9个主流OCR模型的综合评测
在这篇博文中,我们比较了9种不同的 OCR 解决方案,并比较了它们在工业 OCR 应用的10个不同领域的功效。
光学字符识别 (OCR) 使机器能够理解图像中的文本,从而允许程序和脚本处理文本。OCR 广泛应用于各种应用,但主要应用于文档相关场景,包括文档数字化和收据处理。
虽然文档 OCR 解决方案已得到深入研究,但目前 OCR 解决方案在非文档 OCR 应用(有时称为“场景 OCR”)(如读取车牌或徽标)方面的先进水平尚不明确。
在这篇博文中,我们比较了9种不同的 OCR 解决方案,并比较了它们在工业 OCR 应用的10个不同领域的功效。
1、OCR 解决方案
我们将测试9种不同的 OCR 模型:
- Tesseract(通过 PyTesseract 本地测试)
- EasyOCR(本地)
- Surya(本地)
- DocTR(通过 Roboflow Hosted API)
- OpenAI GPT-4 with Vision
- Google Gemini Pro 1.0
- Google Gemini Pro 1.5
- Anthropic Claude 3 Opus
- Hugging Face Idefics2
除了4个开源 OCR 专用软件包外,我们还测试了5个大型多模态模型 (LMM),GPT-4 with Vision、Gemini Pro 1.0、Gemini Pro 1.5 、Claude 3 Opus和HF Idefics2,它们之前都已在 OCR 任务中表现出有效性。
这是使用带有 Vision 的 OpenAI GPT-4 运行车牌识别逻辑的工作流演示 - 你可以使用自己的数据进行测试。

事不宜迟,让我们开始吧!
1、OCR 测试方法
大多数 OCR 解决方案以及基准测试主要用于阅读整页文本。根据我们在物理世界环境中部署计算机视觉模型的经验,我们看到了省略 OCR 模型中的“文本检测”或定位步骤的好处,转而采用自定义训练的对象检测模型,裁剪检测模型的结果以传递到 OCR 模型。
我们的目标和本次实验的范围是使用本地化文本示例测试尽可能多的非文档用例域。受自身经验和客户用例的影响,我们列出了10个不同的测试领域。

对于每个领域,我们从 Roboflow Universe 中选择一个开源数据集,并随机导入每个领域数据集中的十张图像。如果图像可以被人类合理读取,则将其包括在内。
