视频转录文本应用开发
本文展示如何使用 Web 应用将语音识别AI模型的能力应用到现实世界的视频文本转录问题上。
这是一个周末项目,展示了如何将 Web 开发与生成式 AI 工具结合起来。
生成式 AI 是数据科学和计算机科学中最热门的领域之一。然而,它也是最难跟上的领域之一。每周都会出现大量研究论文,其中包含新概念、新技术、新模型,可用的工具数量,甚至该领域的参与者数量,所有这些都让任何试图掌握它的人感到不知所措和害怕。所有这些都让人很难知道从哪里开始以及如何开始。
我相信,这和任何复杂的任务一样,最好一点一点地解决。在这篇文章中,我介绍了一个小而简单的项目,它可以你展示如何使用 Web 应用程序将最成功的生成式 AI 领域之一语音到文本转录应用到现实世界的问题中。
1、视频转录
要将视频中的语音转录为文本,我们将使用 OpenAI whisper 模型。该生成模型由 OpenAI 于 2022 年开发。它可以转录多种语言的语音(见图)。
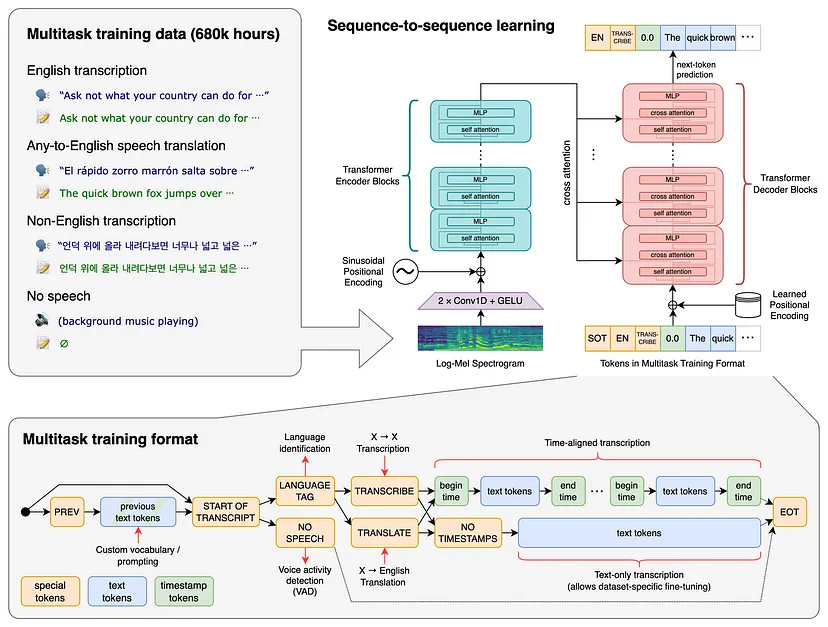
Whisper 需要 wav 或 mp3 格式的声音文件作为输入,并返回一个包含输入文件中转录文本的字符串。在这个 Web 应用程序中,whisper 将是一项服务,它将输入的音频转换为对应的文本。
2、系统实现
由于我们从视频文件开始,因此首先我们需要从视频中提取音频。我们还需要一个与用户交互的界面。为此,我们将构建一个 Web 应用程序,该应用程序将支持页面来接收视频文件并显示文本。
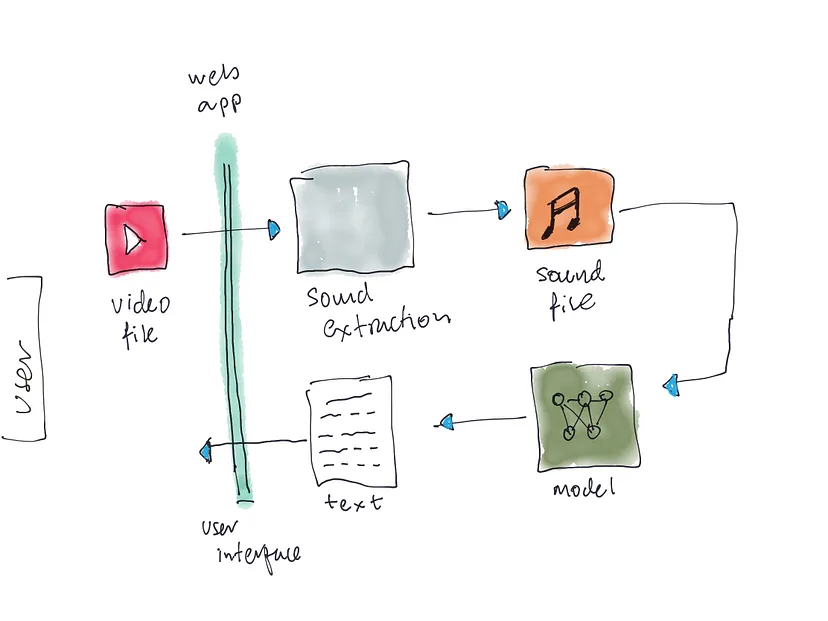
在上面的架构图中,网页(前端)用作用户提供视频文件的界面。系统(后端)应该能够处理用户提供的视频。声音提取模块负责从提供的视频中提取音频。完成后,语音转文本转录模型将生成用户界面向最终用户显示的文本。
图 1 中的模块显示了系统的组织方式,用户上传视频文件,系统将其保存在本地,从视频中提取声音,然后由AI模型将其转录为文本。最后,转录的文本通过网页显示给用户查看。
2.1 技术栈
这些是用于实现上述模块的工具/栈:
- 前端(HTML/CSS/JavaScript):创建用户界面。
- 后端(Node.js/Express):处理文件上传(视频)和编排,以协调从视频中提取声音并处理输出(文本)。
- 语音转文本服务:OpenAI whisper 模型。
2.1 Web 服务器
后端是 node.js。这由一个简单的 server.js 处理:
const express = require('express');
const multer = require('multer');
const { exec } = require('child_process');
const fs = require('fs');
const path = require('path');
const app = express();
const upload = multer({ dest: 'uploads/' });
app.use(express.static('public'));
app.post('/upload', upload.single('video'), (req, res) => {
const videoPath = req.file.path;
const command = `npm run transcribe -- ${videoPath}`;
exec(command, (error, stdout, stderr) => {
if (error) {
console.error(`Error: ${error.message}`);
return res.status(500).send('An error occurred while processing the video.');
}
if (stderr) {
console.error(`Stderr: ${stderr}`);
return res.status(500).send('An error occurred while processing the video.');
}
const transcription = stdout;
res.json({ transcription });
});
});
app.listen(3000, () => {
console.log('Server started on http://localhost:3000');
});2.3 音频提取和转录模块
语音转文本转录由 OpenAI whisper 模型执行。但是,需要先从视频中提取音频,然后才能通过 whisper 进行处理。
import whisper
import sys
from moviepy.editor import VideoFileClip
def extract_audio_from_video(video_path, audio_output_path):
"""
Extract audio from a video file and save it to a new file.
