7个顶级AI模型的编程能力对比
我想看看这些LLM模型的进步程度,所以我让不同的AI模型构建一个简单的宝可梦游戏,结果令人惊讶。

技术发展迅速,我们似乎一直在接收新的更新和改进的大语言模型(LLMs)。Claude 3.5 Sonnet 在进行与编程相关的工作时一直领先。但是否仍然是这一类别的最佳选择,或者已被今天可用的许多新LLM模型超越?
我想看看这些LLM模型的进步程度,所以我创建了一个测试来找出哪个模型表现最好。这篇文章是我之前在社交媒体上发布的一篇文章的后续。我让不同的AI模型构建一个简单的宝可梦游戏,结果令人惊讶。
我使用的提示是:
使用JavaScript创建一个1对1的宝可梦战斗游戏,并使用这个网站上的精灵作为宝可梦 https://pokemondb.net/sprites
在第一次测试中,我使用了Claude 3.5 Sonnet、DeepSeek R1和ChatGPT-4o。在第二次测试中,我使用了更多的LLM来获得更好的概述。测试的LLM包括:
- DeepSeek R1
- Gemini 2.0 Flash Thinking Experimental
- Grok 2
- Mistral
- o3-mini(中等推理 - Windsurf)
- Qwen2.5-Max
- Claude 3.5 Sonnet
0、构建宝可梦游戏
在第二次测试中,我创建了一个更复杂的提示,以查看这些LLM模型在构建需要更高逻辑和思考的复杂应用程序时有多智能,我认为游戏总是测试这些类型用例的好方法。
这些测试的目标是在仅一次提示后看AI能完成什么。当然,我希望它们在用户进一步迭代链式提示后能够完成更多。
我使用的提示是:
使用JavaScript创建一个1对1的宝可梦战斗游戏,并使用这个网站上的精灵作为宝可梦 https://pokemondb.net/sprites 确保玩家可以在战斗过程中切换两个不同宝可梦,并且基于使用的宝可梦有类型和元素伤害。每个宝可梦至少应有四个可用攻击。玩家的宝可梦应该处于5级,而敌方宝可梦应该处于7级。考虑等级差异如何影响战斗,包括健康值等...
