的那样。
Murf AI 提供专业级 TTS 功能,使其成为创建高质量音频内容的首选解决方案。它将逼真的声音与强大的编辑工具相结合,以提高工作效率。
Murf AI 通过其直观的平台处理文本,允许用户选择声音、调整节奏并将音频与其他媒体同步。开发人员可以利用 API 将这些功能集成到他们的应用程序中。
Merf AI的主要特点:
- 自然声音:提供适用于各种应用程序的富有表现力和逼真的声音选择。
- 内置编辑器:包括用于优化和同步音频与视觉内容的工具。
- 多语言支持:支持多种语言和口音,以覆盖全球受众。
- 专为创建有声读物、播客、声音文件而设计
- 为对话式 AI 提供业务 API
- 包括 20 多种语言
10、OpenAI TTS API
OpenAI 的文本转语音 API 利用先进的深度学习模型的强大功能,从文本输入生成自然而富有表现力的语音。该 API 提供广泛的语音风格和口音,为在不同领域创建引人入胜的音频内容提供了灵活性。
OpenAI 的文本转语音 API 专注于提供高保真语音合成,使开发人员能够构建沉浸式和交互式体验,从语音助手到音频内容生成。该 API 的用户友好集成和可自定义功能使其成为一种多功能解决方案,可将自然的语音功能整合到各种应用程序和平台中。
11、Play.ht
Play.ht 提供在线文本转语音 API,可将文本转换为自然语音,支持全球 142 种语言和口音。借助这项技术,用户可以轻松下载 MP3 或 WAV 格式的文件。该平台易于使用,因为整个过程不需要任何技术知识。此外,Play.ht 提供多种 AI 语音供您选择,确保生成的语音符合用户的特定需求。
Play.ht 整合了多个 AI 语音数据库,形成了涵盖不同语言的更广泛的声音。它结合了来自亚马逊、谷歌、IBM 和微软的声音。其 AI 语音 API 面向音频发布、有声读物、对话式 AI、呼叫中心等交互式语音响应 (IVR) 系统和电子学习。
其 API 包括国际音标 (IPA) 符号体系,因此用户可以自定义发音。它提供了一个音频小部件以与网站集成。
Play.ht的主要功能:
- 包括实时语音生成
- 超过 142 种语言和口音
- 应用自定义发音
12、ReadSpeaker
ReadSpeaker 是 TTS 领域的领先提供商。凭借 20 多年的语音技术经验,ReadSpeaker 提供多种语言和声音选择,以生成各种口音的语音。
该公司使用业界领先的技术,结合下一代深度神经网络 (DNN) 来产生市场上一些最自然的合成语音。
13、Resemble AI
Resemble AI 提供尖端 API,使用户能够在几秒钟内创建类似人类的画外音。他们广泛的 AI 语音库使其与市场上的其他 API 脱颖而出,拥有超过 200,000 种独特的声音。
借助 Resemble AI 的 TTS,用户无需任何新数据,即可在声音中注入无限的情感。他们还可以使用实时、逼真的语音转语音技术将自己的声音转换为目标声音,该技术可以对每个音调和语调进行精细控制。
Resemble AI 的解决方案还可以将你的声音转换为任何语言,而无需提供任何数据,让你轻松接触全球受众。此外,该技术使用户能够融合人类和合成声音,获得无缝体验。
14、Speechify Text To Speech API
Speechify 可以读取各种内容类型,如网页、文档、PDF 和电子邮件。用户只需拖放或拍摄页面照片即可将文本转换为语音。
Speechify API 能够更改配音的语言和口音,以及调整阅读速度,使其成为需要特定口音或喜欢以特定速度收听内容的个人的绝佳选择。
目前,Speechify 提供 30 多种不同语言的 TTS 语音,并提供多种口音。此外,该平台还提供浏览器扩展,使用户能够大声朗读任何网页。
Speechify 借助 Android 和 iOS 应用程序和浏览器扩展程序,将文本转语音功能应用于跨设备的文档阅读。其名为 Studio 的 Web 界面允许用户以 40 多种语言进行配音,并以 20 多种语言进行配音。它还提供语音克隆服务,每月提供 100,000 个字符,并获得商业使用权。
speechify 的主要特点:
- 提供新闻和文章阅读应用程序
- 托管著名演员和有影响力人士的声音
- 文本转语音 API 仍在开发中
15、Checksub API
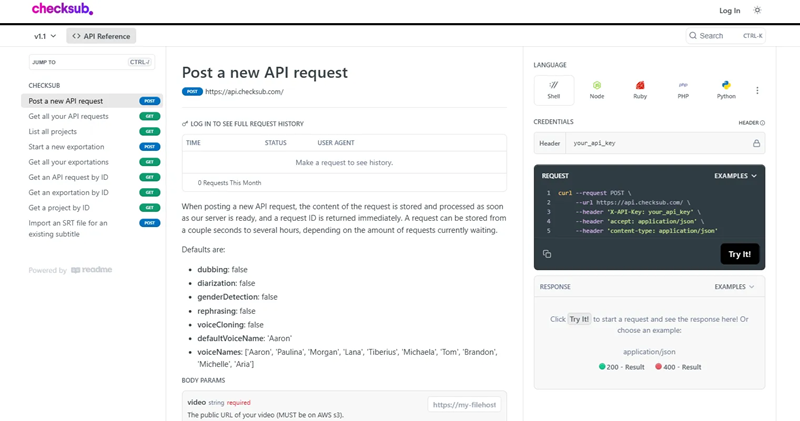
Checksub API 将高级 TTS 功能与强大的字幕和配音工具相结合,使其成为视频创作者和开发者的一体化解决方案。它旨在简化工作流程并提供专业级结果。
Checksub 可以处理文本和视频输入,生成同步的画外音或配音曲目。开发人员可以自定义语音特征并以各种格式导出结果,以便轻松集成到项目中。
Checksub APi的主要特点:
- 多语言配音:支持多种语言的语音生成,非常适合创建本地化内容。
- 语音克隆和自定义:提供克隆语音和微调输出以满足特定需求的选项。
- 高级字幕集成:将 TTS 与字幕工具配对,实现无缝视频编辑。
16、Deepgram Aura

Deepgram Aura 是一种尖端的文本转语音 (TTS) API,旨在提供实时、类似人类的语音合成。此 API 针对需要无缝交互的应用程序进行了优化,例如对话式 AI 和客户支持平台。
Deepgram Aura 使用高级 AI 模型处理文本输入并合成语音。开发人员可以将 API 集成到他们的应用程序中,从而实现模仿自然人类语音模式的语音输出。即使在高需求环境中,API 的响应能力也能确保流畅的用户体验。
Deepgram Aura的主要特点:
- 低延迟:Aura 的延迟小于 250 毫秒,可确保快速响应,是实时应用程序的理想选择。
- 类似人类的声音:提供针对对话用例进行微调的多种男性和女性声音选择。
- 企业级可扩展性:处理大量请求,满足高流量需求的企业。
17、Listnr
Listnr 是一个 AI 文本转语音平台,可作为文本转语音语音服务的集中 API。它允许程序员将对多个语音数据库的访问集成到一个数据库中,包括来自 Amazon Polly、Google WaveNet、IBM Watson 和 Microsoft Azure 的数据库。
Listnr的主要特点:
- 带有 SSML 的可编程 API
- 提供对 1000 多种声音和 142 种语言的访问
- 还提供语音克隆
汇智网编辑整理,转载请标明出处
