3个最强PDF提取工具综合对比
我确定了三个最佳的PDF提取选项,并将它们放在复杂的PDF上进行测试,看看它们各自处理我抛出的挑战的能力如何。
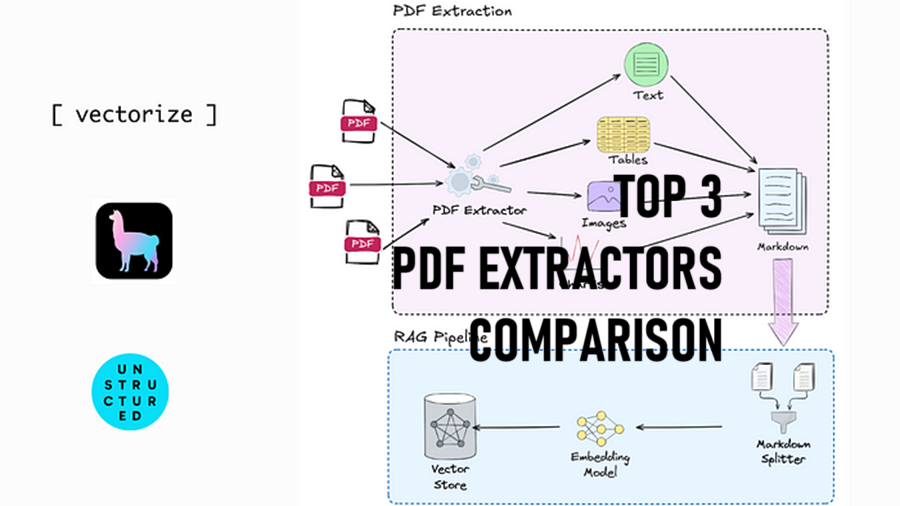
如果你正在构建检索增强生成(RAG)应用程序,你最终需要处理PDF形式的文档。
如果你从未仔细研究过PDF的工作原理,你可能会惊讶于从这些文档中可靠地提取所需数据有多么困难。
这是因为PDF以打印机思考的方式表示内容——如何将墨水印在纸上。
这使得PDF成为印刷文档的一个很好的选择,因为它在定义页面布局时提供了灵活性。你可以打印多列文本。在页面中间,你可以插入跨越多列的图片。你可以使用PDF来打印纯文本文件。你可以用它们制作复杂的用户手册。你可以用它们表示带有高级图形设计的小册子。
所有这些都使PDF成为许多用途的理想选择。
这也使得当你想将PDF文档转换为最结构化的格式以供RAG使用时变得非常麻烦。
幸运的是,大型语言模型的出现和RAG的流行已经导致了一些可以简化这项任务的进步。
在这篇文章中,我尝试了几种解决方案。这些方案包括独立库和托管云服务。最后,我确定了三个最佳的PDF提取选项,并将它们放在复杂的PDF上进行测试,看看它们各自处理我抛出的挑战的能力如何。
1、参赛者
经过大量筛选后,我将名单缩小到了Unstructured、LlamaParse和Vectorize。

所有这些选项都支持多种文档类型,包括Microsoft Word、RTF、JSON、图像、PowerPoint等。(如果你对这些额外文档格式的类似比较感兴趣,请在评论中告诉我。)
此外,所有这些解析器都能够生成内容的markdown表示。这对RAG来说很重要,因为很多上下文信息是通过标题、图片、图表和格式传达的。我们希望保留这些信息,以便LLM能够更好地理解给定内容中的信息。
在这次比较中,我们将重点关注PDF。我要指出的是,这三个选项都是高质量的产品,代表了最好的。
1.1 Unstructured.io

Unstructured最初是一个PDF库,由于早期与LangChain的集成而广受欢迎。
在过去两年中,Unstructured扩展了他们的开源库,提供了一个用于文档提取的云服务。
Unstructured在其云中有三种提取选项:其基础选项定位为纯文本文档,价格为每1000页2美元;其高级选项为每1000页20美元;其铂金选项为每1000页30美元,可以处理像手写体这样的复杂情况。
Unstructured建议对PDF文档使用高级选项,这就是我们将要比较的内容。
你可以将Unstructured的解析器作为其云数据管道的一部分,也可以作为一个独立的API使用。
1.2 Llama Parse

