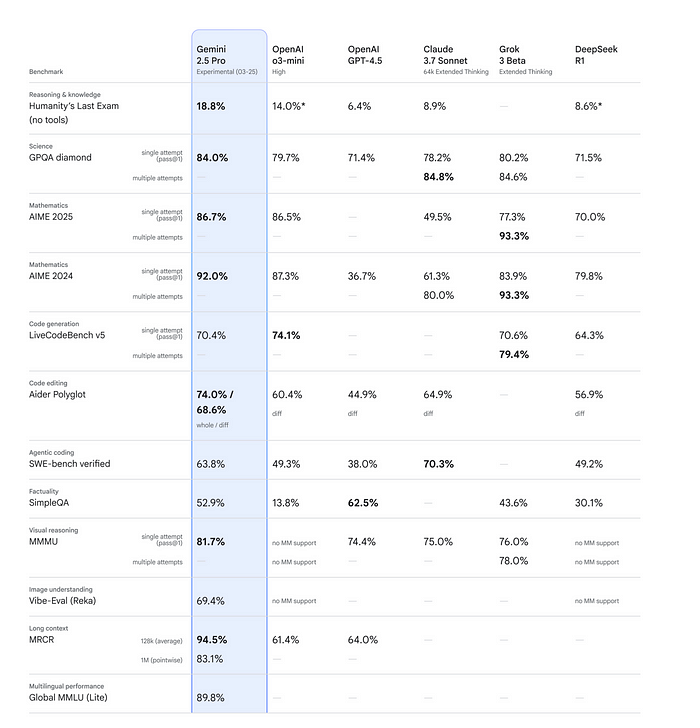
5个最强前端代码生成AI模型对比
本文在一个真实的前端开发任务上对比了Grok 3、Gemini 2.5 Pro、DeepSeek V3、OpenAI o1-pro和Claude 3.7 Sonnet的效果。

本周对人工智能来说是一个疯狂的一周。
DeepSeek V3刚刚发布。根据基准测试,它是目前最好的AI模型,甚至超过了像Grok 3这样的推理模型。
就在几天后,谷歌发布了Gemini 2.5 Pro,再次在基准测试中击败了其他所有模型。
随着这些模型的推出,大家都在问同一个问题:
“哪个是最佳的编程模型?”——我们的集体意识
本文将探讨这个问题在一个真实的前端开发任务中。
1、准备任务
为了完成这个任务,我们需要给LLM足够的信息来完成它。我们将如何做到这一点。
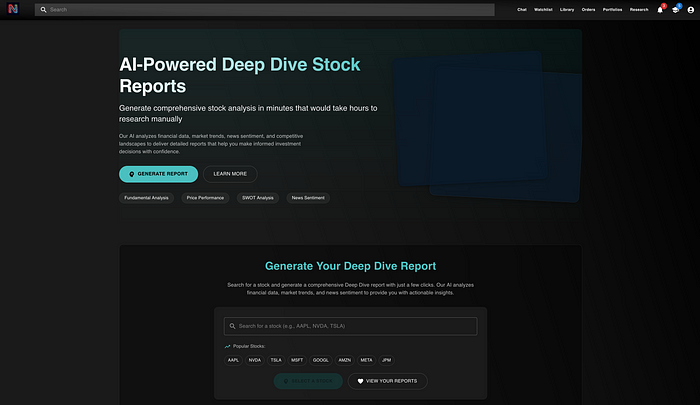
作为背景,我正在构建一个算法交易平台。其中一个功能叫做“深度挖掘”,即AI生成的全面尽职调查报告。我在这篇文章中详细介绍了这一功能。
尽管我已经发布了这个功能,但我没有一个SEO优化的入口点。因此,我想看看每个最好的LLM能否为这个功能生成一个着陆页。
为此:
- 我构建了一个系统提示,塞满了足够的上下文以一次性解决问题。
- 我对每个模型都使用了相同的系统提示。
- 我只根据我对前端效果的主观意见来评估模型。
我从系统提示开始。
2、构建完美的系统提示
为了构建我的系统提示,我做了以下几件事:
- 给它提供了我的文章的markdown版本,以便了解该功能的作用。
