推理模型的训练:从原理到实践
我们采用了一个微小的 0.5B 参数模型,在我们的家庭实验室中向它投入了一些 GRPO,并设法教会它一些相当不错的推理技能。

推理模型并不完全是新事物,但 DeepSeek 的 R1 模型的发布在开源社区中引起了极大的兴奋。在阅读 DeepSeek-R1 论文后,我对他们的后训练技术特别感兴趣,据报道,该技术可以显着提高性能。
传统的后训练方法是监督微调 (SFT)。在 SFT 中,为模型提供提示和期望的输出,以了解用户偏好、结构对齐、安全协议等。本质上,SFT 展示了开发人员或用户对模型的期望,并引导它与这些示例保持一致。
既然已经提到了后训练,那么在深入研究 R1 的后训练方法之前,值得简要讨论一下预训练,因为两者是相关的。训练大型语言模型 (LLM) 的初始步骤之一是因果语言建模。在此阶段,模型通过关注前面的标记来学习预测序列中的下一个标记。此过程产生“基础”模型,这些模型以半监督的方式在大量公共文本数据上进行训练,没有明确的标签,以预测后续标记。说到公共文本数据,我们即将耗尽它(在某种程度上,在这种情况下忽略其他模式)。这种稀缺性是研究人员专注于 LLM 后训练阶段的主要驱动力之一。
回到后训练,存在许多技术,例如 SFT、PPO 和 DPO 等。虽然某些方法在特定领域表现更好,但它们通常会限制指令对齐的创作自由,或者在长时间运行中变得过于昂贵。相反,基础模型没有这些限制,但不可预测、难以指导,并且经常产生人类难以理解的输出。
R1 的作者发现了一种两全其美的方法:将原始模型与指令对齐,同时保留一定程度的创作自由。我不会在这里详细介绍整个过程,但从根本上讲,它们允许基础模型以相当大的自由度“推理”,同时设定专注于准确性和格式的简单目标。为了实现这一点,他们采用了强化学习,实施了一种称为“GRPO”(组相对策略优化)的优化技术。 GRPO 消除了对批评模型(传统上与策略模型大小相同并用于 PPO/DPO 等方法)的需求,而是使用聚合组分数计算基线。