Llama Parse来自LlamaIndex的开发者,包含在其Llama Cloud服务中。像Unstructured一样,Llama Parse也有多个选项。
他们的低成本产品起价为每1000页3美元,而他们的Llama Parse高级产品则贵得多,为每1000页45美元。
虽然Llama Parse每月包括一些可以解析的免费页面,但一旦达到这个限制,Llama Parse就成为比较中成本最高的选项。
你可以将Llama Parse作为Llama Cloud管道的一部分,也可以作为一个独立的API使用。
1.3 Vectorize.io

Vectorize是一个RAG即服务平台,提供两种提取器。
他们的Fast提取器在与他们的RAG管道服务一起使用时无需额外费用。它被定位为解决简单文档问题的解决方案,其中只需要简单的文本提取。
他们还提供Vectorize Iris,一个视觉模型提取器,可以在他们的RAG管道中以每1000页15美元的价格使用。
价格范围从每1000页0到15美元,Vectorize是所比较的托管选项中最便宜的。
目前,Vectorize只提供其解析器作为其RAG管道的一部分,而不是作为独立解决方案,但他们有一个提取测试器,你可以使用它来查看你的PDF将如何被解析。
2、评估标准
我想看看AI工程师在构建RAG解决方案时经常遇到的具有挑战性的PDF。为此,我决定根据各种类别的PDF文档评估每个提取器的表现。
对于每个类别,我将给出我个人的看法,并在必要时解释原因。我将根据以下评分标准对每个提取器进行排名:
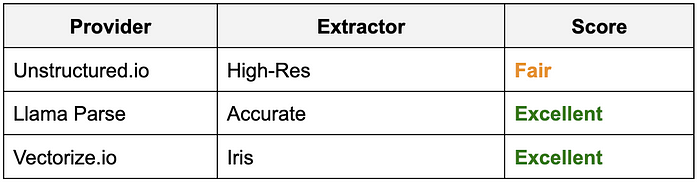
- 优秀 — 表示结果与我们期望看到的结果高度一致,没有重大问题。
- 良好 — 表示结果可能不完美,但它们产生合理的结果。例如,提取器将标题误认为粗体文本可能就是这种情况。
- 尚可 — 表示结果存在一些相当严重的问题。例如,提取器可能因文档布局而混淆并组合了两个无关的文本段落。
- 较差 — 表示结果不可用或严重错误。例如,如果提取器完全无法处理给定的文档类型,则会给予此评分。
3、简单文本
首先,我们将看一种最简单的案例。这些PDF中的文本在整个页面上是一致的,没有任何复杂的布局。我们将使用Project Gutenberg提供的《傲慢与偏见》PDF。

在这里,我们需要一个基准。PDF提取器应该能够准确地从纯文本PDF中提取文本。我们将分析竞争者是否能完全捕获文本,或者原始文本和提取的markdown之间是否存在任何不一致。
简单文本结果:
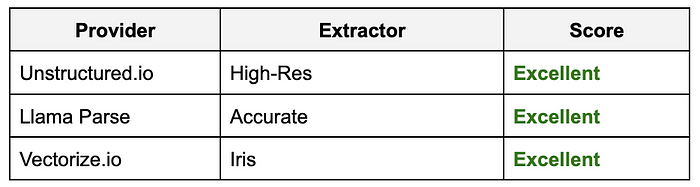
不出所料,所有三个测试的提取器在这个测试中表现得非常好。结果非常相似且准确,因此如果你主要处理这种类型的PDF,选择哪个都没有错。
需要注意的一点是,Llama Parse和Vectorize检测到了新段落并用\n\n表示,而Unstructured更准确地反映了原始文档中的行间距。从RAG的角度来看,用\n\n表示结构可能会给寻找这一特定字符组合来指示块边界分隔符的段落分割器带来轻微的优势。

也就是说,我不能责怪任何提取器在这个类别中的表现。
4、多列
常见的情况是PDF格式的内容跨越多列。这适用于从信息性小册子到学术论文的所有内容。我们将查看一篇发表文章的摘录,该文章具有简单的标题和文本,页面上的布局和装饰较少。