- 提供了生成页面所需单个组件的代码示例。
- 列出了一些约束和要求。例如,我想能够从着陆页生成报告,并在提示中解释了这一点。
系统提示的最后一部分是详细的对象部分,说明了我们要构建的内容。
# 目标
构建一个SEO优化的前端页面用于深度挖掘报告。
虽然我们已经在资产仪表板上可以生成报告,但我们希望
这个页面能够帮助我们找到搜索股票分析、DD报告等的用户。
- 页面应该有一个搜索栏,并且能够在页面上直接生成报告。这是主要的CTA
- 当用户点击时,如果他们未登录,会提示他们注册
- 页面应该解释所有的好处并针对寻找股票分析、尽职调查报告等的人进行SEO优化
- 优秀的UI/UX是必须的
- 你可以使用package.json中的任何包,但不能添加新的包
- 专注于良好的UI/UX和编码风格
- 生成完整的代码,并将其分成不同的组件,包括主页面
要查看完整的系统提示,我将其公开链接在此Google文档中。
然后,使用这个提示,我想测试所有最好的语言模型的输出:Grok 3、Gemini 2.5 Pro(实验版)、DeepSeek V3 0324和Claude 3.7 Sonnet。
我按照从差到好的顺序组织了这篇文章。让我们从最差的模型开始:Grok 3。
3、测试Grok 3(思考)
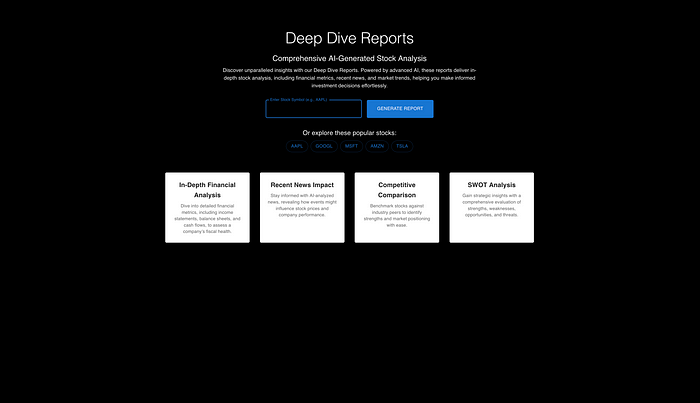
说实话,尽管我对Grok抱有很高的期望,因为它在其他具有挑战性的编码“思考”任务中表现出色,在这个任务中,Grok 3做得非常基础。它的输出是我预期GPT-4能做到的。
我是说,看看这个。这不是一个SEO优化的页面;谁会用这个?