Args:
video_path: str, path to the video file
audio_output_path: str, path to save the audio file
Returns:
None
"""
print(f"Extracting audio from {video_path}...")
try:
# Load the video file
video_clip = VideoFileClip(video_path)
# Extract the audio
audio_clip = video_clip.audio
# Write the audio to a file
audio_clip.write_audiofile(audio_output_path)
print(f"Audio extracted and saved to {audio_output_path}")
except Exception as e:
print(f"An error occurred: {e}")
def transcribe(file_path):
model = whisper.load_model("base")
print("Transcribing...")
# print(model)
result = model.transcribe(file_path)
return result["text"]
# run the code with arguments
if __name__ == "__main__":
file_path = sys.argv[1]
#file_path = "sample.mp3"
print(transcribe(file_path))2.4 将所有内容整合在一起
完成安装运行 node 和 whisper 所需的步骤后,可以使用 npm start或 node server.js 运行该应用程序。
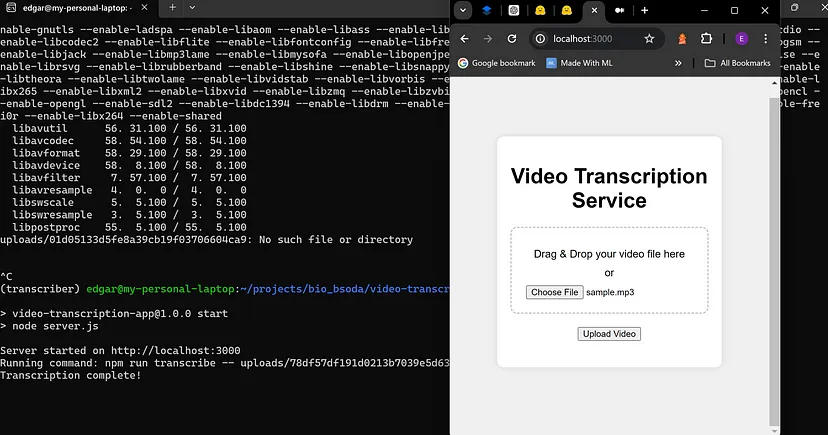
上图显示了上面显示的 npm start 命令和正在运行的 node server.js 文件。网页显示了上传视频文件的说明和上传按钮,该按钮调用将文件保存到磁盘并运行音频提取的函数。
就这样,转录 Web 应用程序就可以启动并运行了。上传视频文件(例如 mp4)并等待一段时间后,你应该会在网页上看到转录的文本。你需要等待的时间可能因要转录的视频的大小和运行它的计算机而异。如果你有 GPU,它的运行速度可能会比在 CPU 上运行快得多。
3、结束语
总之,这篇文章解释了如何实现一个通过网页将视频转录为文本的 Web 应用程序。转录部分由语音转文本的生成式人工智能模型(由 OpenAI 开发)完成。这个简单但具有教育意义的项目可以作为你开发 Web 应用程序的切入点,帮助人们使用生成式AI解决实际问题。
这里介绍的工作可以通过不同的方式进行扩展。如果你想在以下某个领域扩展项目,它们按难度顺序列出:
- 输出格式。使用此实现,输出将直接写在文件上传的同一窗格上。一个好的扩展是将转录放在带有复制和保存到文件按钮的可滚动文本框中。最后,在系统中存储转录和视频的功能可以是一个非常有用的扩展。
- 身份验证。例如,此 Web 应用程序可以包含身份验证过程,以便只有注册用户才能使用此服务。你需要为此使用数据库。
- 部署。这项工作的一个非常有用的扩展可以是部署细节,以便在云环境中提供服务。你可以在主要的云提供商之一 AWS、Azure、GCP 等中获取一个帐户。或者你可以学习如何使用更专业的工具(如 vercel)为你的网站提供服务。无论哪种方式,这都是学习如何扩展现实世界的 Web 应用程序的绝佳方式。
可以在这个 github repo 中访问全部源代码。
原文链接:How to build a video transcription web app using generative AI
汇智网翻译整理,转载请标明出处