你可以在我的GitHub上找到所有宝可梦游戏 。
battle.js 文件是LLM生成的原始文件,这些文件损坏了。Claude修复了该文件夹中的_battle.js_ 文件。
这是我的测试结果。我将对它们进行星级评分,以便你可以看到哪些模型表现出色,哪些模型需要更多工作才能做得更好。
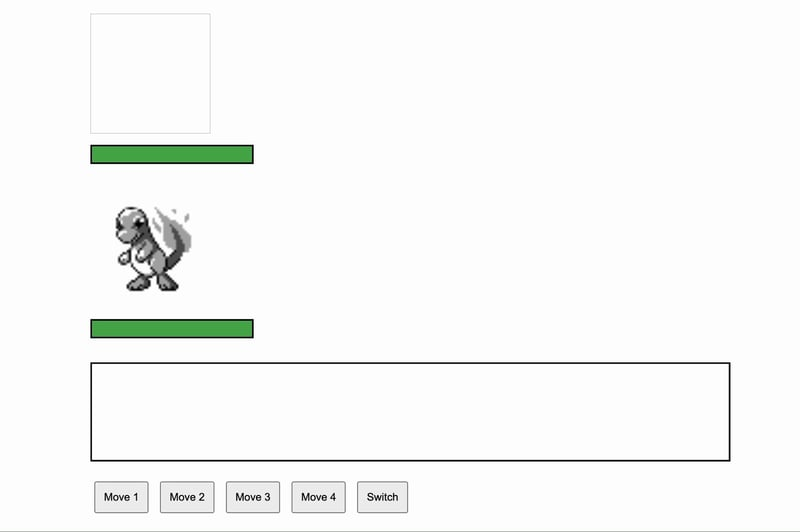
1、DeepSeek R1
LLM性能
DeepSeek R1 花了很长时间才开始编写代码。响应速度较慢,因为这个任务需要大量的思考。DeepSeek R1 思考了300秒,大约是5分钟,这是我使用DeepSeek R1进行任务时见过的最长的时间。然而,尽管思考过程很长,但链式思维过程还是很有意思的,我没有给这个任务设置时间限制,只要它能完成提示,我不介意花费更长时间。
游戏用户体验与逻辑
不幸的是,游戏基本功能不完整,无法完全运行。可以切换宝可梦。宝可梦有生命条,并且有四个可选动作,但这些动作都是通用的,没有像“雷霆”、“火焰”这样的名字。此外,只能使用一个动作,然后所有按钮都变成灰色,意味着无法继续游戏。另外,敌方宝可梦没有图像或GIF,只是一个空盒子。设计很简单,但需要更多的提示才能使游戏进入正常状态。
2、Gemini 2.0 Flash Thinking Experimental
LLM性能
所以Gemini 2.0 Flash用了大约15秒就回应了我的提示,这相当快。
游戏用户体验与逻辑
快速响应我的提示并没有降低Gemini的输出质量,因为它创造了一个功能齐全的游戏,设计相当不错。动画宝可梦、生命条、四个动作以及切换宝可梦的能力,还有战斗过程中所有动作的输出框。这绝对是这次测试中最好的游戏之一。
