VerifAI开源生成式搜索引擎
最初,VerifAI 是作为具有参考和 AI 验证答案的生物医学生成搜索而开发的,现在可以索引本地文件并将其转换为自己的生成式搜索引擎。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我之前写过关于构建自己的简单生成搜索的文章,以及关于 VerifAI 项目的文章。但是,有一个值得重新回顾的重大更新。最初,VerifAI 是作为具有参考和 AI 验证答案的生物医学生成搜索而开发的。此版本仍然可用,我们现在将其称为 VerifAI BioMed。可以在此处访问。
但是,主要更新是,你现在可以索引本地文件并将其转换为自己的生成式搜索引擎或生产力引擎,因为有些人称这些系统基于 GenAI。它也可以用作企业或组织生成搜索。我们将此版本称为 VerifAI Core,因为它是其他版本的基础。在本文中,我们将探讨如何通过几个简单的步骤部署它并开始使用它。鉴于它是用 Python 编写的,它可以在任何类型的操作系统上运行。
1、系统架构
描述生成式搜索引擎的最佳方式是将其分解为三个部分,或在我们的例子中为组件:
- 索引
- 检索增强生成 (RAG) 方法
- VerifAI 在通常的生成搜索功能之上还包含一个附加组件,即验证引擎
VerifAI 中的索引可以通过将其索引器脚本指向包含 PDF、MS Word、PowerPoint、文本或 Markdown ( .md) 等文件的本地文件夹来完成。脚本读取并索引这些文件。索引以双重模式执行,同时利用词汇和语义索引。
对于词汇索引,VerifAI 使用 OpenSearch。对于语义索引,它使用配置文件中指定的嵌入模型(支持来自 Hugging Face 的模型)对文档块进行矢量化,然后将这些向量存储在 Qdrant 中。下图显示了此过程的直观表示:

在使用 VerifAI 回答问题时,该方法有些复杂。用自然语言编写的用户问题经过预处理(例如,排除停用词),然后转换为查询。
对于 OpenSearch,只执行词汇处理(例如,排除停用词),并检索最相关的文档。对于 Qdrant,查询使用与在 Qdrant 中存储文档块时用于嵌入文档块的相同模型转换为嵌入。然后使用这些嵌入来查询 Qdrant,根据点积相似性检索最相似的文档。使用点积是因为它同时考虑了向量的角度和幅度。
最后,必须合并两个引擎的结果。这是通过将每个引擎的检索分数标准化为 0 到 1 之间的值(通过将每个分数除以其各自引擎的最高分数来实现的)来实现的。然后将与同一篇文档对应的分数相加,并按总分数降序排列。
使用检索到的文档,构建提示。提示包含说明、排名靠前的文档和用户的问题。然后,将此提示传递给所选的大型语言模型(可以在配置文件中指定,或者,如果未设置模型,则默认为我们本地部署的经过微调的 Mistral 版本)。最后,应用验证模型以确保没有幻觉,并通过 GUI 将答案呈现给用户。下图显示了此过程的示意图:

2、安装VerifAI生成式搜索
要安装 VerifAI Generative Search,你可以先从 GitHub 克隆最新的代码库,或使用其中一个可用版本:
git clone https://github.com/nikolamilosevic86/verifAI.git安装 VerifAI Search 时,建议先创建一个干净的 Python 环境。我已经使用 Python 3.6 对其进行了测试,但它应该适用于大多数 Python 3 版本。但是,Python 3.10+ 可能会遇到与某些依赖项的兼容性问题。
要创建 Python 环境,你可以使用 venv 库,如下所示:
python -m venv verifai
source verifai/bin/activate激活环境后,你可以安装所需的库。需求文件位于 verifAI/backend 目录中。你可以运行以下命令来安装所有依赖项:
pip install -r requirements.txt3、配置系统
下一步是配置 VerifAI 及其与其他工具的交互。这可以通过直接设置环境变量或使用环境文件(首选选项)来完成。
后端文件夹中提供了一个 VerifAI 的环境文件示例,名为 .env.local.example。你可以将此文件重命名为 .env,然后 VerifAI 后端将自动读取。文件结构如下:
SECRET_KEY=6293db7b3f4f67439ad61d1b798242b035ee36c4113bf870
ALGORITHM=HS256
DBNAME=verifai_database
USER_DB=myuser
PASSWORD_DB=mypassword
HOST_DB=localhost
OPENSEARCH_IP=localhost
OPENSEARCH_USER=admin
OPENSEARCH_PASSWORD=admin
OPENSEARCH_PORT=9200
OPENSEARCH_USE_SSL=False
QDRANT_IP=localhost
QDRANT_PORT=6333
QDRANT_API=8da7625d78141e19a9bf3d878f4cb333fedb56eed9097904b46ce4c33e1ce085
QDRANT_USE_SSL=False
OPENAI_PATH=<model-deployment-path>
OPENAI_KEY=<model-deployment-key>
OPENAI_DEPLOYMENT_NAME=<name-of-model-deployment>
MAX_CONTEXT_LENGTH=128000
USE_VERIFICATION = True
EMBEDDING_MODEL="sentence-transformers/msmarco-bert-base-dot-v5"
INDEX_NAME_LEXICAL = 'myindex-lexical'
INDEX_NAME_SEMANTIC = "myindex-semantic"一些变量非常简单。第一个密钥和算法用于前端和后端之间的通信。
然后是配置对 PostgreSQL 数据库的访问的变量。它需要数据库名称 (DBNAME)、用户名、密码和数据库所在的主机地址。在我们的例子中,它位于 localhost 上,在 docker 镜像上。
下一部分是 OpenSearch 访问的配置。有 IP(在我们的例子中再次是 localhost)、用户名、密码、端口号(默认端口为 9200)和定义是否使用 SSL 的变量。
类似的配置部分有 Qdrant,仅对于 Qdrant,我们使用 API 密钥,必须在此处定义。
下一部分定义了生成模型。 VerifAI 使用已成为行业标准的 OpenAI Python 库,并允许它通过 vLLM、OLlama 或 Nvidia NIM 使用 OpenAI API、Azure API 和用户部署。用户需要定义将要使用的接口路径、API 密钥和模型部署名称。我们很快将添加支持,用户可以修改或更改用于生成的提示。如果没有提供接口路径和密钥,模型将下载 Mistral 7B 模型,使用我们已微调的 QLoRA 适配器,并将其部署到本地。但是,如果你没有足够的 GPU RAM 或一般 RAM,这可能会失败,或者运行速度非常慢。
你还可以设置 MAX_CONTEXT_LENGTH,在本例中它设置为 128,000 个令牌,因为这是 GPT4o 的上下文大小。上下文长度变量用于构建上下文。通常,它是通过输入有关按事实回答问题的说明(带有参考)然后提供检索到的相关文档和问题来构建的。但是,文档可能很大,并且超出上下文长度。如果发生这种情况,文档将被拆分成块,并且适合上下文大小的前 n 个块将用于上下文。