这里我们将主要关注两件事:
- 提取器如何表示一列到另一列的文本?
- 提取器如何处理跨页的文本?例如,第一页第三列的内容在第二页第一列继续。
多列结果:
Unstructured
总体而言,Unstructured的高分辨率提取器在这个案例中表现得很好。Unstructured解析器在到达列底部时引入了一个换行符,并在下一列顶部继续,但这在与RAG结合使用时不太可能造成任何问题。
Unstructured对跨页列的处理方式与其他两个提取器不同。这是一个正确行为可以有多种解释的领域。然而,我认为Unstructured的行为最适合RAG。
让我们看一下这两页之间的断点:

我们遇到了常见的页面底部有页脚,而下一页顶部有页眉的情况。有人可能会认为这些都应该完全排除在外,但从RAG的角度来看,这也是合理的,因为文档确实包含了这些元素。
然而,Unstructured的解析器似乎反映了大多数markdown使用标题来决定一个块何时结束以及下一个块开始的事实。因此,Unstructured的输出确实包括页脚和“NEWS FEATURE”,但它并没有将其作为标题,这允许markdown分割器正确地向LLM提供整个部分作为块。

如果这是有意为之,那么这是一种很好的细节关注,并且很可能会使RAG系统受益,所以我给Unstructured在这个类别中评为优秀。
Llama Parse
Llama Parse在几个关键方面表现不佳。例如,你可以看到,当我们在一页上有短标题,然后文本在下一页继续时。

然而,Llama Parse的输出将一大部分文本视为标题。这本身可能不会造成重大问题,但有一个更大的问题。
在整个文本中,Llama Parse将多列的文本视为连续的整体。不幸的是,这意味着如果我们依赖这个输出来驱动我们的RAG应用,我们将向LLM传递乱码。

即使Llama Parse在正确提取单列文本时也做得很好,它有时会在标题上犯糊涂,例如,在这一节中,你可以看到我们有标题“北爱尔兰视角”紧接着是“北爱尔兰交付……”

即使Llama Parse能够正确识别列,它也没有检测到标题,并似乎将标题文本与随后的段落文本合并在一起。

尽管存在这些问题,Llama Parse在某些区域还是提取了一些数据,所以我认为它在这个类别中值得一个尚可的评分。
Vectorize
Vectorize在这个类别中也表现得非常好。它的输出质量与Unstructured非常相似,只有少数细微的问题或可能是哲学上的差异。
在整个文本中,Vectorize保持各列文本分离,并生成了适合RAG的准确markdown表示。

这种方法反映了Anthropic研究人员在2024年关于上下文检索的报告中发现的一些好处。鉴于Vectorize Iris仅在其RAG管道中可用,这是一个不错的功能,可以帮助用户在不进行任何额外文本后处理的情况下获得更好的准确性。
然而,Vectorize的主要问题是头部拆分。Vectorize将页面标题视为markdown标题:

再次,我认为可以争论这种行为是一种更准确的表示。然而,当与RAG一起使用时,我认为这里产生纯文本比产生标题稍微好一些。
5、布局
这些通常是打印文档的扫描件。我们将使用一本儿童游戏杂志的页面。

这里我们希望看到提取器如何处理相关的逻辑文本块。在上面的图像中,这将包括突出显示的部分如幻想人物和词汇表,以及页面的主要文本。具体我们将评估:
- 提取器能否识别页面的相关部分并组织成合理的markdown表示。
- 提取器是否识别布局边界?
- 提取器如何处理页面中的图像?忽略它们?执行OCR?对非文本图像进行图像标题处理?
复杂布局结果:

Unstructured
Unstructured在这个测试中表现不佳,生成了大部分混乱的结果,缺乏布局意识。例如,在这一页上,我们有左侧的主体文本和右侧的信息框:

理想情况下,我们希望提取器能够识别这些是不同的部分,并相应地解析它们。然而,Unstructured在这里无法做到这一点。提取输出将这两个无关的文本段落结合起来:
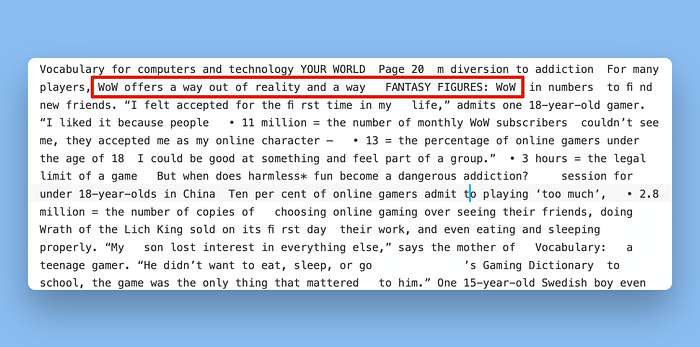
来自不同布局部分的文本被组合在一起,形成了一个不连贯的提取。将这传递给你的LLM进行RAG不太可能产生有用的结果,所以我给Unstructured这个类别一个较差的评分。
Llama Parse
Llama Parse很好地识别了单独的内容块。你可以看到这一页有两个明显的内容框:

Llama Parse很好地处理了这种情况,将它们准确地分成markdown中的各个部分。

关于第二个框中的内容是否应该真正表示为表格有些争议。从RAG的角度来看,这不太可能引起问题。然而,第一行被表示为表格标题可能会让LLM感到困惑。
此外,Llama Parse改变了标题的大写形式,“FANTASY FIGURES: WoW IN NUMBERS”调整为“FANTASY FIGURES: WoW in numbers”。你还可以看到标题“VOCABULARY”的变化。它还错误地提取了标题“CLUB’S GAMING DICTIONARY”为“Gaming Dictionary”。
Llama Index在这例中错过了一些关键项目。例如,页面中间有一个显著的文本标题:

虽然Llama Parse能够正确提取标题和正文文本,但它错过了这个页面上一个相当重要的特性。

总的来说,考虑到复杂的布局和Llama Parse在这个页面上提取文本的良好表现,我仍然给它一个相当不错的良好评分。
Vectorize
Vectorize在这个例子中也做得非常好。它为各个内容块创建了干净的分区。

虽然Vectorize正确提取了文本并保留了标题的大写形式,但它在文本“2.8 million”中注入了一个反斜杠,使其变为“2.8 million”。当渲染时,这正确地显示为2.8 million,但在markdown中,. 不是特殊字符,因此没有必要以这种方式转义。
撇开挑剔不谈,Vectorize很好地提取了文本,并为帮助RAG系统理解页面上的非文本信息添加了图像标题。词汇表部分的格式丢失了,但从RAG的角度来看,这可能不会有太大影响:

而且考虑到它保留了大写并准确捕捉了页面上的所有内容,我将Vectorize评为这个类别的优秀。
6、扫描文档
这里我们不仅要看干净扫描的文档,还要看现实世界中可能杂乱无章的文档。例如,手动扫描或通过传真获得的图像可能倾斜且有时扭曲。我们将使用此类示例来评估这一标准:

我们将比较每个提取器如何处理常见情况:
- 提取器能否准确生成扫描PDF的markdown表示?
- 提取器能否处理文档居中或倾斜的情况?
- 提取器能否处理混合手写和打印内容的情况?
扫描文档结果:
Unstructured
不幸的是,Unstructured无法处理这个扫描不良的文档。它生成了空白输出,因此在此类别中被评为差。
Llama Parse
考虑到输入的难度,Llama Parse生成了相当不错但并不完美的结果。例如,我们可以看到文档顶部的文本与Llama Parse生成的文本对比:

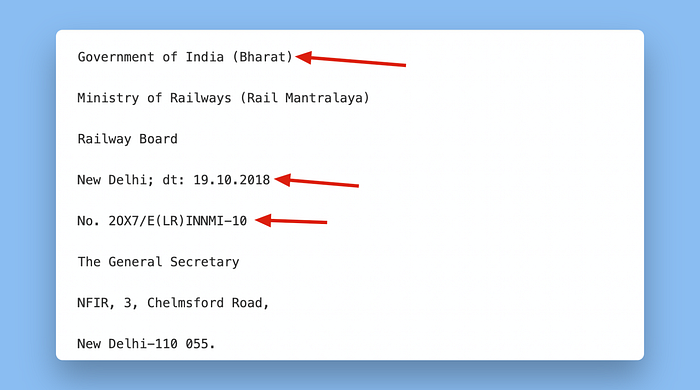
你可以看到,(Bharat Sarkar)被提取为只是(Bharat)。
原始日期19.02.2018被错误提取为19.10.2018。
文本“№2017/E(LR)I/NM1–10”略有不同,多了一个X且缺少了一个斜杠。
我们还在文档正文中看到URL被截断,省略了主URL后的路径:

