VPTQ低位LLM量化算法
在 MMLU 等任务上,使用 VPTQ 的 2 位量化几乎实现了与原始 16 位模型相当的性能。此外,它能够在单个 GPU 上运行 Llama 3.1 405B,同时使用的内存比 70B 模型少!

LLM 低位量化的最新发展,例如 AQLM 和 AutoRound,现在在下游任务中显示出可接受的退化水平,尤其是对于大型模型。 话虽如此,2 位量化在大多数情况下仍会导致明显的准确性损失。
一种很有前途的低位量化算法是微软提出的 VPTQ(MIT 许可证)。它于 2024 年 10 月推出,此后在量化大型模型方面表现出色,效率极高。
在本文中,我们将:
- 回顾 VPTQ 量化算法
- 演示如何使用 VPTQ 模型,其中许多模型已经可用。例如,我们可以轻松找到 Llama 3.3 70B、Llama 3.1 405B 和 Qwen2.5 72B 的低位变体
- 评估这些模型并讨论结果,以了解 VPTQ 模型何时可以成为生产中 LLM 的良好选择。
值得注意的是,在 MMLU 等任务上,使用 VPTQ 的 2 位量化几乎实现了与原始 16 位模型相当的性能。此外,它能够在单个 GPU 上运行 Llama 3.1 405B,同时使用的内存比 70B 模型少!
本文解释了运行 VPTQ 模型和评估的所有步骤,并在此笔记本中实现。
1、向量训练后量化
这篇论文介绍了 VPTQ:VPTQ:用于大型语言模型的极低位向量训练后量化 。它利用向量量化 (VQ),这是一种将权重组表示为向量而不是单个标量的技术。
核心思想是将 LLM 的权重矩阵重塑为较小的向量。然后将每个向量映射到预定义码本中的最近质心。注意:码本是一组可学习的候选向量,可用于对数据进行编码。
此映射最小化了质心和向量之间的欧几里得距离,用指向质心的索引替换向量。这种转换允许显着压缩,同时保持准确性。
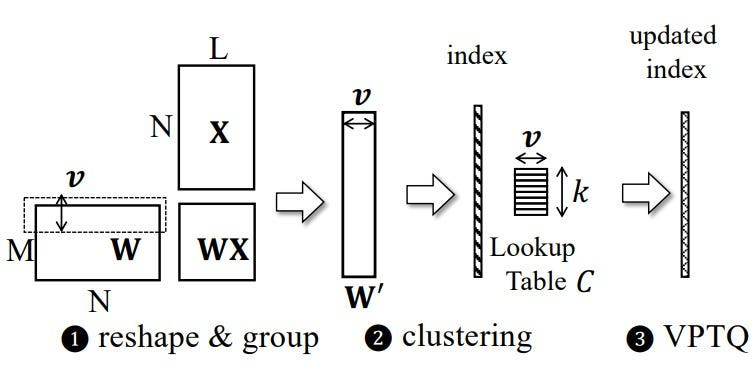
量化过程由二阶优化框架指导。在误差对模型性能的影响尽可能小的约束下,最小化量化误差。Hessian 矩阵表示损失对权重变化的二阶灵敏度。这与 GPTQ 的作用类似。
在 VPTQ 的超参数中,我们有:
- 向量长度 (v)
- 质心数量 (k)
v 和 k 控制准确度和压缩率之间的权衡。例如,较长的向量会减少所需的质心数量,从而提高内存效率,但可能会增加反量化期间的计算成本。码本的大小由 k 决定,其中较大的 k 可以更好地表示权重分布,但会消耗更多内存来存储质心。
残差矢量量化 (RVQ) 进一步完善了该过程。这种多阶段改进使用辅助码本来最小化残差误差,从而以最小的位开销实现高精度。另一种改进解决了异常值问题,这些异常值是罕见但不成比例的大权重,可能会扭曲量化精度。使用专用码本单独处理异常值,以最大限度地减少它们对整体误差的影响。
质心的初始化至关重要,使用 Hessian 加权 K 均值聚类完成。考虑到 Hessian 对角线指示的权重的相对重要性,这种方法可确保质心与权重分布很好地对齐。与简单聚类相比,这种加权初始化可显著减少量化误差。
在推理过程中,模型通过基于索引从码本中查找质心来重建权重,如果使用 RVQ,则结合残差校正。这使得推理过程变得轻量级,因为它只涉及简单的查找和添加。
2、估计 VPTQ 模型的平均位宽
Microsoft 提出了一种估计使用 VPTQ 量化的模型的位宽(即量化精度)的方法。以下是他们的做法。
微软发布的 VPTQ 模型使用的模型命名约定包括有关向量长度 (v)、码本大小 (k) 和残差码本大小的详细信息。例如,名称“Meta-Llama-3.1–70B-Instruct-v8-k65536–256-woft”对应于具有以下参数的模型“Meta-Llama-3.1–70B-Instruct”:
- 向量长度:v=8
- 质心数:k=65536
- 残差质心数:k(res)=256
模型的等效位宽可以按以下方式计算:
- 索引位宽:每个向量由质心索引表示。对于 k=65536,我们有索引位宽:log2(65536) = 16 位。除以向量长度 (v=8) 可得出:16/8= 每个权重 2 位。