下一部分包含用于在 Qdrant 中嵌入文档的模型的 HuggingFace 名称。最后,OpenSearch( INDEX_NAME_LEXICAL)和 Qdrant( INDEX_NAME_SEMANTIC)中都有索引名称。
正如我们之前所说,VerifAI 有一个组件,用于验证生成的声明是否基于提供和引用的文档。但是,可以打开或关闭此功能,因为对于某些用例,不需要此功能。可以通过将 USE_VERIFICATION 设置为 False 来关闭它。
4、安装数据存储区
安装的最后一步是运行 install_datastores.py 文件。在运行此文件之前,你需要安装 Docker 并确保 Docker 守护程序正在运行。由于此文件读取配置以设置其正在安装的工具的用户名、密码或 API 密钥,因此需要先创建配置文件。这将在下一节中解释。
此脚本设置必要的组件,包括 OpenSearch、Qdrant 和 PostgreSQL,并在 PostgreSQL 中创建数据库:
python install_datastores.py请注意,此脚本安装 Qdrant 和 OpenSearch 时没有 SSL 证书,并且以下说明假定不需要 SSL。如果你需要 SSL 用于生产环境,则需要手动配置它。
另请注意,我们在这里讨论的是 docker 上的本地安装。如果你已经部署了 Qdrant 和 OpenSearch,只需更新配置文件以指向这些实例即可。
5、索引文件
此配置由索引方法和后端服务使用。因此,必须在索引之前完成。配置设置完成后,你可以通过将 index_files.py 指向包含要索引的文件的文件夹来运行索引过程:
python index_files.py <path-to-directory-with-files>我们在存储库中包含了一个名为 test_data 的文件夹,其中包含几个测试文件(主要是我的论文和其他过去的著作)。您可以用自己的文件替换这些文件并运行以下命令:
python index_files.py test_data这将对该文件夹及其子文件夹中的所有文件运行索引。完成后,可以运行 VerifAI 服务用于后端和前端。
6、运行生成式搜索
VerifAI 的后端只需运行以下命令即可运行:
python main.py这将启动作为后端的 FastAPI 服务,并将请求传递给 OpenSearch 和 Qdrant 以检索给定查询的相关文件,并传递给 LLM 部署以生成答案,以及利用本地模型进行索赔验证。
前端是一个名为 client-gui/verifai-ui 的文件夹,用 React.js 编写,因此需要本地安装 Node.js 和 npm。然后,你只需运行 npm install 即可安装依赖项,并通过运行 npm start 来运行前端:
cd ..
cd client-gui/verifai-ui
npm install
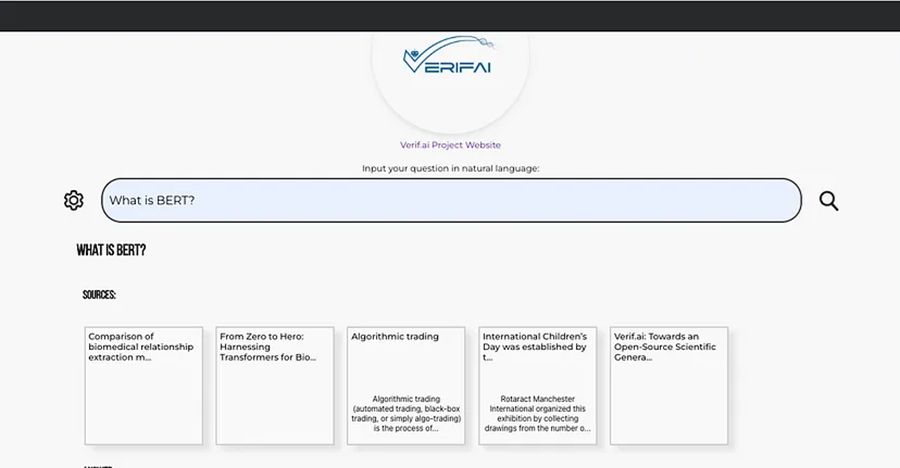
npm start最后,应该看起来像这样:


7、贡献和未来方向
到目前为止,VerifAI 已在下一代互联网搜索项目的资助下启动,作为欧盟的一项子赠款。它是由塞尔维亚人工智能研究与发展研究所和拜耳公司合作发起的。第一个版本已被开发为生物医学的生成搜索引擎。该产品将继续在官网运行。
然而,最近,我们决定扩展该项目,以便它真正成为一个开源生成搜索,为任何文件提供可验证的答案,可供不同的企业、中小型公司、非政府组织或政府公开利用。这些修改是由 Natasa Radmilovic 和我自愿开发的,向 Natasa 致以崇高的敬意!
原文链接:How to Easily Deploy a Local Generative Search Engine Using VerifAI
汇智网翻译整理,转载请标明出处