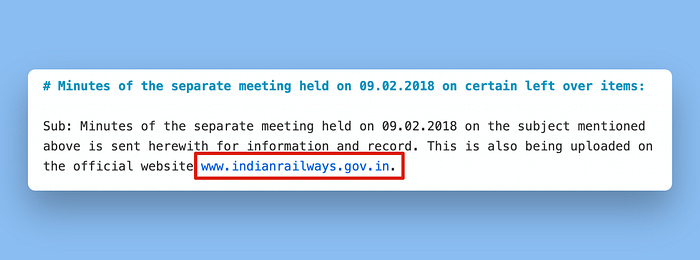
这些差异对RAG系统来说可能有很大影响,因为整个目标是让你的LLM获得准确的结果。如果你的提取器生成错误的日期和错误的URL,你可以想象这种情况可能导致你的LLM给用户提供错误的结果。
话虽如此,这是一个特别具有挑战性的PDF,考虑到输出总体上是准确的,我认为Llama Parse在这里仍值得一个良好评分。
Vectorize
Vectorize在这个测试中表现出色。它基本上将传真机卡纸的纸张完全正确地提取出来。
比较上面我们查看的相同文本部分,你可以看到Vectorize正确提取了标题的所有细节:
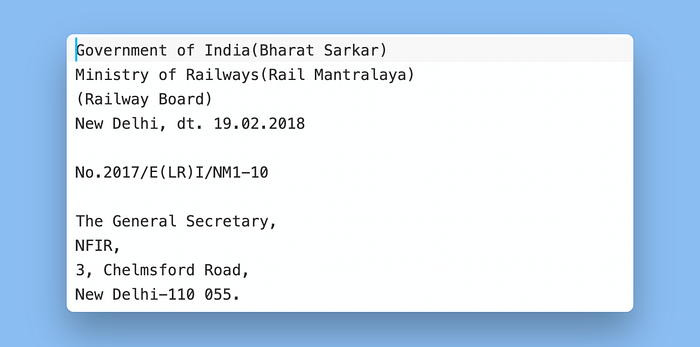
全名、日期和文本“№2017/E(LR)I/NM1–10”都与原始文本完全一致。
同样,扫描内容和URL都是逐字匹配。Vectorize显然是这一类别中最好的,获得了优秀的评分。
7、表格密集型
在构建需要处理PDF的RAG系统时,人们最常见的需求之一是对表格数据的准确表示。为此,我们将使用SEC文件,这些文件具有一些具有挑战性的特征:
- 表格没有清晰的边框来表示行和列。
- 表格有缩进和跨越多列的单元格。
- 表格有显示一组行总和的行。

这里我们将关注以下行为:
- 提取器能否准确识别内容中的表格?
- 提取器如何处理表格内的格式,如跨越多列的文本?
- 提取器如何处理跨越多页的表格?
表格密集型结果:
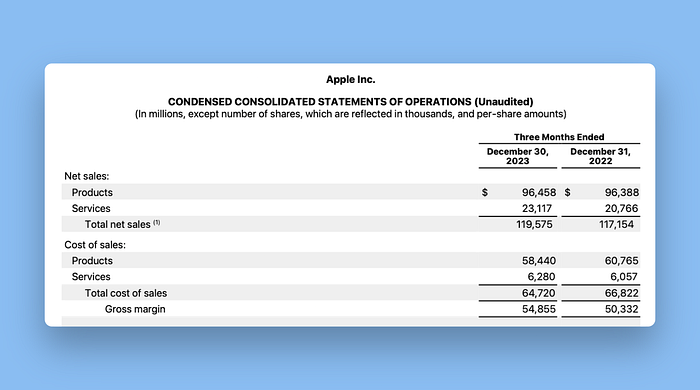
Unstructured
Unstructured能够提取我们使用的季度报告中的文本,但完全失去了表格的格式。例如,上面所示的表格被提取为:

虽然准确,但LLM可能无法正确解释这些季度结果。
总体而言,布局信息的完全丢失使我给Unstructured在这个类别中评为尚可。
Llama Parse
Llama Parse在提取表格方面做得很好。
在原始PDF中,没有明确的列标记:
鉴于此输入,我认为Llama Parse在生成此表格时做出了一些合理的艺术选择。在markdown中更容易看到Llama Parse如何处理这些表格:
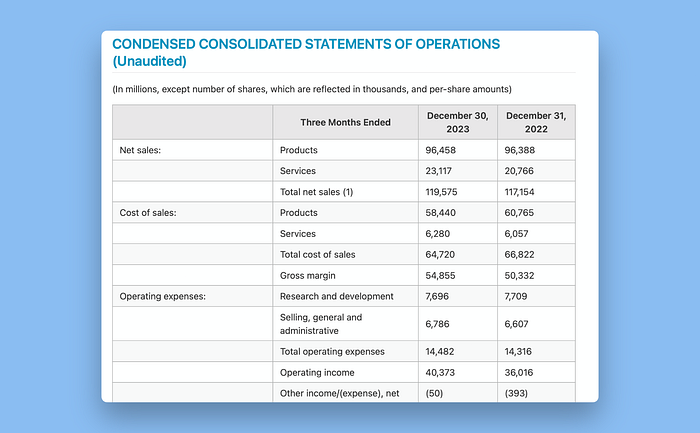
输出有几个可争议的特点。首先,“Three Months Ended”似乎不太适合作为第二列的标题。不过,markdown在处理像跨列单元格这样的事情上能力有限,这是一个合理的选择。
同样,原稿中第一列的项目在单独一行上,而在提取中它们与其他数据在同一行上。总体而言,我认为这仍然是一个好的表示,并且如果作为上下文提供给RAG系统中的LLM,应该可以很好地处理。
随着我们深入季度报告,我们发现关于合并资产负债表的部分出现了更微妙的关于表格边界的状况。
例如,在关于合并资产负债表的部分,我们有可视为一个大表格的东西:
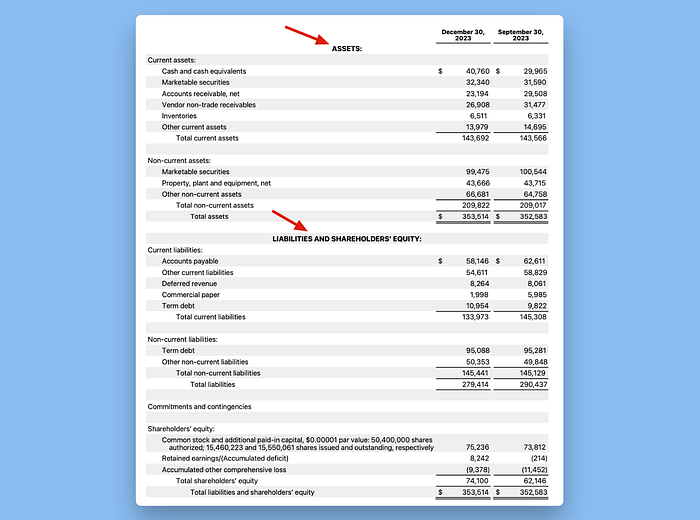
然而,Llama Parse将其分解为两个。将“Assets”作为第一个示例的表格标题,但将“Liability and Shareholders’ Equity”移到标题中,尽管它们的格式相同。
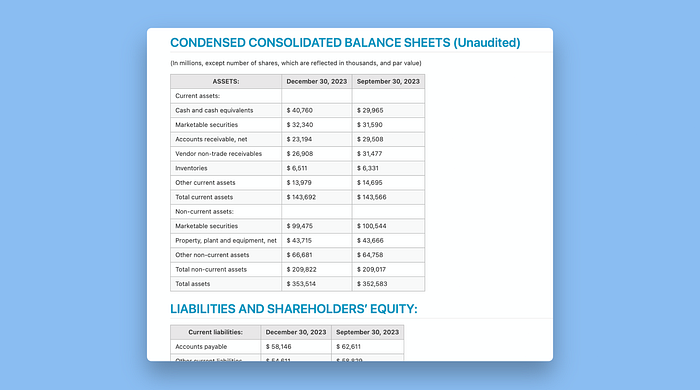
有趣的是,尽管在原始表格中不存在,Llama Parse足够聪明地在分裂的表格顶部重复了这个标题。
考虑到这些表格的模糊性质,我认为Llama Parse仍然值得一个优秀评分。