- 残差索引位宽:对于残差质心,k(res) = 256,索引位宽为:log2(256) = 8 位。除以向量长度 (v=8) 可得出:8/8=每个权重 1 位。
- 总位宽:组合位宽为:2+1=每个权重 3 位。
要估计模型大小,请将参数总数乘以位宽并将其转换为字节。
注意:此估计相当准确,但不包括码本(查找表)的大小、额外的参数开销和用于存储索引的填充开销。
3、运行 VPTQ 模型
VPTQ 集成到 Hugging Face Transformers 中。要运行模型,你需要安装以下内容:
pip install --upgrade transformers vptqTransformers 会自动检测该模型是 VPTQ 模型。我们无需执行任何特殊操作即可运行模型。就这么简单:
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load VPTQ-quantized model directly from HuggingFace Hub
model = AutoModelForCausalLM.from_pretrained("VPTQ-community/Meta-Llama-3.1-8B-Instruct-v8-k65536-256-woft", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("VPTQ-community/Meta-Llama-3.1-8B-Instruct-v8-k65536-256-woft")
# Simple inference
prompt = "Explain: Do not go gentle into that good night."
output = model.generate(**tokenizer(prompt, return_tensors="pt").to(model.device))
print(tokenizer.decode(output[0], skip_special_tokens=True))Hugging Face 上的VPTQ-community发布了许多模型。在下一节中,我们将评估以下模型一:
- VPTQ-community/Qwen2.5–72B-Instruct-v16-k65536–65536-woft
- VPTQ-community/Qwen2.5–72B-Instruct-v8-k65536–0-woft
- VPTQ-community/Qwen2.5–72B-Instruct-v16-k65536–32768-woft
- VPTQ-community/Meta-Llama-3.3–70B-Instruct-v8-k65536–0-woft
- VPTQ-community/Meta-Llama-3.3–70B-Instruct-v16-k65536–1024-woft
- VPTQ-community/ Meta-Llama-3.1–405B-Instruct-v16-k65536–65536-woft
- VPTQ-community/Meta-Llama-3.1–405B-Instruct-v16-k32768–32768-woft
- VPTQ-community/Meta-Llama-3.1–405B-Instruct-v16-k65536–1024-woft
- VPTQ-community/Meta-Llama-3.1–405B-Instruct-v16-k65536–256-woft
- VPTQ-community/Meta-Llama-3.1–405B-Instruct-v16-k65536–64-woft
注意:这些 Qwen 和 Llama 模型分别使用 llama 和 qwen 许可证发布。
所有这些 Llama 3.3 和 Qwen2.5 模型都可以在单个 24 GB GPU 上运行!Llama 3.1 405B 模型虽然比原始模型小得多,但仍然需要大量 GPU 内存,但我可以使用 RunPod 提供的 H200 SXM(推荐链接)运行所有模型,因此它们可以在单个 GPU 上运行。