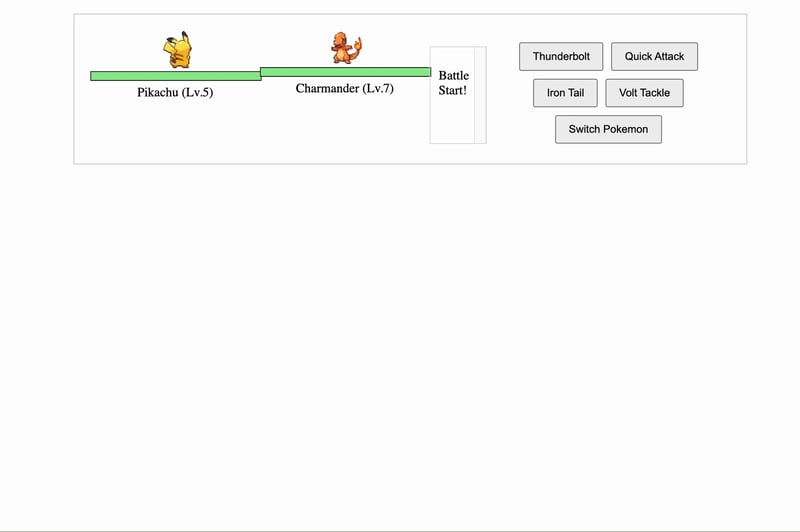
3、Grok 2
LLM性能
Grok 2 没有推理或链式思维。它大约用了1分钟完成提示请求。
游戏用户体验与逻辑
不幸的是,它提供的代码库是损坏的,无法运行。我决定使用Claude 3.5 Sonnet通过Windsurf IDE调试代码库,经过一次提示后就让它工作了。我没有为DeepSeek R1做这件事是因为游戏已经部分可玩,而Grok 2创建的版本存在一些bug,导致游戏根本不可玩。
修复代码库后,可以看到Grok 2实际上设计并构建了一个非常漂亮的游戏。游戏基本上实现了初始提示中所概述的基本内容,这是好的。但是,由于代码库损坏,Claude不得不修复它,因此扣分。
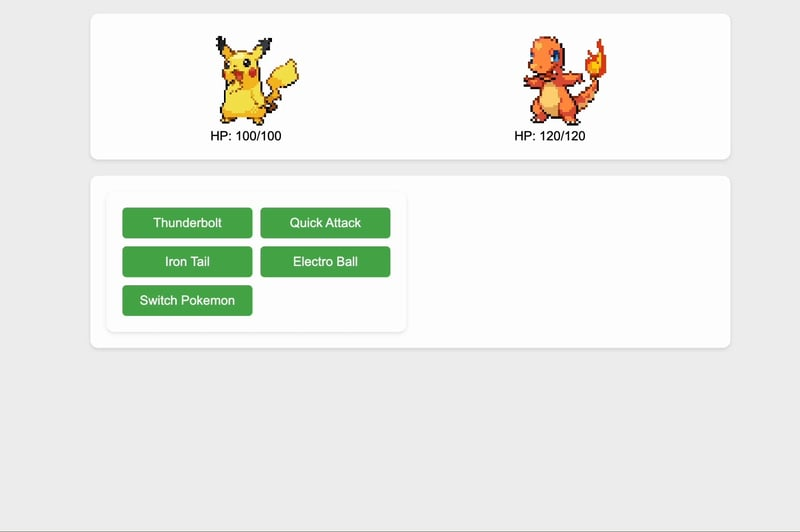
4、Mistral
LLM性能
它花了大约2秒生成代码库,这是所有测试过的LLM中最快速的。
游戏用户体验与逻辑
Mistral在仅仅2秒后就能创建一个功能齐全的游戏!设计虽然简单,但基本逻辑按预期工作。
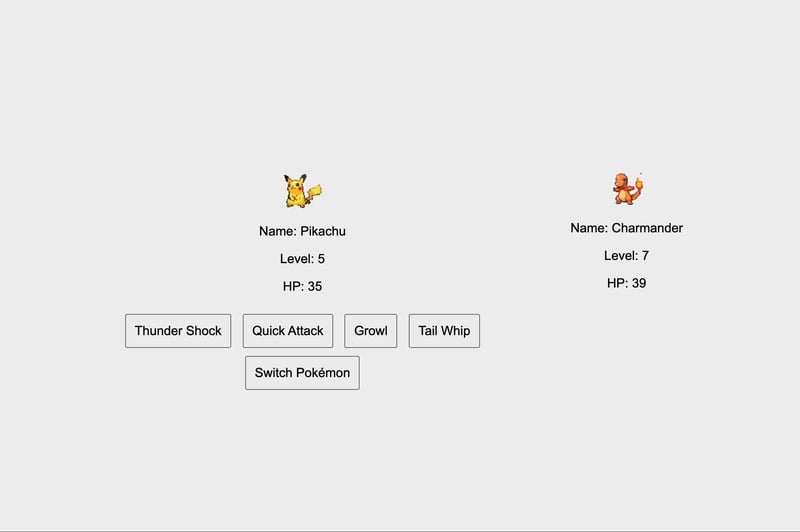
5、o3-mini(中等推理 - Windsurf)
LLM性能
它花了大约5秒创建一个应用的行动计划。然后,大约又花了10秒在创建了空的index.html、styles.css和battle.js文件后生成代码库。
游戏用户体验与逻辑
设置完成后,它首次尝试就成功创建了一个可工作的应用程序!游戏按预期工作并满足了初始提示中设定的要求。如果要提出一个意见,那就是所有的动作按钮都有通用名称,如“攻击1”、“攻击2”等,尽管在输出屏幕上显示了使用了哪种攻击。如果按钮名称与输出屏幕上的攻击名称匹配会更好。
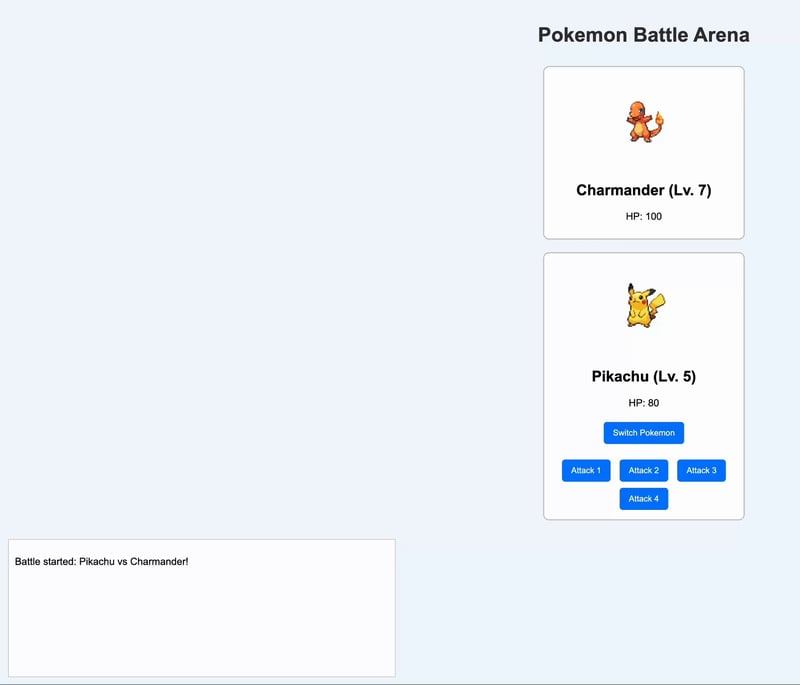
