零样本网球选手跟踪
在这个项目中我们绕过了对标注数据的需求,依赖GroundingDINO的零样本跟踪能力并结合卡尔曼滤波器实现来克服噪声输出。
随着最近体育追踪项目的激增,许多项目受到Skalski流行的足球追踪项目的启发,越来越多的人开始使用自动球员跟踪来服务于运动爱好者。
大多数这些方法遵循一个熟悉的工作流程:收集标注数据,训练YOLO模型,将球员坐标投影到场地或球场的俯视图上,并使用这种跟踪数据生成高级分析以获取潜在的竞争洞察。
然而,在这个项目中,我们提供了工具来绕过对标注数据的需求,依赖GroundingDINO的零样本跟踪能力,结合卡尔曼滤波器实现来克服GroundingDino产生的噪声输出。
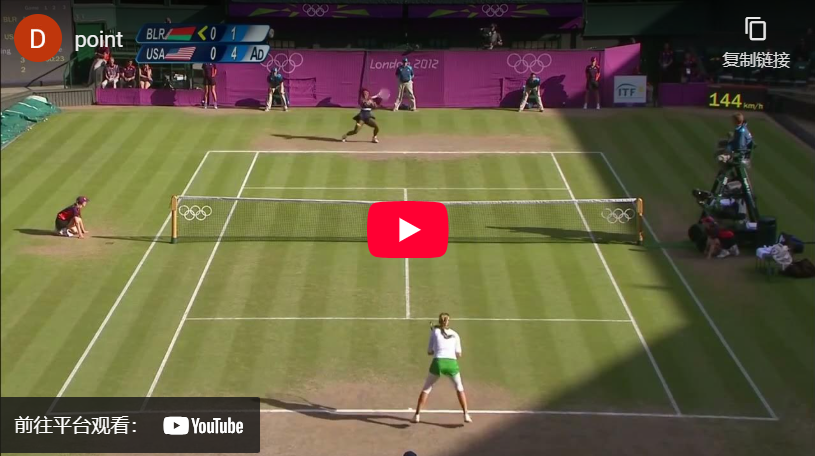
我们的数据集来源于一系列广播视频,根据Hayden Faulkner及其团队提供的MIT许可证公开可用。¹ 这些数据包括2012年温布尔登奥运会期间各种网球比赛的片段,我们重点关注塞雷娜·威廉姆斯与维多利亚·阿扎伦卡之间的比赛。
1、GroundingDINO简介
对于那些不熟悉的读者来说,GroundingDINO将对象检测与语言结合起来,允许用户输入提示,如“一名网球运动员”,然后模型会返回符合描述的候选对象检测框。RoboFlow有一个很好的教程在这里,有兴趣的读者可以参考;但我也会在下面粘贴一些非常基础的代码。如下所示,你可以提示模型识别在对象检测数据集中很少甚至从未被标记的对象,比如狗的舌头!
from groundingdino.util.inference import load_model, load_image, predict, annotate
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
# 将图像处理为GroundingDino标准
image_source, image = load_image("dog.jpg")
prompt = "dog tongue, dog"
boxes, logits, phrases = predict(
model=model,
image=image,
caption=prompt,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)

然而,在专业网球场上区分球员并不像简单地提示“网球运动员”那么简单。模型经常错误地识别球场上的其他人员,如司线员、球童和其他裁判,导致跳跃和不一致的标注。此外,模型有时在某些帧中根本无法检测到球员,导致出现间隙和非持久的框,不能可靠地出现在每一帧中。

2、使用卡尔曼滤波区分球员和其他人
为了解决这些问题,我们采用了一些有针对性的方法。首先,我们将检测框限制在所有可能框中的前三个概率最高的框。通常,司线员的概率得分比球员高,这就是为什么我们不只过滤到两个框的原因。然而,这又提出了一个新的问题:如何自动区分每帧中的球员和司线员?