Vectorize
Vectorize在这个例子中与Llama Parse不分伯仲。虽然做出了略微不同的决策,Vectorize也在合理的方式下准确地保留了表格结构。
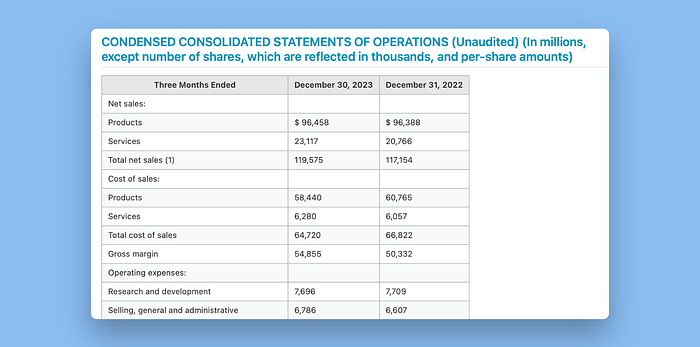
在这里,Vectorize更准确地表示了在提取表格中处于不同行的项目。然而,它确实失去了在原始表格中,以下几行缩进以传达数据层次结构的事实。
查看我们之前用Llama Parse检查过的较长表格,我们可以看到Vectorize也将其分为两个表格,并向前传递了表格头。Vectorize在一致表示标题方面做得比Llama Parse稍好:
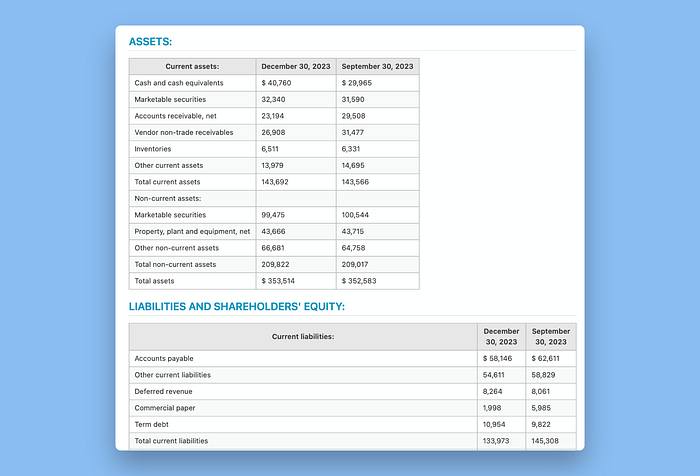
8、结束语
我在这里考察的每个PDF提取器都有其优点和缺点,以及不同的价格点。根据你的需求,所有三个都可以成为你下一个RAG系统的绝佳选择。
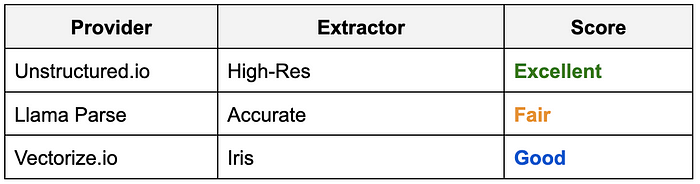
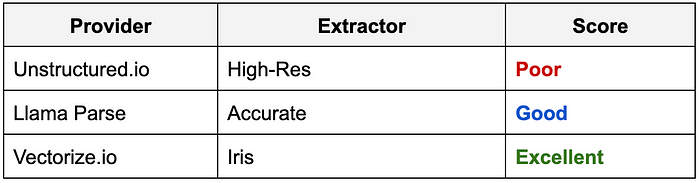
根据每个类别的结果,我的经验如下:
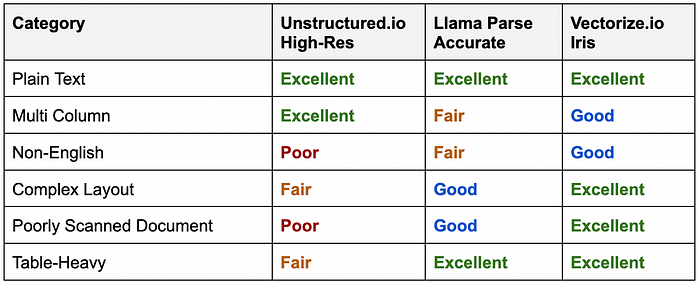
我建议你自己尝试一下所有三个,看看你的结果与我在测试中的结果有何不同。不可能测试你在处理PDF时可能遇到的所有可能场景,所以我建议尝试这三个选项,看看哪个最适合你。
原文链接:What’s the Best PDF Extractor for RAG? I Tried LlamaParse, Unstructured and Vectorize
汇智网翻译整理,转载请标明出处