在大多数情况下,领域图像是根据原始 Universe 数据集内进行的对象检测标注进行裁剪的。如果没有可裁剪的检测结果或检测结果包含可能在我们的测试中引入可变性的额外文本,我们会手动裁剪图像。
例如,对于车牌,我们使用的数据集包含整个车牌,在美国车牌的情况下,包括州、标语和登记贴纸。在这种情况下,我们裁剪图像以仅包含主要识别数字和字母。
为了创建一个与 OCR 预测进行比较的基准事实,我们手动读取每幅图像并用图像中出现的文本进行标注。
准备好数据集后,我们评估了每个 OCR 解决方案。计算了 Levenshtein 距离比(用于测量两个字符串之间差异的指标)并将其用于评分。
2、测试结果
我们的测试让我们对各种 OCR 解决方案以及何时使用它们有了一定了解。我们检查了结果的准确性、速度和成本方面。
2.1 准确性
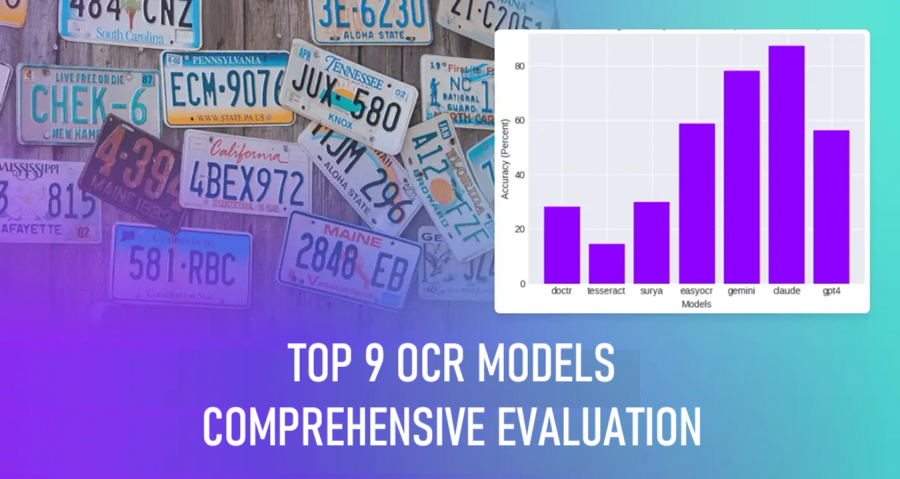
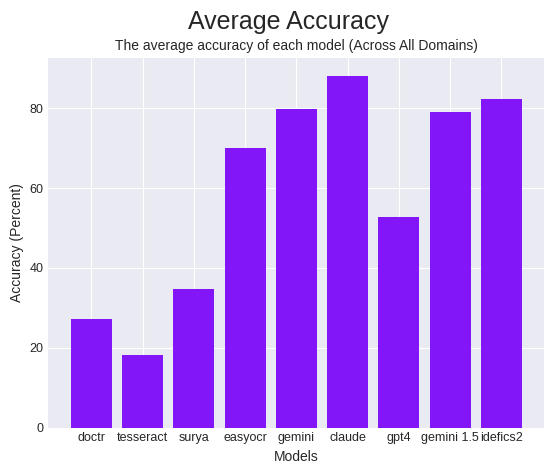
总体而言,考虑到所有领域,两个多模态 LLM - Gemini 和 Claude -表现最佳,其次是 EasyOCR 和 GPT-4。
中位准确率的总体趋势在大多数领域中持续存在。
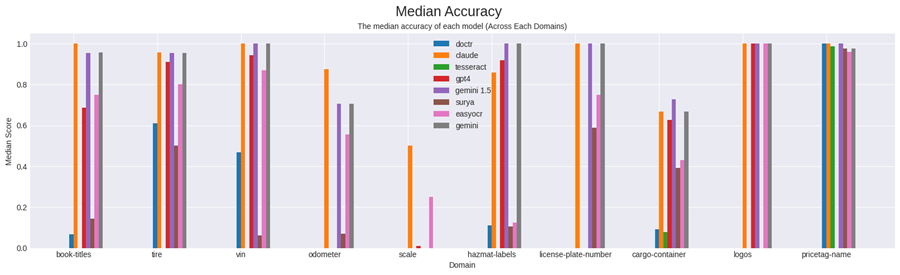
在所有领域中,Claude 获得最高准确率得分的次数最多,其次是 GPT-4 和 Gemini。EasyOCR 在大多数领域中表现良好,远远超过了其专业软件包同行,但与 LMM 相比表现不佳。
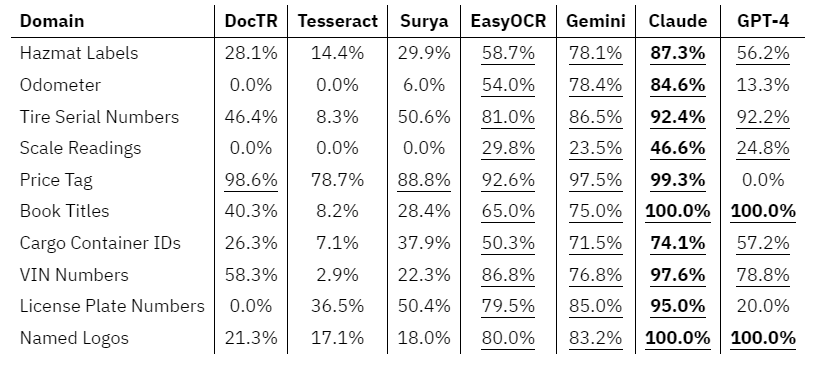
一个令人惊讶的值得注意的方面是 GPT-4 的拒绝率,它产生了无法使用的结果,并且重复尝试并未解决这个问题。我们将其视为零分,它显着降低或导致某些领域的总分为零,其他 LMM 完全没有遇到拒绝的情况。
2.2 速度
虽然准确的 OCR 很重要,但使用 OCR 时速度也是一个考虑因素。
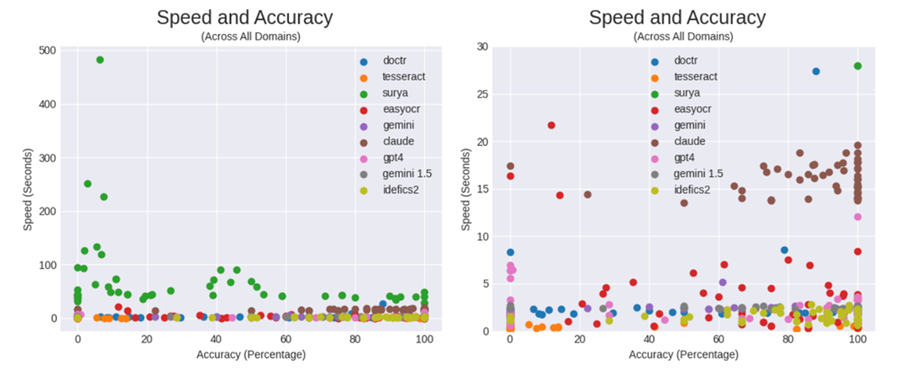
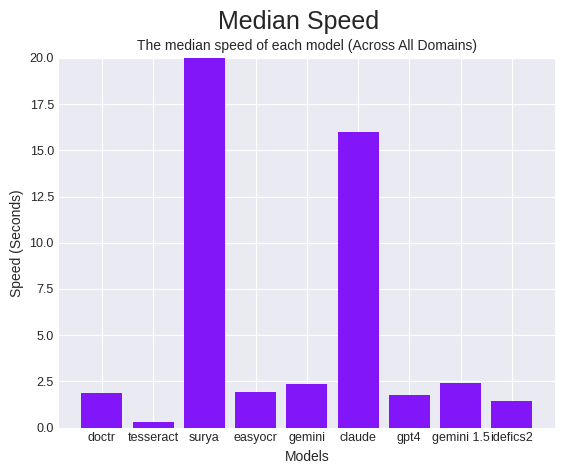
但是,速度并不能说明全部情况,因为快速但准确度很差的模型是没有用的。因此,我们计算了一个指标“速度效率”,我们将其定义为经过时间的准确度。