我们观察到,司线员和球童的检测框通常时间跨度较短,往往只持续几帧。基于这一点,我们假设通过跨连续帧关联框,我们可以过滤出只短暂出现的人,从而隔离球员。
那么我们如何实现跨帧对象之间的关联呢?幸运的是,多目标跟踪领域已经广泛研究了这个问题。卡尔曼滤波器是多目标跟踪的主要手段之一,通常与其他识别指标(如颜色)结合使用。对于我们来说,一个基本的卡尔曼滤波器实现就足够了。简而言之(想深入了解,请查看这篇文章这里),卡尔曼滤波器是一种基于先前测量值概率性估计物体位置的方法。它特别适用于处理噪声数据,但在视频中即使检测不一致(例如,球员未在每一帧中被跟踪)时也能很好地关联对象。我们在这里实现了完整的卡尔曼滤波器,但接下来的段落中会介绍其中的一些主要步骤。
二维卡尔曼滤波器状态相当简单,如下所示。我们只需要跟踪x和y位置以及物体在两个方向上的速度(我们忽略加速度)。
class KalmanStateVector2D:
x: float
y: float
vx: float
vy: float
卡尔曼滤波器的操作分为两步:首先预测物体在下一帧的位置,然后根据新的测量值更新这一预测——在我们的例子中,来自物体检测器。然而,在我们的例子中,新帧可能包含多个新对象,甚至可能遗漏前一帧中存在的对象,这就引出了一个问题:我们如何将以前看到的框与当前看到的框关联起来。
我们选择使用马氏距离,结合卡方检验,评估当前检测与过去对象匹配的概率。此外,我们保持一个过去的对象队列,以便我们有比仅一帧更长的‘记忆’。具体来说,我们的记忆存储了过去30帧内任何对象的轨迹。然后,对于我们在新帧中找到的每个对象,我们遍历我们的记忆并找到最有可能与当前对象匹配的先前对象,该匹配概率由马氏距离给出。然而,我们也可能看到了一个全新的对象,在这种情况下,我们应该将新对象添加到我们的记忆中。如果任何对象与我们记忆中的任何框的关联概率小于30%,我们就将其作为新对象添加到我们的记忆中。
我们为那些喜欢代码的人提供完整的卡尔曼滤波器实现。
from dataclasses import dataclass
import numpy as np
from scipy import stats
class KalmanStateVectorNDAdaptiveQ:
states: np.ndarray # 对于二维情况,这些是[x, y, vx, vy]
cov: np.ndarray # 4x4协方差矩阵
def __init__(self, states: np.ndarray) -> None:
self.state_matrix = states
self.q = np.eye(self.state_matrix.shape[0])
self.cov = None
# 假设单步转换
self.f = np.eye(self.state_matrix.shape[0])
# 除以2因为我们有两个状态的速度
index = self.state_matrix.shape[0] // 2
self.f[:index, index:] = np.eye(index)
def initialize_covariance(self, noise_std: float) -> None:
self.cov = np.eye(self.state_matrix.shape[0]) * noise_std**2
def predict_next_state(self, dt: float) -> None:
self.state_matrix = self.f @ self.state_matrix
self.predict_next_covariance(dt)
def predict_next_covariance(self, dt: float) -> None:
self.cov = self.f @ self.cov @ self.f.T + self.q
def __add__(self, other: np.ndarray) -> np.ndarray:
return self.state_matrix + other
def update_q(
self, innovation: np.ndarray, kalman_gain: np.ndarray, alpha: float = 0.98
) -> None:
innovation = innovation.reshape(-1, 1)
self.q = (
alpha * self.q
+ (1 - alpha) * kalman_gain @ innovation @ innovation.T @ kalman_gain.T
)
class KalmanNDTrackerAdaptiveQ:
def __init__(
self,
state: KalmanStateVectorNDAdaptiveQ,
R: float, # R
Q: float, # Q
h: np.ndarray = None,
) -> None:
self.state = state
self.state.initialize_covariance(Q)
self.predicted_state = None
self.previous_states = []
self.h = np.eye(self.state.state_matrix.shape[0]) if h is None else h
self.R = np.eye(self.h.shape[0]) * R**2
self.previous_measurements = []
self.previous_measurements.append(
(self.h @ self.state.state_matrix).reshape(-1, 1)
)
def predict(self, dt: float) -> None:
self.previous_states.append(self.state)
self.state.predict_next_state(dt)
def update_covariance(self, gain: np.ndarray) -> None:
self.state.cov -= gain @ self.h @ self.state.cov
def update(
self, measurement: np.ndarray, dt: float = 1, predict: bool = True
) -> None:
"""测量值将是x, y位置"""
self.previous_measurements.append(measurement)
assert dt == 1, "Only single step transitions are supported due to F matrix"
if predict:
self.predict(dt=dt)
innovation = measurement - self.h @ self.state.state_matrix
gain_invertible = self.h @ self.state.cov @ self.h.T + self.R
gain_inverse = np.linalg.inv(gain_invertible)
gain = self.state.cov @ self.h.T @ gain_inverse
new_state = self.state.state_matrix + gain @ innovation
self.update_covariance(gain)
self.state.update_q(innovation, gain)
self.state.state_matrix = new_state
def compute_mahalanobis_distance(self, measurement: np.ndarray) -> float:
innovation = measurement - self.h @ self.state.state_matrix
return np.sqrt(
innovation.T
@ np.linalg.inv(
self.h @ self.state.cov @ self.h.T + self.R
)
@ innovation
)
def compute_p_value(self, distance: float) -> float:
return 1 - stats.chi2.cdf(distance, df=self.h.shape[0])
def compute_p_value_from_measurement(self, measurement: np.ndarray) -> float:
"""返回测量值与预测状态一致的概率"""
distance = self.compute_mahalanobis_distance(measurement)
return self.compute_p_value(distance)
有了过去30帧内跟踪的每个检测对象,我们现在可以制定启发式方法来确定哪些框最有可能代表我们的球员。我们测试了两种方法:选择靠近底线中心的框,以及选择在记忆中最长观测历史的框。经验表明,第一种策略在实际球员远离底线时常常将司线员误认为球员,使其可靠性降低。同时,我们注意到GroundingDino在不同司线员和球童之间“闪烁”,而真正的球员则保持相对稳定的出现。因此,我们的最终规则是选择记忆中跟踪历史最长的框作为真正的球员。正如你在初始视频中所见,这是一个非常有效的简单规则!
3、利用表面单应性分析球员指标
有了建立在图像上的跟踪系统后,我们可以转向更传统的分析,通过从鸟瞰视角跟踪球员。这种视角使我们能够评估关键指标,如总移动距离、球员速度和球场位置趋势。例如,我们可以根据点球时的位置分析球员是否频繁针对对手的反手。为了实现这一点,我们需要将球员坐标从图像投影到标准化的俯视图球场模板上,以对空间进行分析。
这就是单应性 (homography) 发挥作用的地方。单应性描述了两个表面之间的映射关系,在我们的案例中,这意味着将原始图像上的点映射到俯视图球场上。通过识别原始图像中的几个关键点——如球场上的线交叉点——我们可以计算出一个单应性矩阵,将任何点转换为鸟瞰图。要创建这个单应性矩阵,我们首先需要识别这些‘关键点’。像RoboFlow这样的平台上存在多种开源、许可宽松的模型可以帮助检测这些点,或者我们也可以在参考图像上自行标注这些点以用于变换。

可以看到,预测的关键点并不完美,但小误差对最终变换矩阵的影响不大。
在标注了这些关键点之后,下一步是将它们与参考球场图像上的对应点匹配,生成单应性矩阵。使用OpenCV,我们只需几行简单的代码就可以创建这个变换矩阵!
import numpy as np
import cv2
# 点的顺序很重要
source = np.array(keypoints) # (n, 2)矩阵
target = np.array(court_coords) # (n, 2)矩阵
m, _ = cv2.findHomography(source, target)
有了单应性矩阵,我们可以将图像上的任何点映射到参考球场上。在这个项目中,我们的重点是球员在球场上的位置。为此,我们取每个球员边界框底部的中点,将其作为鸟瞰图中的球员位置。

我们使用框底部的中点来映射球员在球场上的位置。插图显示了使用单应性矩阵将关键点转换到鸟瞰图中的网球场。
4、结束语
总之,本项目展示了我们如何利用GroundingDINO的零样本能力在不需要标注数据的情况下跟踪网球运动员,将复杂的对象检测转化为可操作的球员跟踪。通过解决诸如区分球员和其他场内人员、确保跨帧的持续跟踪以及将球员动作映射到球场的鸟瞰图等关键挑战,我们为构建一个强大的跟踪管道奠定了基础,而无需显式的标签。
这种方法不仅解锁了诸如移动距离、速度和位置等洞察,还打开了更深层次的比赛分析的大门,如击球目标和战略性的球场覆盖。通过进一步的改进,包括从GroundingDINO输出提炼YOLO或RT-DETR模型,我们甚至可以开发出一个实时跟踪系统,其性能可与现有的商业解决方案相媲美,为网球领域的教练和球迷互动提供了一个强大的工具。
原文链接:Zero-Shot Player Tracking in Tennis with Kalman Filtering
汇智网翻译整理,转载请标明出处
