Ultravox实时语音多模态大模型
Ultravox 是一种新型多模态 LLM,可以理解文本和人类语音,而无需单独的音频语音识别 (ASR) 阶段。

Ultravox 是一种新型多模态 LLM,可以理解文本和人类语音,而无需单独的音频语音识别 (ASR) 阶段。
可以从Huggingface下载模型,源代码请访问Github。
1、模型简介
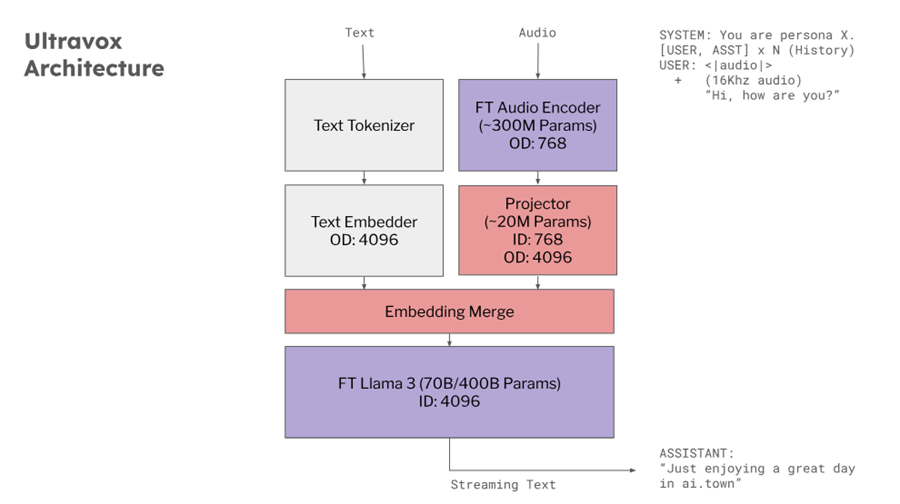
基于 AudioLM、SeamlessM4T、Gazelle、SpeechGPT 等研究,Ultravox 能够使用多模态投影单元扩展任何开放权重 LLM,该投影单元将音频直接转换为 LLM 使用的高维空间。团队已经在 Llama 3、Mistral 和 Gemma 上训练了版本。这种直接耦合使 Ultravox 的响应速度比结合单独的 ASR 和 LLM 组件的系统快得多。在未来,这还将使 Ultravox 能够原生地理解人类语音中无处不在的时间和情感的副语言线索。
当前版本的 Ultravox (v0.4) 在调用音频内容时,第一个标记的时间 (TTFT) 约为 150 毫秒,使用 Llama 3.1 8B 主干的每秒标记速率约为 60。虽然速度很快,但团队认为这些数字还有很大的改进空间。
Ultravox 目前接收音频并发出流式文本。随着模型的发展,团队计划训练它能够发出语音标记流,然后可以通过适当的单元声码器将其直接转换为原始音频。
可以在官方演示页面上查看 Ultravox 的实际操作。
2、模型架构
3、使用方法
将该模型视为一个可以听到和理解语音的 LLM。因此,它可以用作语音代理,也可以进行语音到语音的翻译、口语音频分析等。
要使用该模型,请尝试以下操作:
# pip install transformers peft librosa
import transformers
import numpy as np
import librosa
pipe = transformers.pipeline(model='fixie-ai/ultravox-v0_4', trust_remote_code=True)
path = "<path-to-input-audio>" # TODO: pass the audio here
audio, sr = librosa.load(path, sr=16000)
turns = [
{
"role": "system",
"content": "You are a friendly and helpful character. You love to answer questions for people."
},
]
pipe({'audio': audio, 'turns': turns, 'sampling_rate': sr}, max_new_tokens=30)
4、性能评估
当前版本的 Ultravox 在调用音频内容时,第一个令牌时间 (TTFT) 约为 150 毫秒,使用 A100-40GB GPU 时令牌每秒速率约为 50-100,全部使用 Llama 3.1 8B 主干。
你可以查看 TheFastest.ai 上的音频选项卡,了解每日基准测试以及与其他现有模型的比较。
评估结果表:
| en_de (BLEU) | es_en (BLEU) | LibriSpeech clean.test (WER) | |
|---|---|---|---|
| Ultravox v0.3 | 22.66 | 24.74 | 6.67 |
| Ultravox v0.4 | 25.47 | 37.11 | 4.45 |
| Llama3.1(仅文本) | 31.95 | 38.28 | - |
原文链接:Ultravox - A fast multimodal LLM for real-time voice
汇智网翻译整理, 转载请标明出处