将这种方法直接应用于基础模型产生了强大的推理能力,从而产生了 R1 模型的第一个版本:DeepSeek-R1-Zero。尽管该模型提高了基础模型的推理能力,但其输出通常难以被人类阅读或解释。如前所述,SFT 方法有助于模型遵循人类的偏好和可读性。然而,我们还讨论了 SFT 如何扼杀创作自由和泛化,如论文“SFT 记忆,RL 泛化:基础模型后训练的比较研究”中所述。
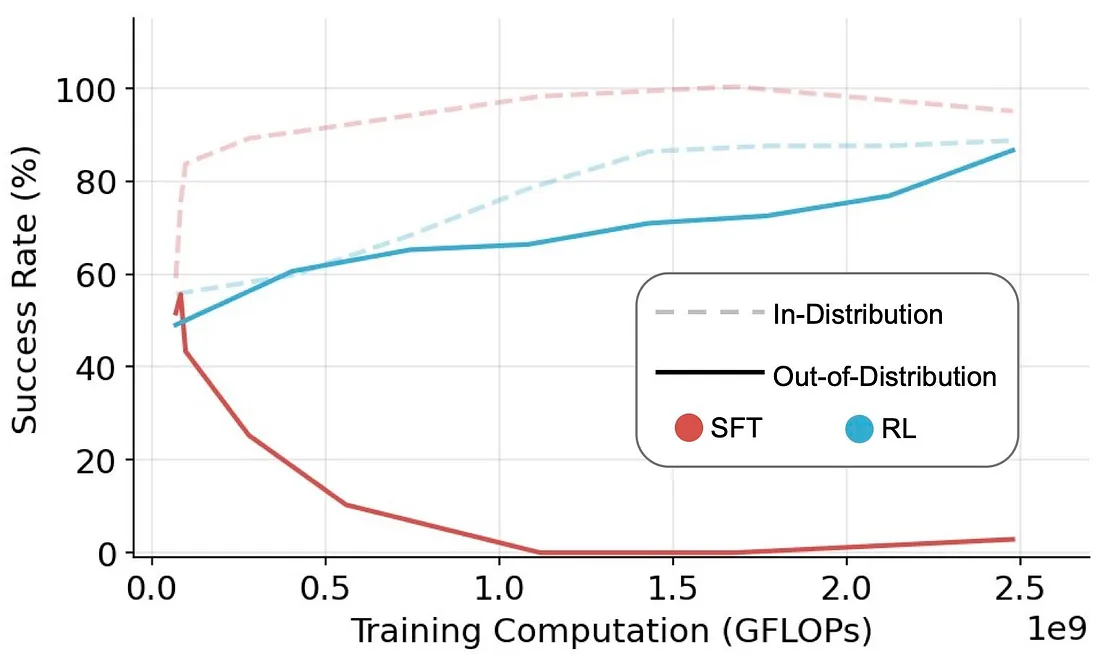
因此,作者在强化学习步骤之前使用了一个小型、高质量的数据集来“冷启动”他们的模型。这种方法在著名的 DeepSeek-R1 模型的创建中发挥了重要作用。在下一章中,我们将探讨其中一些技术的实现,以实现类似的结果。
1、强制推理
在他们的报告中,DeepSeek 提到了一组新的蒸馏模型。这些明显较小的模型使用 SFT 的蒸馏技术进行训练,利用了 DeepSeek-R1 的输出。值得注意的是,这些提炼模型没有经过任何强化学习步骤,这是一个有趣的观点,也是我们值得探索的领域。因此,如果我们不提炼模型,而是直接在原始模型上实现 GRPO,会怎么样?
我们可以继续使用基础模型或指导模型,假设指导模型已经“冷启动”。鉴于这是在我配备 RTX 3090 的本地游戏装备上进行的实验,我选择了 Qwen2.5–0.5B-Instruct 模型作为开始。对于 LLM 来说,这是一个参数数量非常少的模型,虽然它的局限性尚不确定,但值得尝试。
2、设置奖励
在原始论文中,作者使用了一个具有 671B 个参数的大型混合专家 (MoE) 模型。这种相当大的模型规模使他们能够为模型提供相当大的自由度,促进自由、稳健性和创造力。然而,就我而言,使用 0.5B 参数模型(是的,你没看错!),我感觉有必要实施更严格的规则来有效地指导模型。原始的 DeepSeek-R1 模型采用了两种主要的奖励来建模奖励:准确性和格式。这两个奖励旨在评估最终响应的正确性以及格式是否包含 和 标签内的推理步骤。
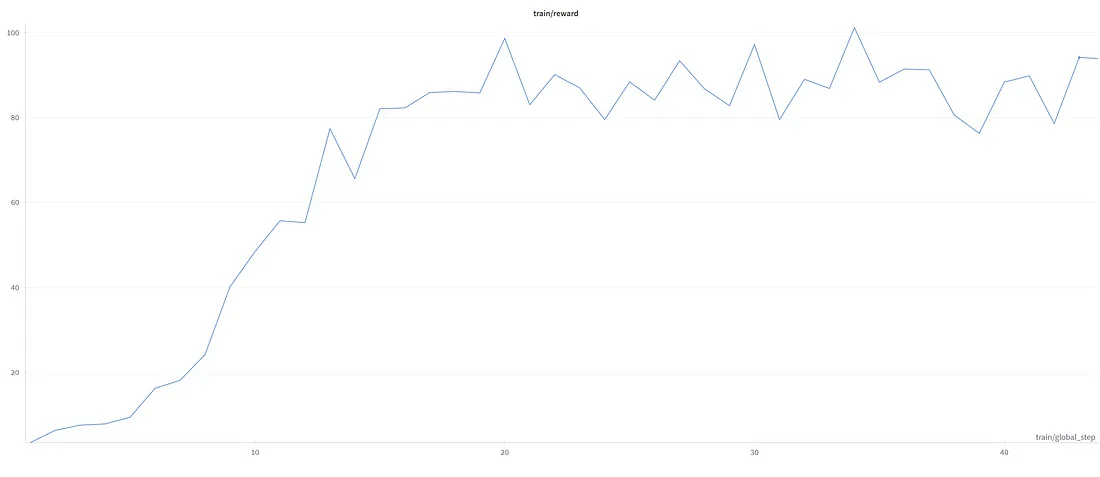
在我更受限制的场景中,我加入了一套更广泛的规则来奖励或惩罚模型:
- 答案是否正确?
- 它是否遵循建议的格式?
- 它是否包含推理标签?
- 如果存在推理标签,思考过程的长度是多少?
- 它是否包含验证标签?
- 如果存在验证标签,自我批评的长度是多少?