我们使用此指标的目标是显示模型的准确度,考虑到它所花费的时间。在这个类别中,Gemini 和 EasyOCR 以明显优势获胜,GPT-4 获得亚军。尽管 Calude 性能出色,但其响应时间缓慢,对其在此类别中的得分产生了负面影响。
2.3 成本
第三个需要考虑的因素是执行每个请求的实际成本。在大量使用的情况下,成本会迅速增加,了解其将产生的财务影响非常重要。
根据模型,这些成本的计算采用两种不同的方法之一完成。对于不提供本地推理选项的 LMM,我们直接根据使用的令牌数量(或 Gemini 中的字符)和相应模型的定价来计算成本。
对于本地运行的 OCR 模型,我们将 OCR 请求的成本计算为预测所需的时间乘以 Google Cloud 上虚拟机的成本。测试在 Google Colab CPU 环境中运行,我们将其等同于具有 2 个 vCPU 和 13 GB 内存的 Computer Engine E2 实例。
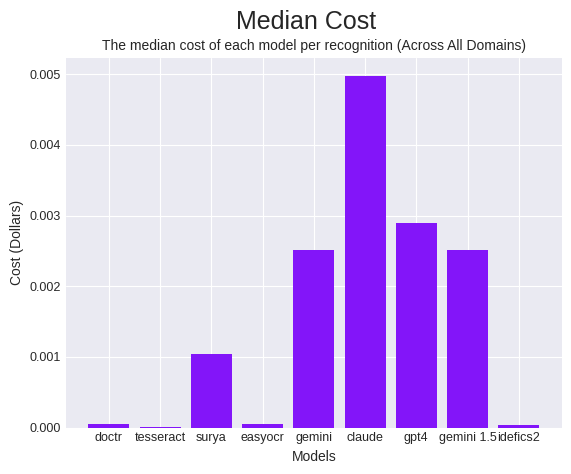
与 LMM 相比,DocTR、Tesseract、Surya 和 EasyOCR 的运行成本明显更低。与速度一样,单独的价格并不能有效指示其在现场的表现。
与我们计算速度效率的方式类似,我们计算了成本效率指标,定义为准确率除以价格成本。这将模型的性能与运行模型的价格联系起来。计算方法是将获得的分数除以请求成本。
EasyOCR 的成本效率最高,DocTR 和 Gemini 的排名明显较低。这种巨大差异的原因在于 EasyOCR 在准确率方面的表现相对令人印象深刻,同时它也是其主要竞争对手 LMM 的明显更便宜的替代品。
3、结束语
在这篇博文中,我们探讨了不同的 OCR 解决方案在工业视觉用例中常见领域的表现,并在速度、准确性和成本方面比较了 LMM 和开源解决方案。
在整个测试过程中,我们发现在本地运行 EasyOCR 可产生最具成本效益的 OCR 结果,同时保持具有竞争力的准确性,而 Anthropic 的 Claude 3 Opus 在最广泛的领域中表现最佳,而 Google 的 Gemini Pro 1.0 在速度效率方面表现最佳。
与本地开源 OCR 解决方案相比,EasyOCR 在所有指标上的表现都远远优于其同类产品,其表现接近或高于其他 LMM。
原文链接:Best OCR Models for Text Recognition in Images
汇智网翻译整理,转载请标明出处