6、Qwen2.5-Max
LLM性能
它花了大约1分钟生成代码库,这不算太差。
游戏用户体验与逻辑
JavaScript文件有一个错误,虽然HTML能在浏览器中工作。但功能并不工作,所以我使用Claude 3.5 Sonnet通过Windsurf IDE调试代码库,经过一次提示后就让它工作了。
游戏工作并且实现了初始提示中概述的内容。然而,游戏逻辑需要很大的改进。首先,当切换宝可梦时,攻击动作保持不变,因此对于新宝可梦来说这些动作并不相关。其次,伤害似乎固定在一个数值上,当宝可梦的生命值为100时,这意味着战斗将持续很长时间...
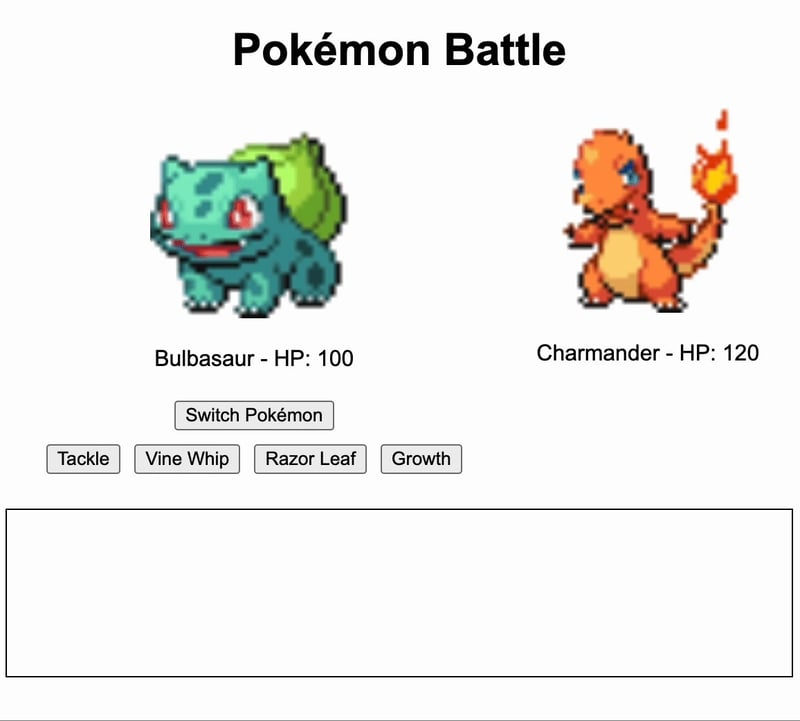
7、Claude 3.5 Sonnet
LLM性能
它花了大约1分钟生成代码库,这完全可以接受。
游戏用户体验与逻辑
游戏是功能性的。然而,它创建了占位符图像用于宝可梦,并要求用户手动下载精灵替换占位符。但它提供了替换的说明。这可能是因为Claude无法像其他LLM那样搜索网络,因此无法阅读文档。值得注意的是,我在这个测试中使用了Claude网站。如果我使用一个可以访问网络的IDE,比如Windsurf,那么结果可能会更好。
这是唯一一个具有动画生命条的游戏,很酷。不过我不确定游戏逻辑。要么是敌方宝可梦很强,要么是玩家的宝可梦每次攻击都会伤害自己,因为它们的生命条下降得太快。😂此外,游戏中没有电系宝可梦,但有电系攻击,这不合常理。😂
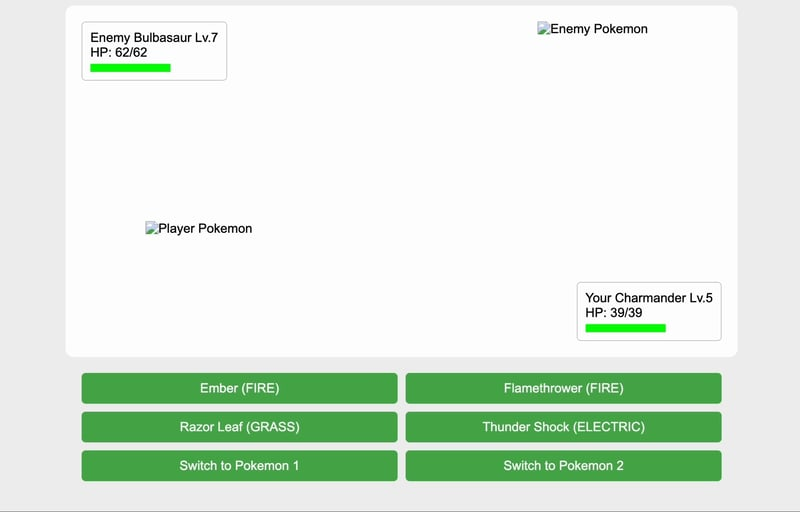
8、结束语
看到AI进步到这种程度并朝着这个方向发展真是不可思议。今天,我们了解了一些目前最领先的LLM模型的当前能力。从一个提示就能生成相当复杂的可工作代码库,这确实是一个伟大的景象。考虑到我使用的提示虽然详细但省略了一些信息,AI模型仍然能够理解我所指的大部分内容,这表明它们在这些工作中变得多么有用。