相比之下,O1-Pro做得更好,但也不多。
4、测试GPT O1-Pro
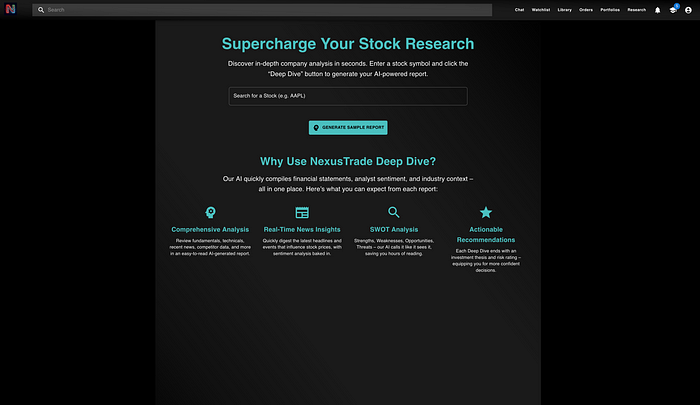
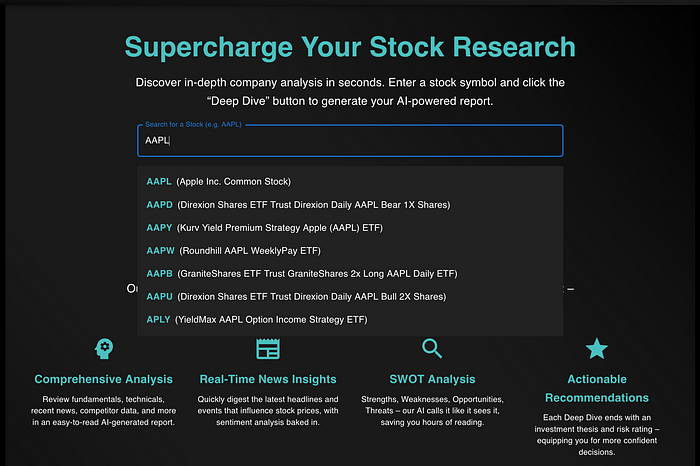
O1-Pro在保持与代码示例相同样式方面做得更好。特别是搜索栏看起来比Grok好。它使用了我正在使用的图标包,格式也总体上相当不错。
但它绝对不是生产就绪的。对于Grok和O1-Pro,输出是你期望一个刚上Intro to Web Development课程的实习生能做的。
其余的模型做得更好。
5、测试Gemini 2.5 Pro


Gemini 2.5 Pro第一次尝试就生成了一个令人惊叹的着陆页。当我看到它时,我震惊了。它看起来专业,高度SEO优化,并且完全满足所有要求。
它重新使用了我的其他一些组件,比如我在现有深度挖掘报告页面上使用的显示组件。生成之后,我确实认为它会获胜……
直到我看到了DeepSeek V3的表现。
6、测试DeepSeek V3 0324



DeepSeek V3的表现比我想象的要好得多。作为一个非推理模型,我发现结果非常全面。它有一个英雄部分,大量的细节,甚至还有一个推荐部分。到这个时候,我已经对这些模型的进步感到震惊,并认为Gemini会在这一点上成为无可争议的冠军。
然后我完成了Claude 3.7 Sonnet的测试。哇,我简直无法更震撼了。
7、测试Claude 3.7 Sonnet

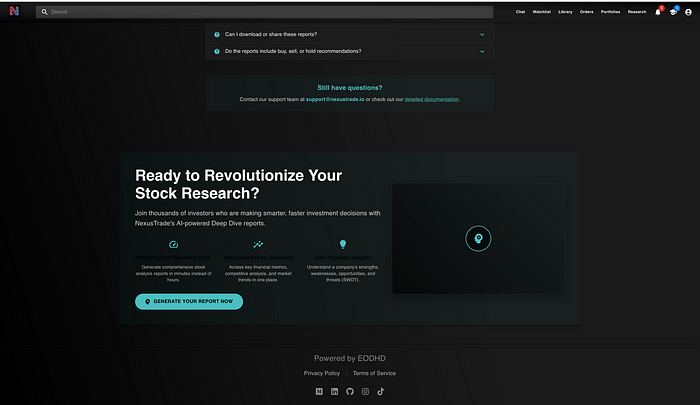
由Claude 3.7 Sonnet生成的号召行动部分独树一帜。使用完全相同的提示,我生成了一个极其复杂的前端着陆页,它不仅满足了我的具体需求,还超出了预期。
它超额交付了。确切地说,它包含了我从未想象过的内容。它不仅允许你直接从用户界面生成报告,还包含描述功能的新组件、经过SEO优化的文本、全面描述了好处、包括推荐信部分等更多内容。
它远远超出了全面性。
8、超越主观外观的讨论
虽然这些着陆页的视觉元素都很出色,但我还想简要讨论一下代码的其他方面。
首先,有些模型在使用共享库和组件方面做得比其他模型更好。例如,DeepSeek V3 和 Grok 没有正确实现“OnePageTemplate”,这是负责头部和尾部的部分。相比之下,O1-Pro、Gemini 2.5 Pro 和 Claude 3.7 Sonnet正确地利用了这些模板。
此外,所有模型生成的原始代码质量惊人地一致,没有出现任何主要错误。所有模型都生成了干净、可读的代码,具有适当的命名约定和结构。
此外,模型使用的组件确保页面在移动设备上友好。这一点至关重要,因为它保证了不同设备上的良好用户体验。由于我使用的是 Material UI,每个模型都能独立做到这一点。
最后,Claude 3.7 儿歌因其产生的高质量代码量最大且不牺牲可维护性而应得到认可。它创建了更多的组件和功能,每个部分仍然保持良好的结构并无缝集成。这表明 Claude 在前端开发方面的优越性。