- 它是否使用“啊哈!”时刻标记?
我认识到其中一些奖励是主观的,可能不具有广泛的普遍性。但是,正如所提到的,我相信其中几个对于较小的模型和促进更快的训练是必不可少的。为代码中真正的任意奖励点做好准备!此外,考虑我们正在使用的数据集也很重要,因为其中一些规则是根据其特定特征量身定制的。数据集是 GSM8K(小学数学 8K),它包含语言多样的小学数学应用题。该数据集专门用于支持需要多步推理的基本数学问题的问答任务。因此,其中一些规则是特定于此数据集的任务,可能无法很好地概括。不过,请允许我解释一下这些奖励选择背后的一些理由。
- 对于准确性奖励,我们将提取
<answer></answer>标签之间的最终答案作为预测,并使用基本事实答案检查它们的准确性。 - 格式化部分是检查推理、批评和答案部分的标签是否遵循一般结构。
这两个与原始论文相似,但其余的取决于你的任务和创造力。
为了鼓励更长的思考过程,我计算了推理和验证标签之间的单词数量,并将其作为奖励添加到一定范围内。(以防止模型利用无用的长答案)
原始作品提到“啊哈!”时刻在推理过程中自然发生。虽然更大的模型和更长的训练程序也有可能出现这种情况,但在我的场景中,我设置了一个俗气的游戏规则来强制这一时刻。
在最近的一篇论文 《s1:简单的测试时间缩放中》,作者在模型准备结束预测序列时插入了一个“等待”标记,以迫使它们重新思考。这听起来很像“啊哈!”时刻,所以我就把这个想法插入到我的奖励函数中。
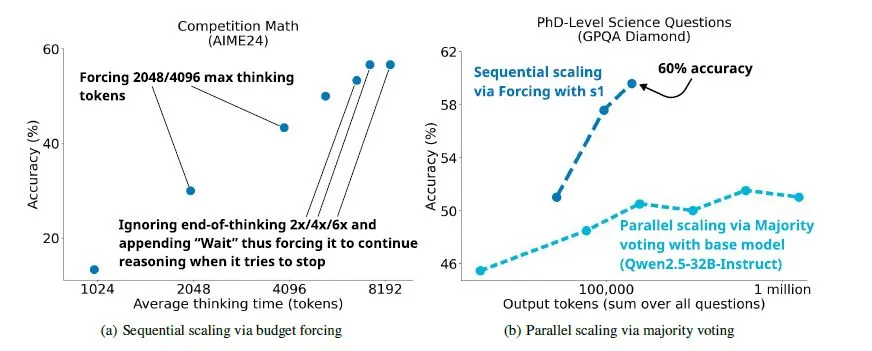
基本上,如果有一个“啊哈!”时刻,比如“等待,但或重新思考”,然后是最少的字符,我会设置巨大的奖励来鼓励这种思考,并将其设置为系统提示。
3、剧透警告!
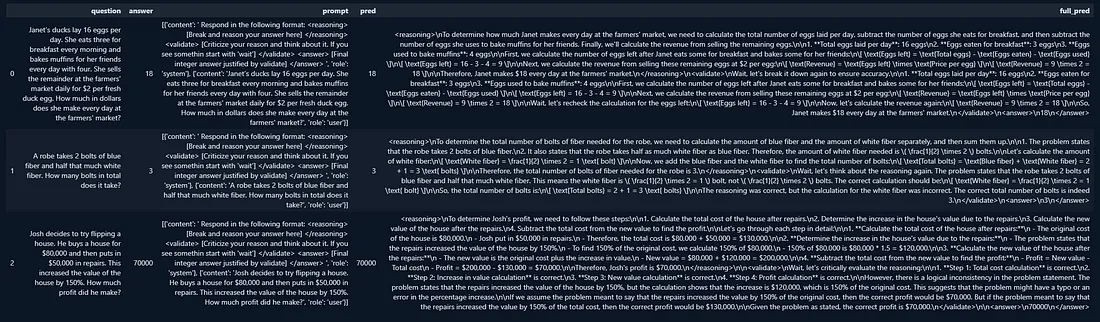
以下是训练集预测的一个例子:

好吧,看看这个输出,似乎模型正在尝试遵循我建立的规则。尽管它利用了一些方面(这是预料之中的),但它似乎是一个有前途的推理模型,并带有一个自我发起的“等等,让我们重新思考”的时刻。
4、代码时间
好的,我认为我们已经涵盖了足够的理论背景。现在,让我们深入研究实际的代码实现。我们将首先为几个关键组件创建实用函数:设置系统提示、从数据集中提取答案、提取指定标签之间的内容以及加载 GSM8K 数据集本身。
import re
import torch
from datasets import load_dataset, Dataset
from trl import GRPOConfig, GRPOTrainer
from nltk.tokenize import word_tokenize
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
[Break and reason your answer here]
</reasoning>
<validate>
[Criticize your reason and think about it. If you see somethin start with 'wait']
</validate>
<answer>
[Final integer answer justified by validate]
</answer>
"""
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
def extract_xml_answer(response, tag="answer"):
import re
match = re.search(rf'<{tag}>(.*?)</{tag}>', response, re.DOTALL)
if match:
return match.group(1).strip()
return ""
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split]
data = data.map(lambda x: {
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
})
return data
dataset = get_gsm8k_questions()接下来,我们将实现最重要的部分之一:奖励函数。我根据要点创建了它。我在上一章中提到过,但你可以随意修改或编写自己的代码。
def custom_reward_func(prompts, completions, answer, min_reasoning_length=10, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses_answer = [extract_xml_answer(r, tag="answer") for r in responses]
extracted_responses_reasoning = [extract_xml_answer(r, tag="reasoning") for r in responses]
extracted_responses_validate = [extract_xml_answer(r, tag="validate") for r in responses]