我还没有测试过,但应该也可以使用 QLoRA 方法在 VPTQ 模型之上微调 LoRA 适配器。最糟糕的是,在 Hugging Face PEFT 库中添加 VPTQ 支持的代码只有几行。
4、评估 VPTQ 模型
为了评估量化算法的好坏,我通常依赖 MMLU。我计算量化模型的准确性并将其与原始模型的准确性进行比较。如果两种精度接近,则量化效果良好。
但请注意,这远远不足以评估量化模型。量化模型可能对某些任务准确,但对其他任务完全无效。例如,使用 AutoRound 量化,我看到 2 位模型在 MMLU 上表现非常好,但生成乱码。这就是为什么我建议也在某些生成任务(如 IFEval 或 MATH)上评估模型,以确保模型没有损坏。
对于本文,我仅使用 MMLU 评估所有模型,并使用 MMLU-PRO、MuSR 和 GPQA 评估 Llama 3.3 和 Qwen2.5。我没有运行生成基准测试,并且仅在 MMLU 上评估了 Llama 3.1 405B,因为评估成本很高。我计划在 vLLM 中添加 VPTQ 支持时这样做。
我使用评估工具来运行此评估。
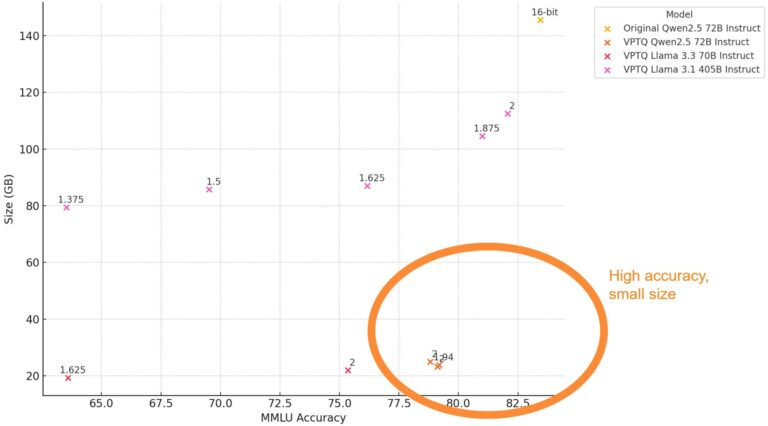
这些结果非常令人印象深刻。
作为参考,使用 AutoRound,在相同的评估设置下,我使用 2 位量化可以实现的最佳准确度为 73.71。这也是使用 Qwen2.5 72B Instruct 实现的。
2 位 Qwen2.5 模型的性能仅比原始模型低 5 分。我们非常接近让 2 位模型与原始 16 位模型一样好。
当我尝试使用 Llama 3.3 进行 AutoRound 2 位量化时,它完全失败了。使用 VPTQ,它运行良好,MMLU 准确度接近 75.0。
正如预期的那样,像 Llama 3.1 405B 这样的较大模型对低位量化更具鲁棒性。即使平均位宽为 1.5,该模型仍可实现接近
设置为 70.0,这仅略低于我评估 Qwen2.5 7B Instruct 时得到的结果。然而,在实践中,这个模型并不适用于任何事情,因为它仍然比其他表现更好的模型大得多。
此外,我运行了 MMLU-PRO、MuSR 和 GPQA 来评估 Llama 3.3 和 Qwen2.5:
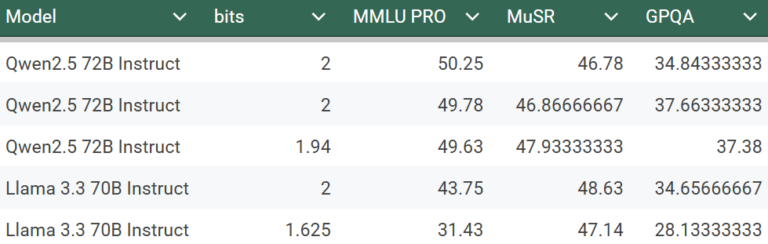
所有这些分数对于 2 位模型来说都非常出色。作为参考,根据 OpenLLM 排行榜,原始(16 位)Qwen2.5 72B Instruct 在 MMLU-PRO 上的性能为 51.4。这与 2 位 VPTQ 模型的性能相差不远。注意:OpenLLM 排行榜将 MMLU-PRO 作为 5 次任务运行,而我将其作为 0 次任务运行,这使 VPTQ 模型处于劣势。
5、结束语
对于低位量化,VPTQ 的准确性确实令人印象深刻。此外,与之前在低精度下可能完全破坏模型的算法不同,VPTQ 似乎更为稳健。最后,我们得到了一个不会产生乱码的 2 位 Llama 3.3 70B。
随着低位量化越来越好,量化较大的模型可能比使用较小的 16 位模型更可取。主要缺点是推理速度会比较小的模型慢,因为它们有更多的参数。
在本文中,我仅探讨了 VPTQ 作者正式发布的量化模型。使用 VPTQ 量化自己的模型有多容易?
该算法似乎与 AutoRound 一样昂贵。换句话说,应该可以在云端以不到 10 美元的价格量化 70B 模型。但是,量化算法尚未在 GitHub 存储库中完全发布。作者似乎想对其进行进一步完善。据我所知,它几乎完全在 VPTQ 的“算法”分支中可用。
计算 Hessian 矩阵的部分仍然缺失(截至 2025 年 1 月 25 日)。我们必须依靠预先计算的矩阵或使用第三方软件计算它们。
原文链接:2-Bit VPTQ: 6.5x Smaller LLMs While Preserving 95% Accuracy
汇智网翻译整理,转载请标明出处