9、关于这些结果的注意事项
尽管 Claude 3.7 Sonnet产生了最高质量的输出,但在选择哪个模型时,开发者应该考虑几个重要的因素。
首先,除了 O1-Pro 外,每个模型都需要手动清理。修复导入、更新副本以及获取(或生成)图像大约需要我1到2个小时的手动工作,即使对于 Claude 的综合输出也是如此。这证实了这些工具在初稿方面表现出色,但仍需要人类的精炼。
其次,成本性能权衡非常重要。
- O1-Pro 是迄今为止最昂贵的选择,每百万个输入令牌的成本为150美元,每百万个输出令牌的成本为600美元。相比之下,第二昂贵的模型(Claude 3.7 儿歌)每百万个输入令牌的成本为3美元,每百万个输出令牌的成本为15美元。它的吞吐量也相对较低,与 DeepSeek V3 相同,为每秒18个令牌。
- Claude 3.7 Sonnet的吞吐量是 O1-Pro 的3倍,且便宜50倍。它还为前端任务生成了更好的代码。这些结果表明,对于前端开发,您绝对应该选择 Claude 3.7 儿歌而不是 O1-Pro。
- V3 比 Claude 3.7 Sonet便宜超过10倍,使其成为预算友好的项目的理想选择。它的吞吐量与 O1-Pro 类似,为每秒17个令牌。
- 同时,Gemini Pro 2.5 当前提供免费访问,并以 Claude Sonnet速度的两倍处理最快。
- Grok 受其缺乏 API 访问的限制。
重要的是,值得讨论 Claude 的“继续”功能。与其他模型不同,Claude 有一个选项可以在耗尽上下文后继续生成代码——这比其他模型的一次性输出更具优势。然而,这也意味着比较并不完全平衡,因为其他模型必须在更严格的令牌限制下工作。
“最佳”选择完全取决于你的优先事项:
- 纯代码质量 → Claude 3.7 Sonnect
- 速度+成本 → Gemini Pro 2.5(免费/最快)
- 大型、预算友好或 API 功能 → DeepSeek V3(最便宜)
最终,尽管 Claude 在这项任务中表现最佳,但最适合您的模型取决于您的需求、项目以及您认为模型最重要的方面。
10、结论性思考
随着大量新语言模型的发布,很难清楚地回答哪个模型是最好的。因此,我决定进行头对头比较。
就纯代码质量而言,Claude 3.7 Sonnet在这项测试中脱颖而出,展示了对技术要求和技术美学的卓越理解。它能够创建一个完整的用户体验——包括推荐信、比较部分和功能齐全的报告生成器——使其在前端开发任务中领先于竞争对手。然而,DeepSeek V3 的出色表现表明专有模型和开源模型之间的差距正在迅速缩小。
话虽如此,本文基于我的主观意见。现在是时候同意或不同意 Claude 3.7 Sonnet是否做得很好,以及最终结果是否合理了。请在下面评论并告诉我您最喜欢哪个输出。
汇智网翻译整理,转载请标明出处