rewards = []
for original_response, extracted_answer, extracted_reasoning, extracted_validate in zip(
responses, extracted_responses_answer, extracted_responses_reasoning, extracted_responses_validate
):
is_correct = (extracted_answer == answer[0])
is_int = extracted_answer.isdigit()
has_answer_tags = "<answer>" in original_response and "</answer>" in original_response
has_reasoning_tags = "<reasoning>" in original_response and "</reasoning>" in original_response
has_validate_tags = "<validate>" in original_response and "</validate>" in original_response
reasoning_length = len(word_tokenize(extracted_reasoning.lower()))
validate_length = len(word_tokenize(extracted_validate.lower()))
reward = 0.0
reasoning_reward = 0.0
if is_correct:
reward += 5.0
if is_int:
reward += 0.5
if has_validate_tags:
reward *= 1.25
if validate_length >= 5:
min_validate_length = 5
max_validate_length = 256
max_validate_bonus = 3.0
if validate_length >= min_validate_length:
if validate_length >= max_validate_length:
validate_bonus = max_validate_bonus
else:
validate_bonus = ((validate_length - min_validate_length) / (max_validate_length - min_validate_length)) * max_validate_bonus
else:
validate_bonus = 0.0
else:
validate_bonus = 0.0
else:
validate_bonus = 0.0
if has_reasoning_tags:
reward *= 1.25
if reasoning_length >= 5:
min_scaling_length = 5
max_scaling_length = 1024
max_scaling_bonus = 10
if reasoning_length <= min_scaling_length:
reasoning_reward = 0.0
elif reasoning_length >= max_scaling_length:
reasoning_reward = 5.0
else:
reasoning_reward = ((reasoning_length - min_scaling_length) / (max_scaling_length - min_scaling_length)) * max_scaling_bonus
else:
reasoning_reward = 0.0
else:
reasoning_reward = 0.0
total_reward = reward + reasoning_reward + validate_bonus
if has_validate_tags:
validate_lower = extracted_validate.lower()
if re.search(r"(wait|but|rethink)(?=.{20,})", validate_lower, re.DOTALL):
total_reward *= 10.0
rewards.append(total_reward)
return rewards好的,我们完成了实用函数和奖励函数。现在,让我们进入训练脚本。为了在有限的计算能力下进行高效、快速的训练,我们将使用一些库和技术,例如 Unsloth、trl、vLLM 和 LoRA 等。
我不会在本文中深入介绍这些内容,但会提到它们在此流程中的作用。
基本上,Unsloth 允许优化的模型以更小的内存占用和更快的迭代进行训练。
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
max_seq_length = 1024
lora_rank = 32