这个测试不是非常科学,但这是一个快速有趣的测试,旨在了解这些模型在很少的人工干预下从零开始构建东西的能力。根据这项简短的研究,我会给每个LLM以下评级和排名。
| AI LLM | 评分 |
|---|---|
| DeepSeek R1 | ⭐️ |
| Gemini 2.0 Flash Thinking Experimental | ⭐️⭐️⭐️⭐️⭐️ |
| Grok 2 | ⭐️⭐️⭐️ |
| Mistral | ⭐️⭐️⭐️⭐️ |
| o3-mini(中等推理 - Windsurf) | ⭐️⭐️⭐️⭐️ |
| Qwen2.5-Max | ⭐️⭐️ |
| Claude 3.5 Sonnet | ⭐️⭐⭐ |
因此,DeepSeek R1在这次测试中只得到了一颗星,因为游戏没有完全正常运行。令人惊讶的是,Gemini 2.0 Flash以五颗星的成绩脱颖而出。Grok 2只得到了三颗星,因为其代码库需要Claude修复后才能正常工作。
Mistral和o3-mini(中等推理)产生了相当不错的整体游戏。Qwen2.5-Max创建了一个游戏,只有在Claude调试代码库后才能正常工作。游戏逻辑需要很大改进,因为攻击只造成1点伤害,赢得游戏会很乏味和无聊... 😂
最后,Claude只得到了三颗星,因为游戏逻辑有点奇怪,而且由于无法搜索网络,它不能像其他游戏一样显示宝可梦图像。然而,它获得了荣誉提名,因为它修复了两个破损的代码库并在一次提示后使其游戏正常运行!如果我使用Claude 3.5 Sonnet在一个可以访问网络的IDE,如Windsurf或Cursor中,那么在构建这个游戏时它可能会产生更好的结果。
原文链接:I Tested the Top AI Models to Build the Same App - Here are the Shocking Results!
汇智网翻译整理,转载请标明出处