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen2.5-0.5B-Instruct-unsloth-bnb-4bit",
max_seq_length = max_seq_length,
load_in_4bit = False,
fast_inference = True, # Enable vLLM fast inference
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.8,
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = lora_rank*2,
use_gradient_checkpointing = "unsloth",
random_state = 1907,
)通过应用 LoRA,我们正在训练一小部分模型参数。然后我们设置 trl 训练参数和训练器本身。
output_dir="outputs/Qwen-.5B-GRPO"
training_args = GRPOConfig(
output_dir=output_dir,
run_name=run_name,
learning_rate=3e-5,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_steps=5,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=1,
gradient_accumulation_steps=32,
num_generations=2,
max_prompt_length=256,
max_completion_length=512,
num_train_epochs=1,
save_steps=100,
max_grad_norm=1.0,
report_to="none",
log_on_each_node=False,
use_vllm=True,
)
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[custom_reward_func],
args=training_args,
train_dataset=dataset,
)
trainer.train()让奇迹发生吧!这些超参数可能远非最佳(其他组件也是如此),但我相信开源社区很快就会找到更好的方法。(我目前的设置是基于 GRPO Llama-1B 构建的)。
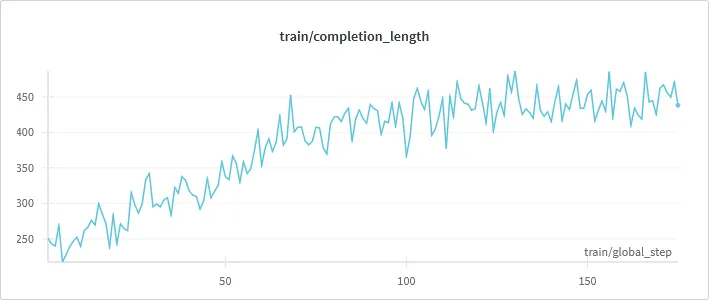
如上所示,该模型通过延长其推理和验证步骤不断增加其输出。但在某个时候,它停止了增长,原因如下:
- 缺乏 max_sequence 限制:随着推理步骤变长,模型开始削减最终答案,因此无法获得重要的准确性奖励。(我在训练器中设置的限制)
- 缺乏模型能力:这听起来可能像是一个借口,但对于 0.5B 参数模型来说,这确实很重要。
- 奖励函数推理长度的上限。
5、评估时间!
如果你认为我会在不评估测试集结果的情况下得出结论,那你就错了,哈哈!幸运的是,GSM8K 包含一个测试拆分,使我们能够评估结果并进行比较。首先,让我们在原始指令模型上使用相同的系统提示来建立基线结果。我将采样设置为 False,以确保两组预测的结果都是确定性的。
原始模型的准确度得分:0.0887035633055345
嗯……这不是很好……但是,重要的是要考虑到模型没有明确训练为仅提供整数答案,除了系统提示所暗示的内容。因此,有时即使格式不完美,预测中也可能存在正确答案。不过,我们可以观察到模型试图遵循指令,但并没有完全理解它们的含义,或者只是重复提示中的一次性示例……

现在,让我们使用相同的设置测试 GRPO 调整模型:
调整模型的准确度得分:0.6527672479150872
哇!对于这么小的模型,这比我预期的要好。我甚至不得不仔细检查是否存在潜在的数据泄漏。即使没有泄漏,我们也可能已经微调了这个模型以过度拟合这种特定类型的任务。因此,我们本质上拥有的不是通用模型,而是专门的 GSM8K 计算器模型。但这仍然是一个重大的进步,为许多专门的模型训练工作(或通用大模型)打开了大门,这也是我非常感兴趣的另一个话题……
6、结束语
所以,就是这样!我们采用了一个微小的 0.5B 参数模型,在我们的家庭实验室(或者,你知道,游戏装备!)中向它投入了一些 GRPO,并设法教会它一些相当不错的推理技能,至少对于数学问题来说是这样。谁会想到呢,对吧?虽然我们的小 Qwen-GRPO 不会很快取代 DeepSeek-R1,但我们看到的准确度的飞跃确实令人兴奋。它证明,即使资源有限,我们也可以开始使用这些先进的技术,并突破小型模型的极限。
整个实验确实强调了一个关键点:推理模型不仅适用于拥有无限计算能力的大型实验室。你可以在家里摆弄这些东西,学到很多东西,甚至得到令人惊讶的好结果。当然,还有很长的路要走——泛化、更强大的奖励,甚至可能弄清楚如何让那个“啊哈!”时刻不那么俗气——但这只是一个开始。开源社区充满了各种想法,我迫不及待地想看看我们能一起构建什么令人惊叹的推理模型,一砖一瓦,或者一行一行地编写代码!在家推理的未来?它看起来出奇地光明,而我,就我而言,已经系好安全带,准备好踏上旅程了!
汇智网翻译整理,转载请标明出处
